PyTorch进阶训练技巧
1、使用Carvana数据集训练U-Net
首先在官网下载Carvana数据集,地址:Carvana Image Masking Challenge | Kaggle

下载完成后解压到项目文件夹下
导包
import os
import PIL
import torch.nn as nn
from torch import optim
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
import matplotlib.pyplot as plt
import torch.nn.functional as F
from sklearn.model_selection import train_test_split读取数据集:
os.environ['CUDA_VISIBLE_DEVICES']='2,3'
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir + "train")
self.masks = os.listdir(base_dir + "train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4] + "_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode == "train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask != 0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./"
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir + "train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
# train_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=True)
# val_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=False)
train_loader = DataLoader(train_data, batch_size=6, shuffle=True)
val_loader = DataLoader(train_data, batch_size=6, shuffle=False)示例:
image,mask = next(iter(train_loader))
plt.subplot(121)
plt.imshow(image[0,0])
plt.subplot(122)
plt.imshow(mask[0,0],cmap="gray")
plt.show()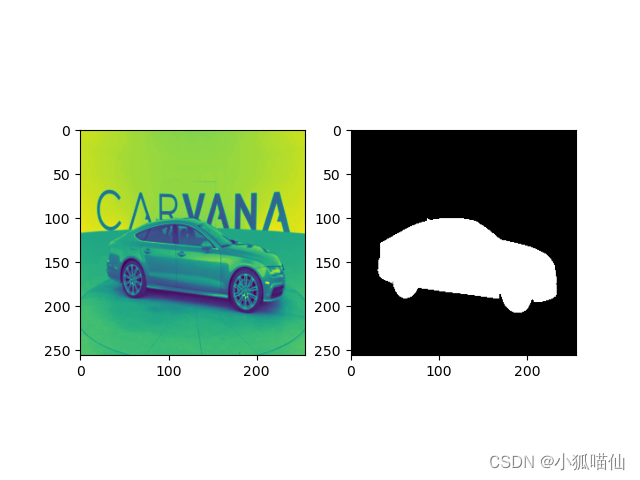
这里遇到两个问题:
1、RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase.……
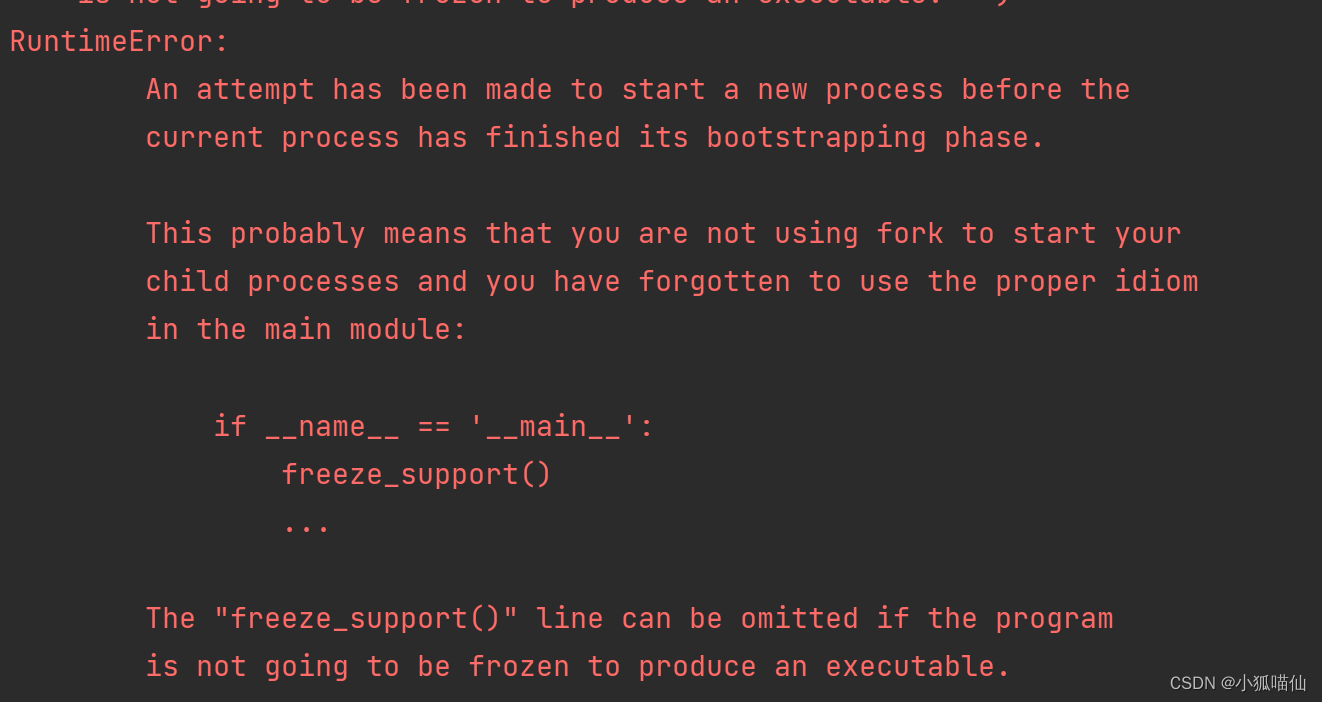
解决方法:看到(1条消息) pytorch使用出现"RuntimeError: An attempt has been made to start a new process before the..." 解决方法_MaloFleur的博客-CSDN博客提到多线程缘故,将num_workers注释掉
2、图像不显示问题:
根据【Q&S】plt.imshow不显示图片也不报错_CharlieRiccardo的博客-CSDN博客 (baidu.com)在图像显示代码块最后加plt.show(),问题解决
image,mask = next(iter(train_loader))
plt.subplot(121)
plt.imshow(image[0,0])
plt.subplot(122)
plt.imshow(mask[0,0],cmap="gray")
plt.show()#添加此行2、自定义损失函数
2.1、以函数方式定义
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss2.2、以类方式定义
根据函数定义式
eg:Dice Loss
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets)criterion=nn.BCEWithLogitsLoss()
optimizer=optim.Adam(unet.parameters(),lr=1e-3,weight_decay=1e-8)
unet=nn.DataParallel(unet).cpu()
#分割模型,用来评价分割好坏的指标
def dice_coeff(pred, target):
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train(epoch):
unet.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cpu(), mask.cpu()
optimizer.zero_grad()
output = unet(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
#学习率
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
output = unet(data)
loss = criterion(output, mask)
val_loss += loss.item() * data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu()) * data.size(0)
val_loss = val_loss / len(val_loader.dataset)
dice_score = dice_score / len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
#继承nn.muduel形式定义
class DiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = torch.sigmoid(inputs)
#向量拉平
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2. * intersection + smooth) / (inputs.sum() + targets.sum() + smooth)
return 1 - dice
#调用
newcriterion = DiceLoss()
unet.eval()
image, mask = next(iter(val_loader))
out_unet = unet(image.cpu())
loss = newcriterion(out_unet, mask.cpu())
print(loss)下面这条命令可以用于查看gpu占用情况
!nvidia-smi3、动态调整学习率
寻找一个适当的学习率衰减策略,提高训练精度。降低优化速度,满足优化需求
torch.optim.lr_scheduler封装好的一些动态调整学习率的方法:CSDN编程社区


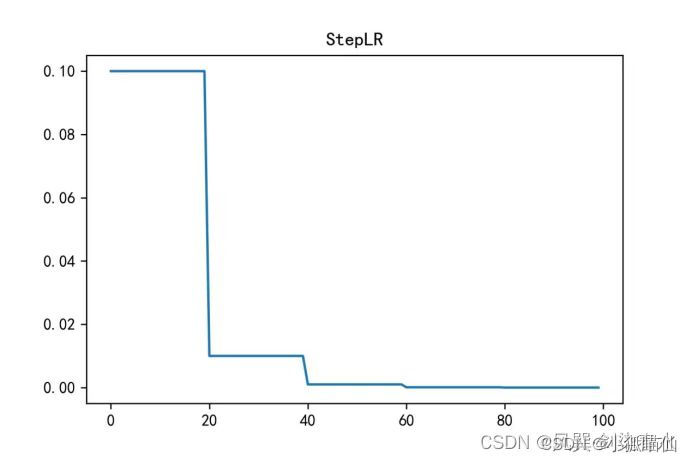

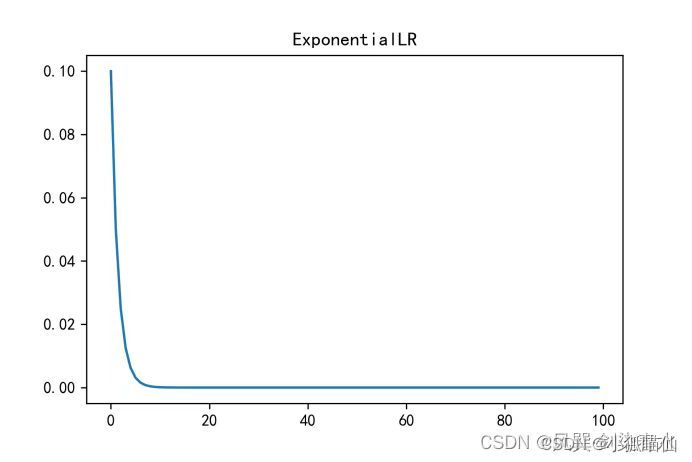


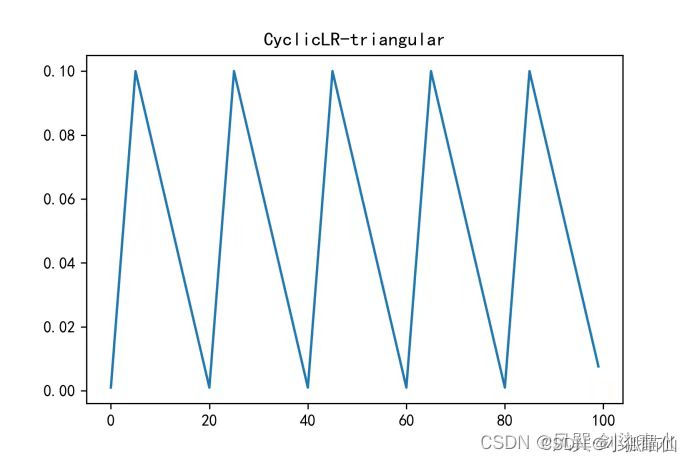

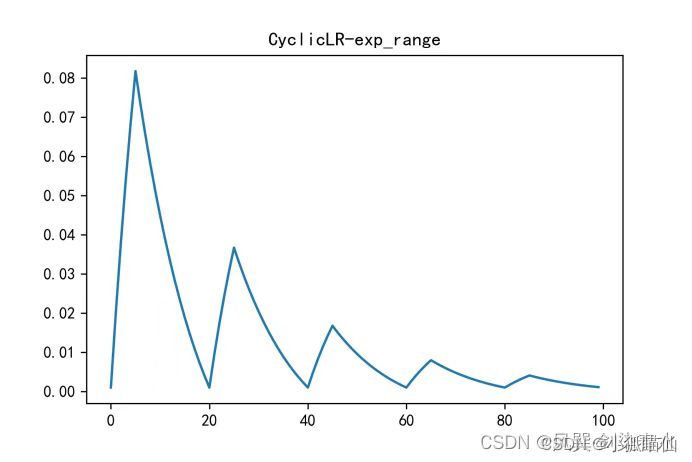
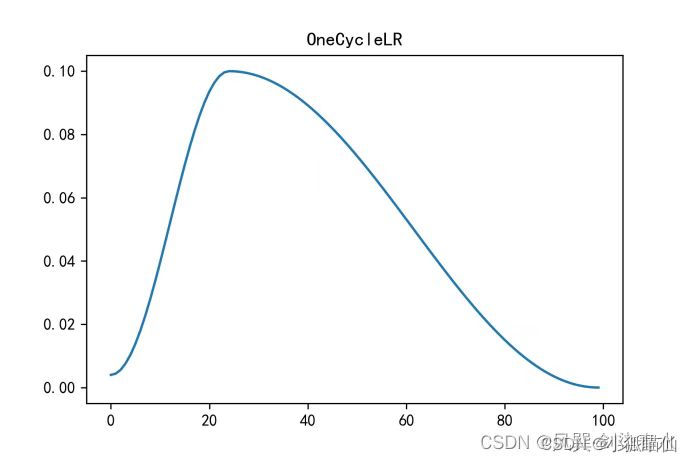


自定义scheduler
scheduler=optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.8)
#每隔1步,学习率变为原来的0.8
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
scheduler.step()4、模型微调
流程:
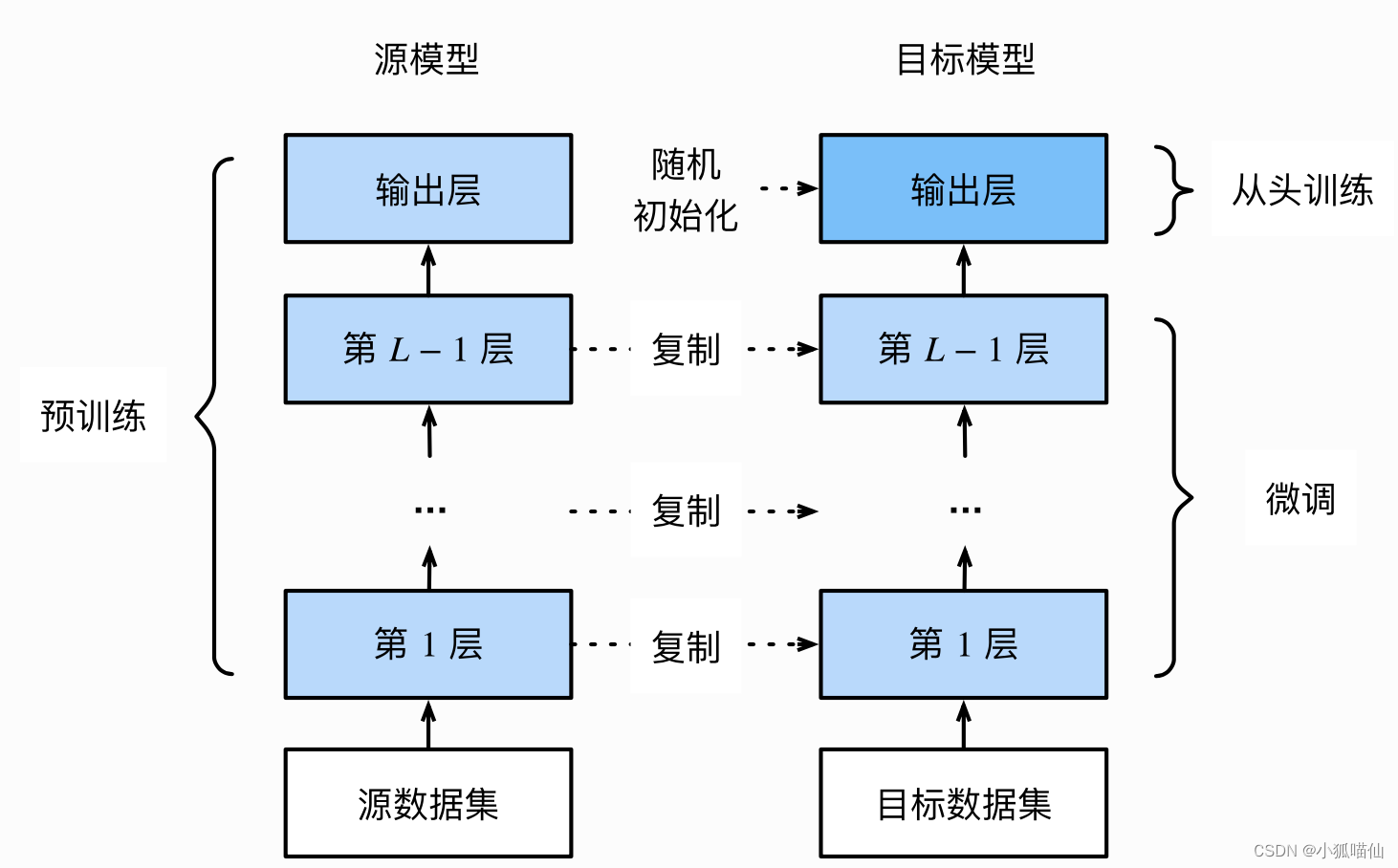
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
创建一个新的神经网络模型,即目标模型。
为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数。
在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
5、使用已有模型结构
eg:
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()通过True或者False来决定是否使用预训练好的权重:
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)我们可以通过使用 torch.utils.model_zoo.load_url()设置权重的下载地址。
可以将自己的权重下载下来放到同文件夹下:
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))除了使用
torchvision.models进行预训练以外,还有一个常见的预训练模型库,叫做timm,这个库是由来自加拿大温哥华Ross Wightman创建的。里面提供了许多计算机视觉的SOTA模型,可以当作是torchvision的扩充版本,并且里面的模型在准确度上也较高。
6、训练特定层
一般情况:.requires_grad = True
若我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置requires_grad = False来冻结部分层
eg:
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False7、半精度训练
寻找一个适当的学习率衰减策略,提高训练精度
在PyTorch中使用autocast配置半精度训练,设置位置如下:
-
import autocast
from torch.cuda.amp import autocast
-
模型设置(在train和val代码forward前加@autocast() )
@autocast() def forward(self, x): ... return x
-
训练过程加
with autocast():for x in train_loader: x = x.cuda() with autocast(): output = model(x) ...
代码示例:
class UNet_half(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet_half, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
@autocast()
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logitsunet_half = UNet_half(3,1)
unet_half = nn.DataParallel(unet_half).cuda()def dice_coeff(pred, target) :
eps=0.0001
num = pred.size(0)
m1 = pred.view(num, -1)
m2 = target.view(num, -1)
intersection = (m1 * m2).sum( )
return (2.*intersection + eps) / (m1.sum() + m2.sum() + eps )
def train_half(epoch) :
unet.train( )
train_1oss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda( )
with autocast(): #修改了这里
optimizer.zero_grad( )
output = unet(data)
loss = criterion (output ,mask)
loss.backward( )
optimizer.step( )
train_1oss += loss.item()*data.size(0)
train_loss = train_1oss/len(train_loader.dataset)
print( 'Epoch:{} \tTraining Loss: {: .6f}' . format(epoch, train_loss))
def val_half(epoch):
print( "current learning rate:" , optimizer.state_dict()["param_groups"][0]["lr"])
unet.eval()
val_loss=0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda( )
with autocast(): #修改了这里
output = unet(data)
loss = criterion (output, mask)
val_loss += loss.item( ) *data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu() )*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print( 'Epoch: {} \t Validation Loss: {:.6f}, Dice score: {: .6f}' .format(epoch, val_loss, dice_score))