可达图计算目前正在解决的问题
- 目前抑制计算速度提升的因素如下:
- 计算出的可达图数据不能均匀分布在哈希表中,可参考jdk8中hashmap源码
- 结合BDD算法计算可达图时需要的建立带有约束的二元决策树
- 程序编写BDD计算可达图的串行程序。
- 将二元决策树进行分离并优化,简化新增叶子节点过程,减少遍历原决策树的时间
- 将每批的触发结果进行哈希均匀分布,尽量通过布尔计算来压缩比较时间,减少线程分化
- CUDA代码的高效策略,并行化中的压缩与分配
拟定的可达图计算解决方案
方案一:
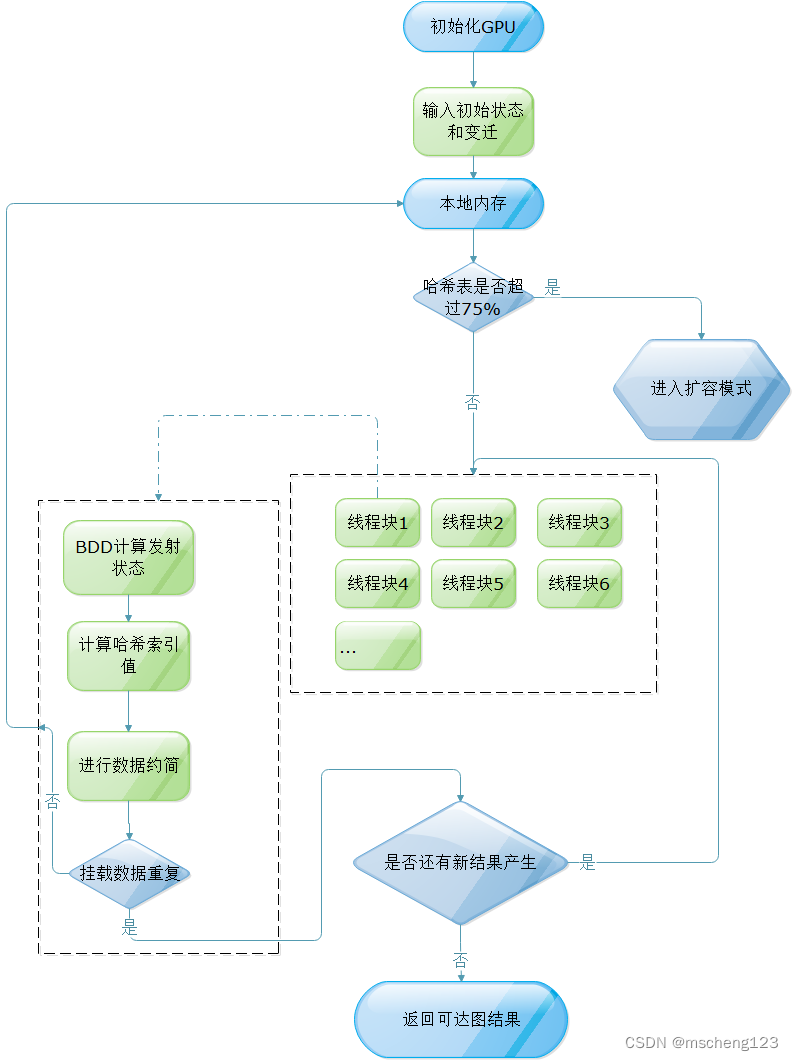
- 初始化GPU本地内存空间,和共享内存空间,设置哈希表的初始容量为4096,block(线程块)初始值也为4096,因此意味着哈希表每个索引值对应一个线程块。
- 将初始状态和变迁的布尔表达式存储在纹理内存中(纹理内存存放常量加快读取速度)
- 将待计算的状态分配给对应SM中,并进行相应计算
- SM中具体进行的操作有:
- 利用BDD的布尔算法得出每个SM中分配的状态在变迁发射后的状态
- 计算每个状态的哈希值和哈希表的索引值
- 将根据状态结果的索引值挂载到对应位置的本地内存中,如果对应位置无值则挂载状态为0
- 本地内存的单位空间采用BDD结构,挂载时与已存在数据进行异或操作,如果结果全为0则不进行数据挂载,如果结果含有1,则将第一个出现1对应的位置作为节点并把数据插入,形成ROBDD(简化有序二叉决策图)。
- 如果挂载点数据异或结果全为0,返回重复状态1
- 判断挂载数是否大于10,如果不大于10,将将BDD的结果分发给各个线程块中的共享内存中,提高SM的读取速度,减少处理时间。
- 当有内存中的挂载数超过了10或者哈希表所占空间超过了75%,SM则停止进行变迁触发,为避免哈希冲突,执行扩容机制,具体扩容机制如下:
- 将读取所有挂载状态不为0的空间,并抽取空间的某一状态计算扩容后的新索引值。
- 将原索引值下的所有数据复制到扩容后的新索引值下。
- 如果所有挂载点在计算后返回值为1,则停止计算,将本地内存数据复制到主机,并统计数据结果,统计可达状态数,完成可达图计算
方案二:
- 修改步骤4.4为:将计算后的状态直接挂载到索引值对应的存储位置,如果挂载数小于3则使用链式结构存储,如果大于等于3则将其用红黑树结构存储
整体运算过程示意图