论文提出了一种可伸缩自我注意(Scalable Self-Attention, SSA)机制,该机制利用两个可伸缩因子来释放查询、键和值矩阵的维度,同时解除它们与输入的绑定。此外,还提出了一种基于交互式窗口的自我注意(IWSA),通过重新合并独立的值标记和聚集相邻窗口的空间信息来建立非重叠区域之间的交互。通过交替叠加SSA和IWSA,Scalable Vision Transformer (ScalableViT)在通用视觉任务上实现了优于SOTA的性能。

论文:https://arxiv.org/abs/2203.10790
代码(已开源):https://github.com/yangr116/scalablevit
创新思路
近年来,卷积神经网络(cnn)在计算机视觉领域占据主导地位,这归功于其建模逼真图像的能力,从局部感知到全局感知。虽然它们已被广泛应用于各种视觉任务,但在整体视觉感知方面仍存在不足。transformer 的全局感知需要一个昂贵的计算,因为自我关注是在整个序列上的二次计算。为了减轻这种开销,典型的Swin Transformer 采用了基于windows的Self-Attention (WSA),它将特征映射划分为许多不重叠的子区域,并使其能够处理线性复杂度的大规模图像。还提出了一种新颖的基于移动窗口的自我注意(SWSA),以弥补潜在的长期依赖的损失。为了深入了解WSA,本文在第二个块之后可视化特征图。如图1所示,WSA捕捉到的特征是分散的,其响应倾向于局部,而不是面向对象。

图1:Vision Transformer中特征图的可视化
由于总是固定的维数,导致学习能力有限,因此模型的最终性能在很大程度上取决于输入数据的难度。
为了缓解这一问题,作者提出了一种新的自我注意机制,称为可伸缩自我注意(Scalable self-attention, SSA),它同时在空间和通道维度引入两个尺度因子(rn和rc)。
在图1的第三行中,可以观察到,空间的可扩展性可以为对象带来几乎连续的可视化建模,但仍然丢失了一些上下文线索。
因此,作者扩展通道维度来学习更图形化的表示。如图1最后一行所示,通过通道可扩展性,SSA在保持面向上下文泛化的同时,成功地获得了完整的对象激活。
此外,还提出了一个基于窗口的交互式自注意(IWSA),它由一个常规WSA和一个本地交互模块(LIM)组成。IWSA通过重新合并独立的值标记和聚合相邻窗口的空间信息来建立信息连接。
这种特性增强了期望的全局接收域,并充分利用了transformer在单一层中的最显著优势。
为了实现更高效的通用视觉任务骨干,本文采用分层设计,并提出了一种新的vision Transformer架构,称为Scalable ViT,它在每个阶段交替排列IWSA和SSA块。
本文的主要贡献
对于全局自我注意,提出了SSA在vanilla自我注意块中提供面向上下文的泛化,这在不牺牲上下文表达的情况下显著减少了计算开销•对于局部自我注意,设计了LIM来增强WSA的全局感知能力
方法
总体架构
ScalableViT的总体架构如图2所示。在每个阶段,设计了一种交替排列的IW-MSA和S-MSA块来组织拓扑结构。在每个阶段的前端,在两个Transformer块之间插入一个位置编码生成器(PEG),动态生成位置嵌入。
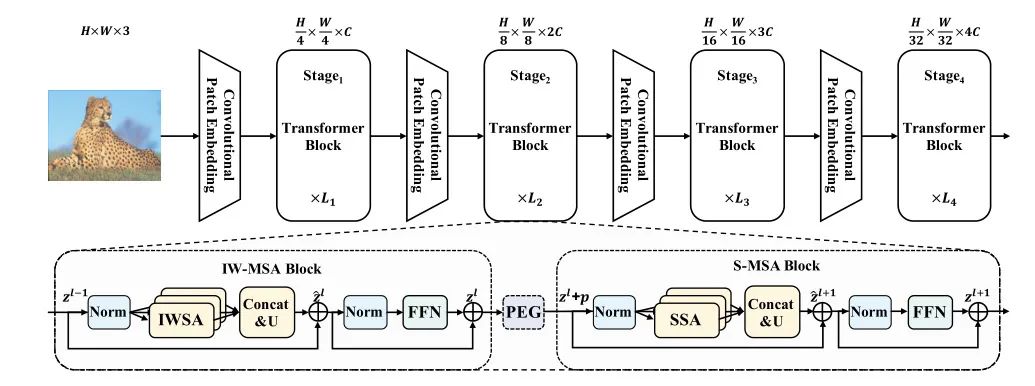
图2:ScalableViT的架构
Scalable Self-Attention
自我注意(Self-Attention)是Transformer中的一种关键机制,普通的自我注意(vanilla Self-Attention)可以计算为:

在Vision Transformer中,并不是所有的信息都是计算自我注意所必需的。因此,作者开发了可伸缩的自我注意(SSA),其中两个缩放因子(rn和rc)分别引入到空间和通道维度,产生了比普通的一个更有效的中间计算。如图3所示。
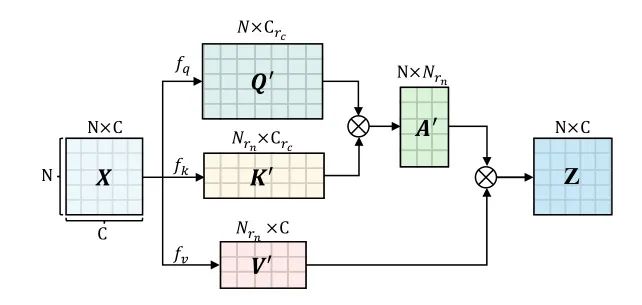
图3:SSA示意图
这些比例因子还可以恢复输出维度与输入对齐,使后续的FFN层和剩余连接可行。因此,中间维度更有弹性,不再与输入x深度绑定。
模型可以获得面向上下文的泛化,同时显著减少计算开销。SSA可以写成:

基于交互式windows的自我注意
除了高效的自我注意,早期的研究还发展了局部自我注意,以避免token数量的二次元计算复杂度。例如,WSA将一个图像(H×W ×C)划分为多个包含M × M标记的部分窗口。然后在每个孤立窗口计算自我注意,产生一组离散输出{Zn} H M × W Mn=1,其中Zn的计算公式为:

一个离散的{Zn} H M × W Mn=1集合被合并回Z∈RN×C。
WSA的线性复杂度,它可以适用于各种需要高分辨率输入的视觉任务,但这种计算效率高的WSA产生了一个具有完整形状但孤立激活的特征图(见图1),这归因于在单一层中错过了全局感受野。
为了缓解上述问题,本文提出了基于交互式windows的自我注意(IWSA),该IWSA将一个本地交互模块(LIM)整合到WSA中,如图4所示。
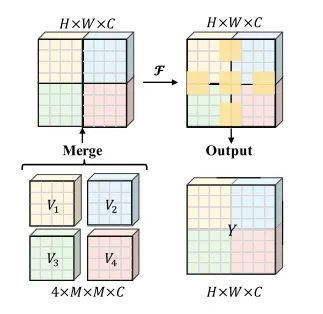
图4:LIM示意图
输出的Y = F(V)是一个包含全局信息的综合特征图,这个特征图被添加到Z上作为最终输出Z '。在不丧失一般性的前提下,IWSA的计算公式为:

位置编码
除了LIM引入的位置信息外,作者还利用由固定权值的卷积层组成的位置编码生成器(PEG)来获取隐式的位置信息。如图2所示,它被插在两个连续的Transformer块之间,每个级的前面只有一个。在PEG之后,输入的tokens被发送到随后的块,位置偏差可以使Transformer实现输入排列。
实验
表2报告了ImageNet-1K上的分类结果,其中根据计算复杂度(FLOPs),所有模型被分为小(约4G)、基本(约9G)和大(约15G)级别。
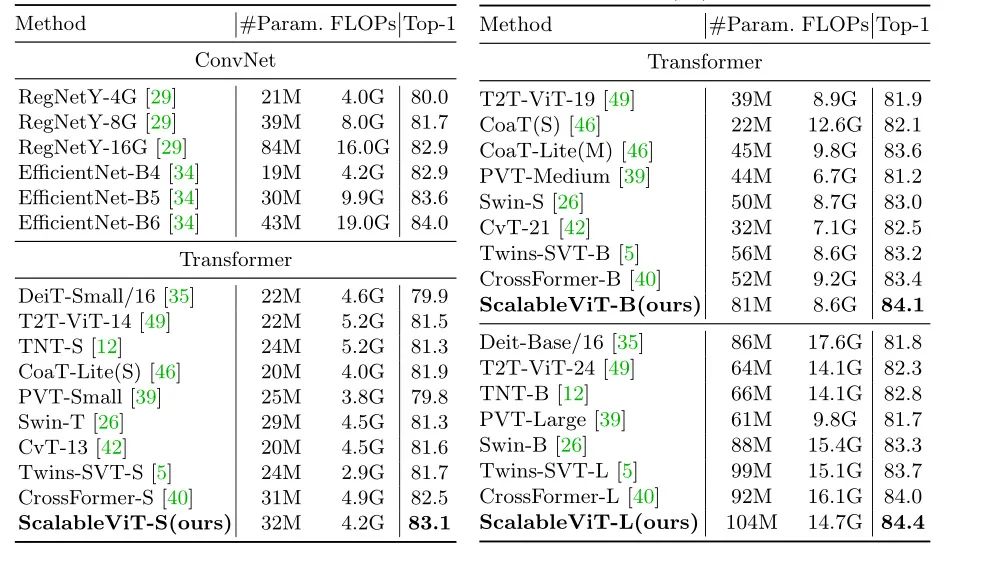
表2:在ImageNet-1K分类上与不同backbones的比较
在表3中给出了RetinaNet和Mask R-CNN框架的结果,其中APb和APm分别表示box mAP和Mask mAP。

表3:RetinaNet和Mask R-CNN框架检测COCO对象的结果图5给出了基于scalablevits -based的RetinaNet和Mask R-CNN的一些定性对象检测和实例分割结果,从backbones的上下文表示可以使模型更好地检测对象。

图5基于scalablevits的定性结果

表4:Semantic FPN和UperNet框架对ADE20K分割的结果

表5:scalablevits对不同自我注意机制和LIM的消融实验。在表5b中检验LIM的有效性。以无位置编码生成器(PEG)、局部增强模块(LEM)或LIM的scalablevits为基准模型,在ImageNet上达到82.7%的top-1精度。
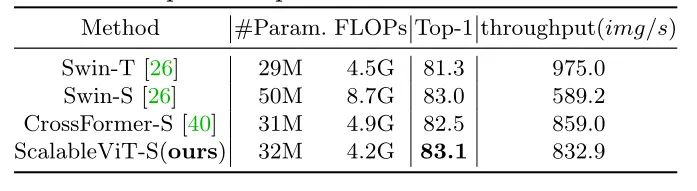
表6:与最先进的模型的速度比较
结论
论文提出了一个Vision Transformer,名为ScalableViT,由两种高效的自我注意机制(SSA和IWSA)组成。它在空间和通道两个维度上采用协同比例因子进行情境化泛化,维护更多的情境线索并学习图形表示。
WSA开发了一个本地交互模块,用于在独立窗口之间建立信息连接。它们都具有在单个层中建模远程依赖关系的能力。ScalableViT交替使用这两个自我注意模块,推动整个框架进入一个更有效的权衡状态,并在各种视觉任务上达到SOTA的性能