在多线程场景下,如果对锁资源的处理不当,就可能导致死锁。而当发生死锁时,多数情况也无法实时解决,都是需要重启来解决问题的。所以针对死锁问题,都是以预防为主。
今天推荐一篇来自搜狐视频团队的讲解 Android 死锁的文章,全面了解死锁产生的原因,以及如何预防死锁。
一、什么是死锁
说到死锁,大家可能都不陌生,每次遇到死锁,总会让计算机产生比较严重的后果,比如资源耗尽,界面无响应等。
死锁的精确定义:
集合中的每一个进程(或线程)都在等待只能由本集合中的其他进程(或线程)才能引发的事件,那么该组进程是死锁的。
对于这个定义大家可能有点迷惑,换一种通俗的说法就是:
死锁是指两个或两个以上的线程,在执行过程中,由于竞争资源或者由于彼此通信,而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
经典的「哲学家进餐问题」可以帮助我们形象的理解死锁问题。
有五个哲学家,他们的生活方式是交替地进行思考和进餐,哲学家们共用一张圆桌,分别坐在周围的五张椅子上,在圆桌上有五个碗和五支筷子,平时哲学家进行思考,饥饿时便试图取其左、右最靠近他的筷子,只有在他拿到两支筷子时才能进餐,该哲学家进餐完毕后,放下左右两只筷子又继续思考。
当五个哲学家同时去取他左边的筷子,每人拿到一只筷子且不释放,即五个哲学家只得无限等待下去,这样就产生了死锁的问题。
在计算机中也可以用有向图来描述死锁问题,首先假定每个线程为有向图中的一个节点, 申请锁的线程 A 为起点, 拥有锁的线程 B 为终点,这样就形成线程 A 到线程 B 的一条有向边,而众多的锁 (边) 和线程(点), 就构成了一个有向图。

如果在有向图中形成一条环路,就会产生一个死锁,如上图所示。在很多计算机系统中,检测是否有死锁存在,就是将问题抽象为寻找有向图中的环路。
二、常见的死锁的场景
下面分析几种常见的死锁形式:
2.1 锁顺序死锁
public class TestDeadLock {
private final Object lockA = new Object();
private final Object lockB = new Object();
public void lockAtoB(){
synchronized (lockA){
synchronized (lockB){
doSomething();
}
}
}
public void lockBtoA(){
synchronized (lockB){
synchronized (lockA){
doSomething();
}
}
}
private void doSomething(){
System.out.println("doSomething");
}
}上述代码中,如果一个线程调用 lockAtoB(),另一个线程调用 lockBtoA(),并且两个线程是交替执行,那么在程序运行期间是有一定几率产生死锁。
而产生死锁的原因是:两个线程用不同的顺序去获取两个相同的锁,如果可以始终用相同的顺序,即每个线程都先获取 lockA,然后再获取 lockB,就不会出现循环的加锁依赖,也就不会产生死锁。
当然上面的代码只是一个示例,实际的代码中不会这么简单,而有些函数中,虽然看似都是以相同的顺序加锁,但是由于外部调用的不确定性,仍然会导致实际以不同的顺序加锁而产生死锁。
再看一个例子:
//仓库
public static interface IStore{
public void inCome(int count);
public void outCome(int count);
}
/**
* 从 in 仓库 调用货物去 out仓库
* @param from
* @param to
* @param count 调用货物量
*/
public void transportGoods(IStore from,IStore to,int count){
synchronized (from){
synchronized (to){
from.outCome(count);//出仓库
to.inCome(count);//入仓库
}
}
}货运公司将货物从一个仓库转运到另一个仓库,转运前,需要同时获得两个仓库的锁,以确保两个仓库中的货物数量是以原子方式更新。看起来这个函数都是以相同的顺序获取锁,但这只是函数内部的顺序,而真正的执行顺序,取决于外部传入的对象。
transportGoods(storeA,storeB,100);
transportGoods(storeB,storeA,40);
如果用上述代码调用,在频繁的调用过程中,也很容易产生死锁。从上面的代码中可以看出,需要一个方法来确保在整个程序运行期间,锁都按照事先定义好的顺序来获取。这里提供一种方式:通过比较对象的 hashcode 值,来定义锁的获取顺序。
下面来改造一下上述代码。
private static final Object extraLock = new Object();
/**
* 从 in 仓库 调用货物去 out仓库
* @param from
* @param to
* @param count 调用货物量
*/
public void transportGoods(IStore from,IStore to,int count){
int fromHashCode = System.identityHashCode(from);
int toHashCode = System.identityHashCode(to);
if(fromHashCode > toHashCode){
synchronized (from){
synchronized (to){
transportGoodsInternal(from,to,count);
}
}
}else if(fromHashCode < toHashCode){
synchronized (to){
synchronized (from){
transportGoodsInternal(from,to,count);
}
}
}else {//hash散列冲突,需要用新的一个锁来保证这种低概率情况下不出现问题
synchronized (extraLock){
synchronized (from){
synchronized (to){
transportGoodsInternal(from,to,count);
}
}
}
}
}
public void transportGoodsInternal(IStore from,IStore to,int count){
from.outCome(count);//出仓库
to.inCome(count);//入仓库
}
上述代码不难理解,使用 hashcode 的大小来唯一确定锁的顺序,需要值得注意的是,使用 identityHashCode。
而不是对象自身的 hashCode 方法,这样可以降低用户重写 hashcode 后带来的冲突风险。
当然使用 identityHashCode 也不能完全避免冲突,当 identityHashCode 也冲突的时候,引入了额外的一个锁 extraLock,这个锁是 static 的。也就是说,整个应用程序只有一个,虽然理论上整个程序都使用一个 extraLock 可能会导致并发性能的下降,但是考虑实际情况下,identityHashCode 冲突的可能性非常小,所以并发性能问题也将不是问题。
那么如果能从业务的层面找到 IStore 中唯一的,不可变的编码,例如,仓库在数据库中的唯一编码,就可以不使用 hashcode 了,也可以避免使用 extraLock。当然这需要大家通过实际的业务逻辑来进行分析提取这个唯一编码。
需要注意的是,使用
hashcode这种方式是兼容性最好,成本最低也最不容易出错的方式,如果使用自有编码,你需要确保编码的唯一性,不可变性,这要保证这一点很不容易。
2.2 多个对象协作发生的死锁
之前讨论的死锁发生在一个对象内部,这样的死锁问题,比较明显,也容易发现。当互相调用的类变为两个或者更多,而两个类中又分别有各自加锁同步的逻辑,这样的死锁隐藏在代码逻辑中,不容易发现,也不容易寻找。
首先来看一个例子。
/**
* 玩游戏者
*/
class Player {
private SystemMonitor monitor;
private int cardCount;//收集的卡片的数量
public Player(SystemMonitor monitor) {
this.monitor = monitor;
}
public synchronized int getCardCount() {
return cardCount;
}
public synchronized void collectCard(int count){
cardCount += count;
if(cardCount >= 50){
monitor.notifyComplete(this);
}
}
}
/**
* 监控系统
*/
class SystemMonitor {
private ArrayList<Player> playerArrayList;//所有玩家
private ArrayList<Player> completePlayerArrayList = new ArrayList<>();//完成的玩家
//通知监控系统完成
public synchronized void notifyComplete(Player player){
System.out.println("玩家完成收集");
completePlayerArrayList.add(player);
}
//实时监控大家手中牌的数量
public synchronized void monitorAllPlayer(){
for (Player player : playerArrayList){
System.out.println("玩家有"+ player.getCardCount() + "张牌");
}
}
}Player 代表玩家,玩家收集完成,50 张牌后通知监控系统自己完成游戏,而监控系统通过 monitorAllPlayer() 来实时监控玩家目前手中的牌的数量。
不难理解,在 Player 和 SystemMonitor 的方法中加锁,是为了避免数据的不一致性。粗略看这一段代码时,没有任何方法会显式的获取两个锁。
但是 collectCard() 方法与 monitorAllPlayer() 方法由于调用了外部类的方法,所以他们其实是会拥有两个锁的。假设这样一种情形,当一个玩家收集满 50 张牌,他通知监控系统他已完成收集,玩家先后获取了 Player 对象的锁与 SystemMonitor 对象的锁,而这个时候,监控系统正在扫描所有玩家,而监控系统会先获取自身的锁,然后再获取玩家的锁。
这样就有可能出现在两个线程中获取锁顺序不一致的情况,因此就有可能产生死锁。
当一个对象的方法在持有锁期间调用外部方法,这时应该格外注意,因为无法显式判断外部方法是否有其他锁,而这样就有可能产生死锁。
针对上述描述,该如何避免死锁呢?
首先引入一个术语开放调用,即调用某个方法的时候,不需要持有锁,这种调用称为开放调用。通过尽可能地使用开放调用,更容易找出其他锁的路径,也更容易保证加锁的顺序,以此来避免死锁问题。
上述的代码很容易修改为开放调用,此时需要做的就是缩小锁的粒度,使得同步方法只用来保护真正需要保护的变量或者代码段。
public void collectCard(int count){
boolean isComplete = false;
synchronized (this){
cardCount += count;
if(cardCount >= 50){
isComplete = true;
}
}
if(isComplete){
monitor.notifyComplete(this);
}
}//实时监控大家手中牌的数量
public void monitorAllPlayer(){
ArrayList<Player> copy;
synchronized (this){
copy = new ArrayList<>(playerArrayList);
}
for (Player player : copy){
System.out.println("玩家有"+ player.getCardCount() + "张牌");
}
}2.3 线程饥饿死锁
在线程池中,如果任务依赖于其他任务,就可能产生死锁。举一个简单的单线程 Executor 的例子,如果任务 A 已经在 Executor 中运行,而任务 A 又向相同的 Executor 中提交了一个任务 B,通常情况下,这样会产生死锁。
任务 B 在队列中一直等待任务 A 完成,而任务 A 由于是在单线程 Executor 中,所以又在等待任务 B 执行完成,这样就造成了死锁。在更大的线程池中,考虑极限情况,如果所有正在执行任务的线程,都在等待之前提交到线程池中排队的任务,这样线程会永远等待下去,这种问题称为线程饥饿死锁。
下面的代码展示了线程饥饿死锁。
private ThreadPoolExecutor executor = new ThreadPoolExecutor(5,5,0,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());;
@Test
public void test() throws ExecutionException, InterruptedException {
int count = 0;
while (true) {
System.out.println("开始 = " + (count));
start();
System.out.println("结束 = " + (count++));
Thread.sleep(10);
}
}
public void start() throws ExecutionException, InterruptedException {
Callable<String> second = new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(100);
return "second callable";
}
};
Callable<String> first = new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(10);
Future<String> secondFuture = executor.submit(second);
String secondResult = secondFuture.get();
Thread.sleep(10);
return "first callable. second result = " + secondResult;
}
};
List<Future<String>> futures = new ArrayList<>();
for(int i = 0; i< 5; i++){
System.out.println("submit : " + i);
Future<String> firstFuture = executor.submit(first);
futures.add(firstFuture);
}
for(int i = 0; i < 5; i++){
String firstrResult = futures.get(i).get();
System.out.println(firstrResult + ":" + i);
}
}
三、Android 系统处理死锁方案
Android 系统的 Framework 层有一个 WatchDog 用于定期检测关键系统服务是否发生死锁。WatchDog 功能主要是分析系统核心服务和重要线程是否处于 Blocked 状态。
下面我们以 Android 9.0 为例分析 WatchDog 的实现原理。通过分析源码,也可以给自己实现一套死锁监控提供一些思路。源码见:WatchDog。
看源码之前,可以先自己思考下,如果让我们去实现一个 WatchDog,我们会如何设计。其实原理倒是不难,无外乎需要做两件事情。
-
定期轮询检测系统中核心的线程的状态;
-
检测到卡死后,将相关对应的线程,进程及其他软硬件信息输出;
其实 WatchDog 也是这么设计的。WatchDog 是继承自 Thread,那么我们分析它的工作流程也就从 run() 方法开始吧。
为了方便代码展示,下面源码只保留一些关键代码。run() 方法是整个检测的核心,我在代码片段里面标注了「代码关键点 x」字样,方便在文中引用定位。
public void run() {
boolean waitedHalf = false;
while (true) {//我们要在Android系统运行的整个过程中监控,当然我们需要一个死循环
final List<HandlerChecker> blockedCheckers;
final String subject;
final boolean allowRestart;
int debuggerWasConnected = 0;
synchronized (this) {
long timeout = CHECK_INTERVAL;
//代码关键点1
for (int i=0; i<mHandlerCheckers.size(); i++) {
HandlerChecker hc = mHandlerCheckers.get(i);
hc.scheduleCheckLocked();
}
....
//代码关键点2
long start = SystemClock.uptimeMillis();
while (timeout > 0) {
...
try {
wait(timeout);
} catch (InterruptedException e) {
Log.wtf(TAG, e);
}
...
timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start);
}
...
//代码关键点3
boolean fdLimitTriggered = false;
if (mOpenFdMonitor != null) {
fdLimitTriggered = mOpenFdMonitor.monitor();
}
//代码关键点4
if (!fdLimitTriggered) {
final int waitState = evaluateCheckerCompletionLocked();
if (waitState == COMPLETED) {
waitedHalf = false;
continue;
} else if (waitState == WAITING) {
continue;
} else if (waitState == WAITED_HALF) {
if (!waitedHalf) {
ArrayList<Integer> pids = new ArrayList<Integer>();
pids.add(Process.myPid());
ActivityManagerService.dumpStackTraces(true, pids, null, null,
getInterestingNativePids());
waitedHalf = true;
}
continue;
}
blockedCheckers = getBlockedCheckersLocked();
subject = describeCheckersLocked(blockedCheckers);
} else {
blockedCheckers = Collections.emptyList();
subject = "Open FD high water mark reached";
}
allowRestart = mAllowRestart;
}
//代码关键点5
//代码运行到这里,说明系统已经卡死
final File stack = ActivityManagerService.dumpStackTraces(
!waitedHalf, pids, null, null, getInterestingNativePids());
doSysRq('w');
doSysRq('l');
...
IActivityController controller;
if (controller != null) {
...
int res =controller.systemNotResponding(subject);
if (res >= 0) {
...
continue;
}
}
// 代码关键点6
if (Debug.isDebuggerConnected()) {
debuggerWasConnected = 2;
}
if (debuggerWasConnected >= 2) {
} else if (debuggerWasConnected > 0) {
} else if (!allowRestart) {
} else {//只有这种情况下,杀死system_server
...
//代码关键点6
Process.killProcess(Process.myPid());
System.exit(10);
}
waitedHalf = false;
}
}
整个 run() 方法是一个死循环,这也是可以理解的,毕竟 WatchDog 需要在 Android 系统的整个运行期间进行监测。
在「代码关键点 1」这里,通过遍历所有需要检测的线程,需要检测的线程集合是在 WatchDog 的构造函数中初始化的。
private Watchdog() {
super("watchdog");
...
mMonitorChecker = new HandlerChecker(FgThread.getHandler(),
"foreground thread", DEFAULT_TIMEOUT);
mHandlerCheckers.add(mMonitorChecker);
mHandlerCheckers.add(new HandlerChecker(new Handler(Looper.getMainLooper()),
"main thread", DEFAULT_TIMEOUT));
mHandlerCheckers.add(new HandlerChecker(UiThread.getHandler(),
"ui thread", DEFAULT_TIMEOUT));
mHandlerCheckers.add(new HandlerChecker(IoThread.getHandler(),
"i/o thread", DEFAULT_TIMEOUT));
mHandlerCheckers.add(new HandlerChecker(DisplayThread.getHandler(),
"display thread", DEFAULT_TIMEOUT));
addMonitor(new BinderThreadMonitor());
//这个monitor有额外作用,后面我们会有提到
mOpenFdMonitor = OpenFdMonitor.create();
...
}
WatchDog 构造函数中,初始化了我们要监控的系统线程。包含 FgThread,主线程,UiThread,IoThread,DisplayThread,Binder 通信线程。
需要着重说明的是监控 FgThread 的 mMonitorChecker 通过向外部暴露接口,通过调用 WatchDog 的 addMonitor() 方法,来监控所有实现了 Monitor 接口的服务。
public void addMonitor(Monitor monitor) {
....
mMonitorChecker.addMonitor(monitor);
}代码中的 HandlerChecker 便是今天的主角之一,它的主要作用就是用来检测线程是否卡死。在「代码关键点 1」的循环中,调用了 scheduleCheckLocked(),而这个方法是 HandlerChecker 的核心。
下面 HandlerChecker 代码片段,这个方法通过 postAtFrontOfQueue() 向被监控线程的 Handler 消息队列的头部插入当前 HandlerChecker,如果被监控线程消息执行正常,则会回调 HandlerChecker 的 run() 方法,在 run() 方法里面遍历所有 Monitor 对象(实现 Monitor 接口的服务很多,包含 AMS、WMS、IMS 等),执行 monitor 方法,如果服务正常,最后我们便会将 mCompleted 置为 true。
这个 mCompleted 变量就是后续 WatchDog 用来判断对应线程是否卡死依据。
public final class HandlerChecker implements Runnable {
...
private final Handler mHandler;
private final ArrayList<Monitor> mMonitors = new ArrayList<Monitor>();
private boolean mCompleted;
...
public void scheduleCheckLocked() {
if (mMonitors.size() == 0 && mHandler.getLooper().getQueue().isPolling()) {//特殊的条件,需要注意,下面有解释
mCompleted = true;
return;
}
if (!mCompleted) {
return;
}
mCompleted = false;
mCurrentMonitor = null;
mStartTime = SystemClock.uptimeMillis();
mHandler.postAtFrontOfQueue(this);
}
...
@Override
public void run() {
final int size = mMonitors.size();
for (int i = 0 ; i < size ; i++) {
synchronized (Watchdog.this) {
mCurrentMonitor = mMonitors.get(i);
}
mCurrentMonitor.monitor();
}
synchronized (Watchdog.this) {
mCompleted = true;
mCurrentMonitor = null;
}
}
}scheduleCheckLocked() 方法中有一个代码引起了我们的注意,如果 mHandler.getLooper().getQueue().isPolling() 为 true,那么直接将 mCompleted 置为 true,这又是什么原理?
通过查阅 MessageQueue 源码,里面的一段注释解决了我们的迷惑。
Returns whether this looper's thread is currently polling for more work .This is a good signal that the loop is still alive rather than being stuck handling a callback
这段话含义就是 isPolling 表示正在从队列中取消息,为 true 则代表 Looper 依然运行良好,通过这个标记就不需要等待回调来得知状态,这样效率更高。
了解了检测卡死的原理,那我们继续回到 WatchDog 的 run() 方法,来看「代码关键点 2」。通过 wait() 方法实现了每 30s 检测一次的效果,这里看到了 Google 工程师的一个小技巧,由于 wait() 的 timeout 时间可能没那么准确,为了保证至少等待 30s,使用了一个 while 循环,并且循环完毕通过 timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start); 来保证时间够 30s。
「代码关键点 3」中使用了 OpenFdMonitor,这个类的主要作用是为了判断剩余可用文件句柄的数量,大家知道 Linux 中打开文件都需要分配文件句柄,系统的文件句柄数量是有限制的。
当然这个 OpenFdMonitor 只在编译模式为 userdebug 和 eng 的 Android 编译版本起作用,这也是为了方便开发人员调试信息。
「代码关键点 4」中 evaluateCheckerCompletionLocked() 便是用来评估当前所有线程的卡死情况。
private int evaluateCheckerCompletionLocked() {
int state = COMPLETED;
for (int i=0; i<mHandlerCheckers.size(); i++) {
HandlerChecker hc = mHandlerCheckers.get(i);
state = Math.max(state, hc.getCompletionStateLocked());
}
return state;
}代码获取了当前线程中状态值最大的 state。
state 的定义如下:
-
COMPLETED = 0; 已完成,不存在卡死情况;
-
WAITING = 1; 等待时间小于 DEFAULT_TIMEOUT 的一半,即 < 30s;
-
WAITED_HALF = 2; 等待时间超过 DEFAULT_TIMEOUT 的一半,即 >=30s;
-
OVERDUE = 3; 等待时间大于等于 DEFAULT_TIMEOUT ,即 >=60s;
如果有线程状态已经是 OVERDUE,那么说明被监控的线程有卡死情况。我们的流程也来到了「代码关键点 5」。这里就比较好理解了,通过 dumpStackTraces 输出 kernel 栈信息,通过 doSysRq 触发系统 dump 所有阻塞线程堆栈。这样所有相关的信息就保存好了。
「代码关键点 6」中,以下几种情况,即使触发了 WatchDog,也不杀死系统进程。
-
debuggerWasConnected>=0 debuggerWasConnected>=2 代表 debugger 正在连接调试中
-
allowRestart 设置为 true,是通过 adb logcat am hang 命令设置的
最后通过下面两行代码将 SystemServer 进程杀死,当 system_server 被杀后,就会导致 Zygote 进程自杀,进而做到 Zygote 进程的重启。而这个现象也就是我们平常看到了手机死机了,然后又自动重启的现象。
Process.killProcess(Process.myPid());
System.exit(10); 四、Android 开发过程中死锁分析方法
分析完系统如何处理死锁情况后,我们再来看看在 Android 开发中最容易碰到的死锁表现形式 ANR。
当然产生 ANR 的原因很多,死锁只是其中一种。如果 ANR 发生,对应的应用会收到 SIGQUIT 异常终止信号,dalvik 虚拟机就会自动在 /data/anr/ 目录下生成 trace.txt(Android8.1 以后文件名不是这个了)文件,这个文件记录了在发生 ANR 时刻系统各个线程的执行状态,trace 文件中记录的线程执行状态详细描述了各个线程加锁等待的情况。
通过分析,就可以相对容易的找到发生死锁所在的线程及代码。
主线程死锁导致的问题,可以通过 ANR 的 trace 文件分析,如果是非主线程呢,这种死锁一般很难察觉,但是这种死锁有时候也会造成很严重的后果,因为线程可能一直在占用某些资源,比如端口,数据库连接,文件句柄等。对于普通的 java 程序,JVM 提供了 jstack 工具,可以将线程信息 dump 出来进行分析。
由于 Android 系统中没有提供类似 jstack 的工具,
这里笔者给大家提供两种方法来检查是否有线程发生死锁。
4.1 借助 Android Studio 的调试工具
首先通过工具栏 Run -> Attach to Process。

或者快捷入口,将 App 的进程 attach 进去。
然后在 Android Debugger 窗口中,找到 Get Thread Dump 按钮,点击后,稍等片刻,Androd Studio 就会将对应调试进程的线程堆栈信息 dump 出来。
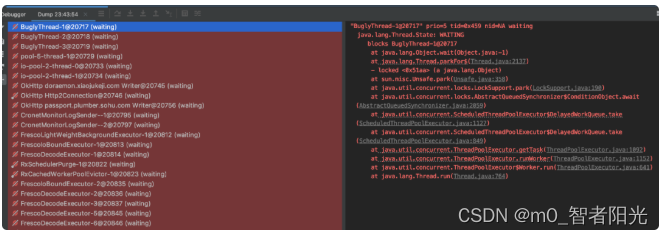
下图就是得到的线程信息,这样就可以分析线程中的死锁了。
4.2 借助 ANR 机制
Android 应用发生 ANR 时,系统会发出 SIGQUIT 信号给发生 ANR 的进程。利用系统这个机制,当监控线程发现被监控线程卡死时,主动向系统发送 SIGQUIT 信号,等待 /data/anr/traces.txt 文件生成。这样可以得到一个和 ANR 日志相同的线程堆栈信息,这样分析死锁的问题就和之前分析 ANR 那个 trace 文件就一样了。
下面我举一个具体例子来看看如何借助发送 SIGQUIT 信号来生成 trace 文件。
首先我们通过 ps 命令拿到我们进程的进程 id。
adb shell ps | grep com.sohu.sohuvideo

这取主进程 id:22841,执行如下命令。
adb shell run-as com.sohu.sohuvideo kill -3 22841紧接着会在 logcat 中输出日志 com.sohu.sohuvideo I/.sohu.sohuvide: Wrote stack traces to '[tombstoned]',这时我们的 trace 文件便已经生成好了(这里需要注意 Android8.1 之前输出的日志为 Wrote stack traces to traces.txt)。
在这里我们需要注意,run-as 命令需要在 debug 包下面才管用,如果是 Release 包则不行。
如果是 Android8.1 之前的系统那么我们就可以愉快的通过 adb pull /data/anr/traces.txt 命令直接将文件拿到了,但是 8.1 之后 trace 文件便没有权限直接可以拿到了。
这里我们可能想到了用 adb shell bugreport 命令来导出 trace 文件,但是当我们兴奋的打开 bugreport 文件,找到 ANR 文件夹,却发现里面只有 App 真正发生 ANR 时候的 trace 文件,却没有我们刚刚用命令执行完毕后生成的文件。
通过 adb shell 直接进入手机目录查看发现,该目录下有我们刚刚生成的文件 dumptrace_YbVvLP,只不过 bugreport 没有将其导出。
![]()
最后经过一番探索终于找到一个途径,这样绕过了系统的权限,终于将我们自己生产的 trace 文件导出了。
adb shell cat /data/anr/dumptrace_YbVvLP > ~/Desktop/dump结束语
死锁问题是一个老大难问题,而且只要有死锁,一般都会引起严重的后果,我们需要不断强化自己的编程能力,写代码的过程中遇到多线程加锁同步的问题,多思考是否会产生死锁,只有多思考,多实践,才能将死锁问题发生的频率降到最低。