coco数据集的评价指标的计算还是比较复杂的,代码写的也比较凝炼,最近要计算目标检测的混淆矩阵,我看mmdet的计算方式比较奇怪,本着P和R等计算方法要与coco官方对齐的目的,特地写此笔记对coco官方的计算方式进行深入理解。
其他相关优秀笔记:
COCO API-深入解析cocoeval在det中的应用
coco计算不同map有很多变量:iou阈值,目标的面积范围,最大检测框数量等。
coco首先使用cocoEval.evaluate() 函数进行匹配计算,然后使用cocoEval.accumulate()函数进行结果的累加
cocoEval.evaluate()
这个函数前面都是一些比较好理解的准备工作,传入参数,计算每张图,每一类中,gt和det两两之间的iou矩阵,存储在self.iou这个字典中,
字典有len(imgId)*len(catId)个key。然后就是调用evaluateImg这个函数了。
self.evalImgs = [evaluateImg(imgId, catId, areaRng, maxDet)
for catId in catIds
for areaRng in p.areaRng
for imgId in p.imgIds
]
根据这个调用方式,以及该函数的return我们可以确定 self.evalImgs是一个长度为len(catId)*len(areaRng)*len(imgId)的列表,其每个元素是一个字典,包含det和gt的匹配信息。
接下来我们再看这个关键的evaluateImg函数
def evaluateImg(self, imgId, catId, aRng, maxDet):
'''
perform evaluation for single category and image
:return: dict (single image results)
'''
该函数是为了在特定限制下对单幅图某一类的检测结果进行评估,传入了四个参数:
- imgId, 表示当前所处理图片的ID
- catId,表示当前处理的类别ID
- aRng,表示当前的面积范围,这是为了方便评估s,m,l三种尺度目标的检测效果
- maxDet,最大检测框数量限制
- 函数首先在所有框中挑出imgId, catId的gt框和det框,并根据面积范围的限制设置该gt框是否应该ignore,并把满足面积范围的gt框排在前面,把score更高的det框也排在前面,还设置了该gt框的iscrowd标签,最后从self.ious中挑出imgId, catId的ious矩阵,注意这个最后的ious阵也是根据是否满足面积范围排序了
self.ious是有n*c个key的字典,n代表图片总数,c代表数据的类别数,每个key所对应value是一个二维矩阵,每一列代表某个gt框与所有det框的交并比。这个字典是之前已经计算好的。该部分代码如下:
p = self.params
if p.useCats:
gt = self._gts[imgId,catId]
dt = self._dts[imgId,catId]
else:
gt = [_ for cId in p.catIds for _ in self._gts[imgId,cId]]
dt = [_ for cId in p.catIds for _ in self._dts[imgId,cId]]
if len(gt) == 0 and len(dt) ==0:
return None
for g in gt:
if g['ignore'] or (g['area']<aRng[0] or g['area']>aRng[1]):
g['_ignore'] = 1
else:
g['_ignore'] = 0
# sort dt highest score first, sort gt ignore last
gtind = np.argsort([g['_ignore'] for g in gt], kind='mergesort')
gt = [gt[i] for i in gtind]
dtind = np.argsort([-d['score'] for d in dt], kind='mergesort')
dt = [dt[i] for i in dtind[0:maxDet]]
iscrowd = [int(o['iscrowd']) for o in gt]
# load computed ious
ious = self.ious[imgId, catId][:, gtind] if len(self.ious[imgId, catId]) > 0 else self.ious[imgId, catId]
- 接下来是一个三重嵌套的循环,首先是0.5:0.95的iou阈值循环,然后是每个det框的循环,最后是每个gt框的循环。
代码及自己的注释:
T = len(p.iouThrs)
G = len(gt)
D = len(dt)
gtm = np.zeros((T,G))
dtm = np.zeros((T,D))
gtIg = np.array([g['_ignore'] for g in gt])
dtIg = np.zeros((T,D)) # 默认det框都不被ignore
if not len(ious)==0:
for tind, t in enumerate(p.iouThrs):
for dind, d in enumerate(dt): # 优先给score更高的det框匹配gt框
# information about best match so far (m=-1 -> unmatched)
iou = min([t,1-1e-10])
m = -1
for gind, g in enumerate(gt):
# if this gt already matched, and not a crowd, continue,
'''意思一种iou阈值下一个gt只匹配到一个det框'''
if gtm[tind,gind]>0 and not iscrowd[gind]:
continue
# if dt matched to reg gt, and on ignore gt, stop,
'''
意思该detbox已有匹配且gt满足面积范围,
当前gt不满足面积范围则跳出gt的循环。因为gt是排序过的,
这说明在面积范围的gt都被遍历过了,当前匹配的肯定也是
iou最高的处于面积范围内的gt框,直接打断循环即可
'''
if m>-1 and gtIg[m]==0 and gtIg[gind]==1:
break
# continue to next gt unless better match made,
'''意思已有匹配的iou是否小于当前匹配的iou,小于就跳过该gt'''
if ious[dind,gind] < iou:
continue
# if match successful and best so far, store appropriately,
iou=ious[dind,gind]
m=gind
'''
对该gt框的循环做一总结:
在当前iou阈值下还没被匹配的gt框中
1. det框会匹配在面积范围内且iou最高的gt框
2. 若面积范围内的gt框没有超过当前iou阈值的,那么det框匹配在面积范围外且iou最高的gt框
'''
# if match made store id of match for both dt and gt
'''若当前det框与这些gt框的iou都没超过阈值,那就没有匹配,跳过该det框'''
if m ==-1:
continue
dtIg[tind,dind] = gtIg[m] #当前所匹配的gt是否在面积范围内
dtm[tind,dind] = gt[m]['id'] # 当前det匹配的gt id
gtm[tind,m] = d['id'] # 当前gt匹配的 det 的 id
- 最后找出不在面积范围内的且没匹配成功的det框,将其设置为ignore,这个对不同尺度目标检测的评价结果有影响。最终返回该张图该类的匹配结果。代码:
# set unmatched detections outside of area range to ignore
a = np.array([d['area']<aRng[0] or d['area']>aRng[1] for d in dt]).reshape((1, len(dt)))
dtIg = np.logical_or(dtIg, np.logical_and(dtm==0, np.repeat(a,T,0)))
# store results for given image and category
return {
'image_id': imgId,
'category_id': catId,
'aRng': aRng,
'maxDet': maxDet,
'dtIds': [d['id'] for d in dt],
'gtIds': [g['id'] for g in gt],
'dtMatches': dtm,
'gtMatches': gtm,
'dtScores': [d['score'] for d in dt],
'gtIgnore': gtIg,
'dtIgnore': dtIg,
}
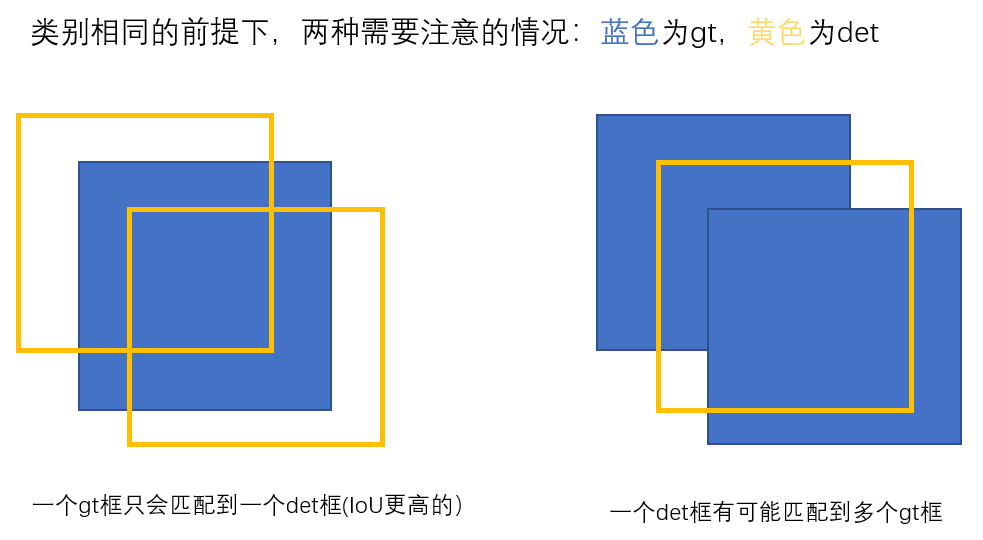
上图是coco中对两中比较特别的情况的判断方法。coco是将每一类当成二分类进行匹配的,其他类也算作background。
而在mmdet的计算混淆矩阵的方法中,并不是把每一类的gt和det拎出来再匹配,而且也没有去除重复的操作,即左边这种情况下,只要iou超过阈值,一个gt会和这两个det都匹配,导致最终的tp值大于了真实的gt数,如果gt和det类别不相同,也就增加了其他类的fp值。在右边的情况中也是没有去除重复,同样会增加两个tp,若类别不相同,那会增加其他类的fp。
cocoEval.accumulate()
cocoEval.evaluate() 只是每幅图的det和gt做了匹配,并将结果存在了self.evalImgs中。计算tp等指标需要cocoEval.accumulate()。
- 准备工作,传入参数
def accumulate(self, p = None):
'''
Accumulate per image evaluation results and store the result in self.eval
:param p: input params for evaluation
:return: None
'''
print('Accumulating evaluation results...')
tic = time.time()
if not self.evalImgs:
print('Please run evaluate() first')
# allows input customized parameters
if p is None:
p = self.params
p.catIds = p.catIds if p.useCats == 1 else [-1]
T = len(p.iouThrs) # IoU阈值的数量
R = len(p.recThrs) # score阈值的数量
K = len(p.catIds) if p.useCats else 1 # 类别数量
A = len(p.areaRng)
M = len(p.maxDets)
precision = -np.ones((T,R,K,A,M)) # -1 for the precision of absent categories
recall = -np.ones((T,K,A,M))
scores = -np.ones((T,R,K,A,M))
'''precision,recall,scores这三个张量的形状为什么设置成这样,不太能完全理解'''
# create dictionary for future indexing
_pe = self._paramsEval
catIds = _pe.catIds if _pe.useCats else [-1]
setK = set(catIds)
setA = set(map(tuple, _pe.areaRng))
setM = set(_pe.maxDets)
setI = set(_pe.imgIds)
'''全都转换成集合了'''
# get inds to evaluate
k_list = [n for n, k in enumerate(p.catIds) if k in setK]
m_list = [m for n, m in enumerate(p.maxDets) if m in setM]
a_list = [n for n, a in enumerate(map(lambda x: tuple(x), p.areaRng)) if a in setA]
i_list = [n for n, i in enumerate(p.imgIds) if i in setI]
I0 = len(_pe.imgIds)
A0 = len(_pe.areaRng)
# retrieve E at each category, area range, and max number of detections
未完待续。。。