一、登录模块
1.Session存在共享问题
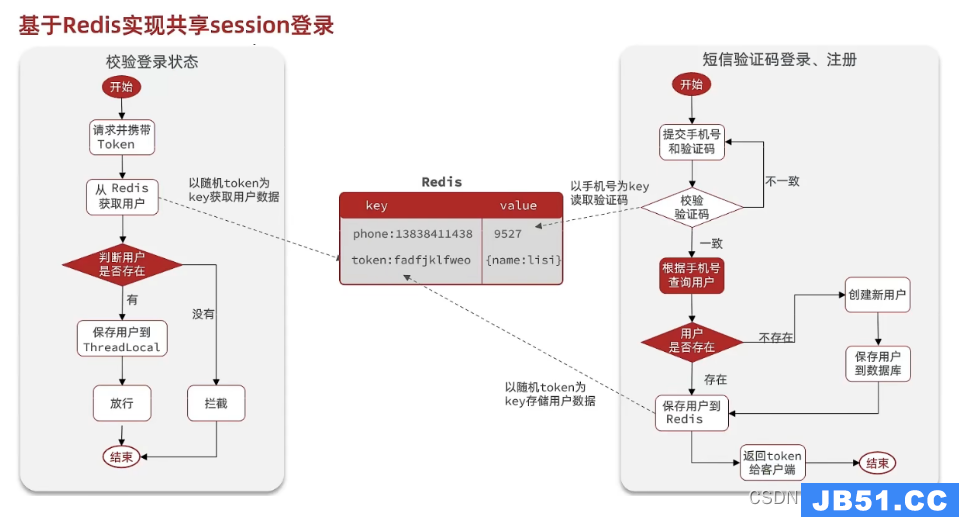
2. redis
因此选择用redis,数据结构:
手机号:验证码code
随机码为token:用户信息(保存为一个Map<String,Object>对象,具体为key与value)
3.整体流程
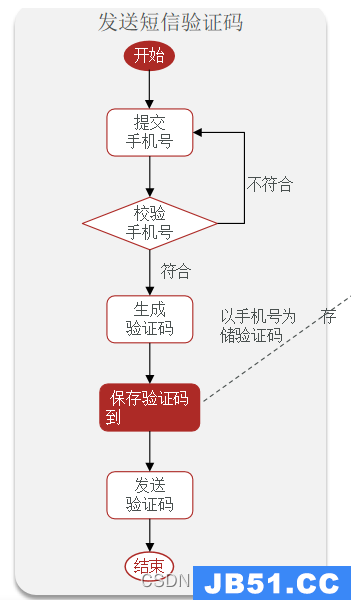
(1) 发送验证码
(2) 短信验证码登录、注册
(3) 校验登录状态 token
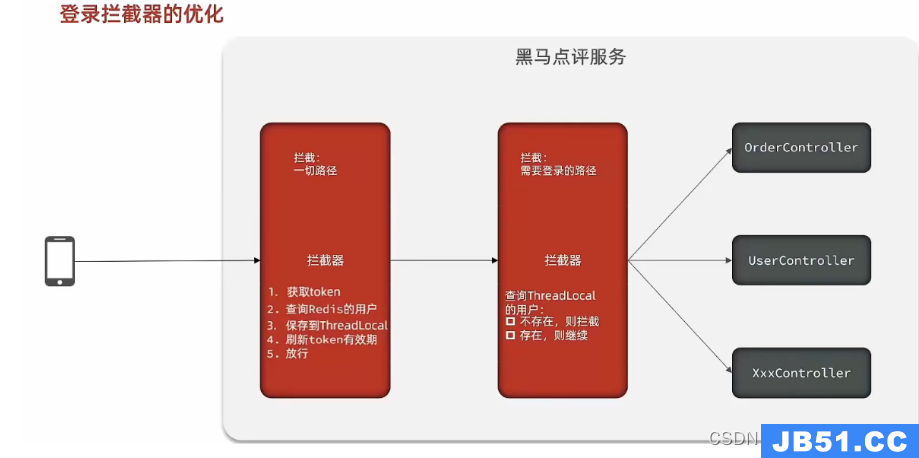
(4) 拦截器优化
二、实现商品信息缓存
1. 查询流程
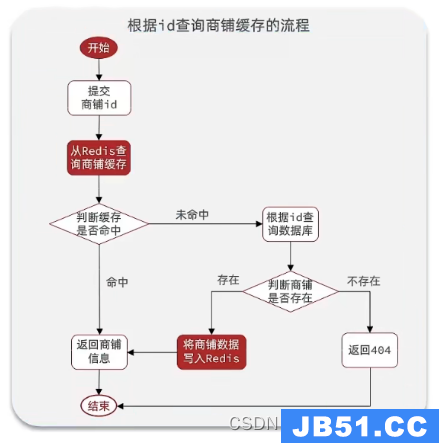
2. 缓存与数据库一致性问题
- redis缓存更新策略有几种?选择哪种?
内存淘汰和过期淘汰 主动更新 - 操作缓存和数据库
(1) 删除缓存还是更新缓存 删除
(2)如何保证缓存与数据库的操作同时成功或失败 事务
(3)先操作缓存还是数据库 写数据库比较慢
3. 三大问题及解决方案
-
缓存穿透
定义、有哪两种方式解决

-
缓存雪崩
定义(2种情况)、解决方案 -
缓存击穿
定义
两种解决方案: 一致性、可用性
-
互斥锁 setnx
利用redis的setnx命令,通过获取锁和释放锁的方式来完成。锁的过期时间设置10s,能够保证一致性,但是无法保证可用性(线程会一直查询)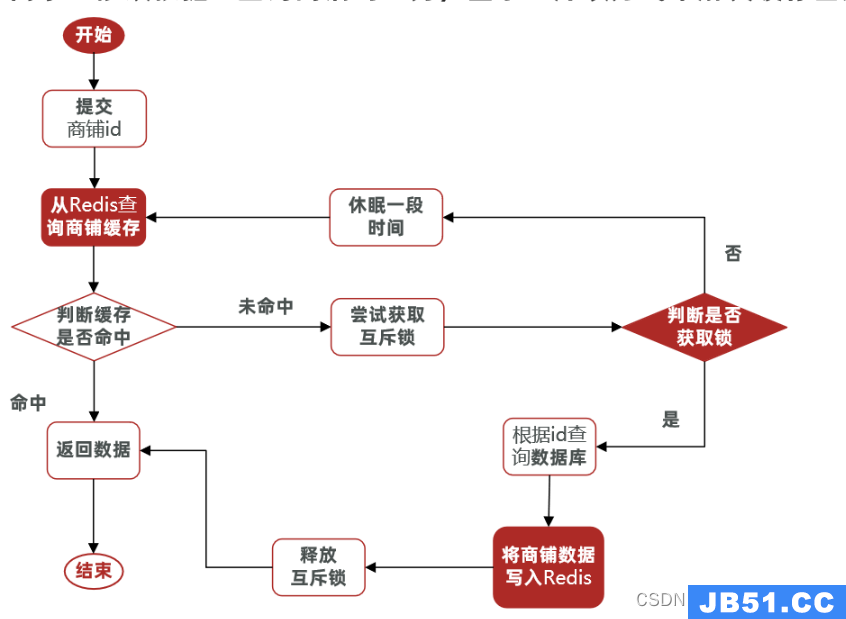
-
设置逻辑过期时间
给缓存设置一个逻辑过期时间
还是需要互斥锁,不同的就是:不是每一个线程都需要取重写数据库,如果发现获取不到锁会直接返回旧的数据,获取不到锁不会说一直重试,而且拿到锁也是开启一个新线程取写数据库。保证了可用性,但失去了一致性(此时拿到的数据不是新的数据)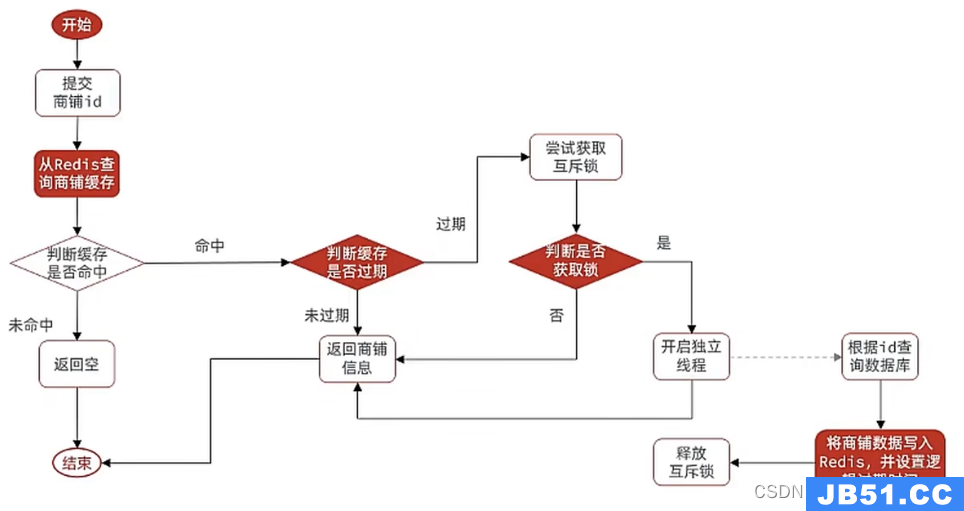
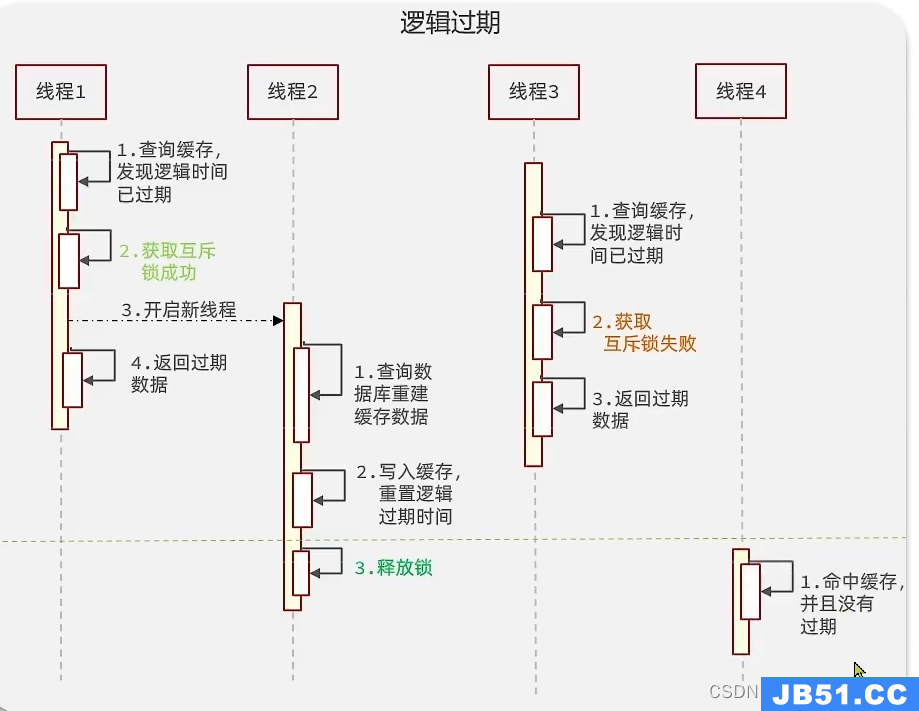
- 结果对比

三、优惠券秒杀
1. Redis自增实现全局唯一id
-
常见的生成全局唯一id生成策略
(各自特点,自己搜资料补充) -
具体实现方式及原因
符号位+时间戳+序列号 保证了递增性、安全性、唯一性
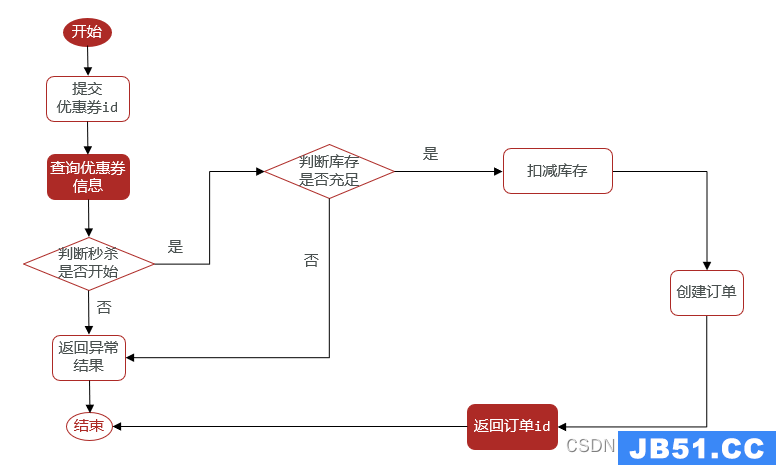
2. 秒杀下单,并利用乐观锁解决超卖问题
-
超卖是什么
库存小于0 -
下单必须满足的条件
秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
库存是否充足,不足则无法下单 -
能不能直接采用版本号?存在什么问题
只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的,但是以上这种方式通过测试发现会有很多失败的情况,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败 -
项目中的乐观锁如何实现
在扣减库存之前 判断库存大于0就好
3. 优惠券秒杀:一人一单
- 一人一单
-
解决方案
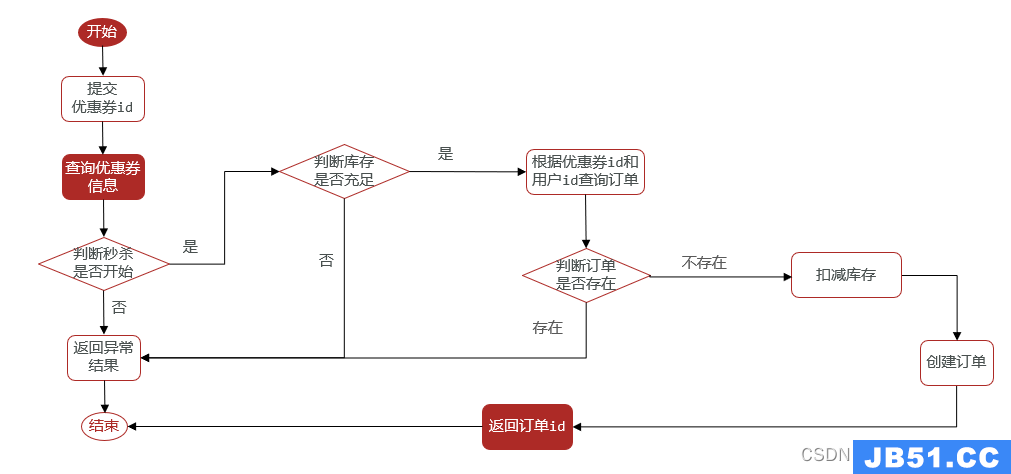
根据用户id加一个synchronized锁
控制锁的粒度
代理模式解决事务失效,并且保证提交事务后再释放锁(不建议自己说出来,坑太多,不好讲) - 存在的问题:集群模式下锁失效
4.分布锁解决集群下锁失效的问题(基于Setnx)
4.1 基于setnex(setIfAbsent) 实现分布式锁
防止死锁?添加过期时间
4.2 分布式锁的误删问题
什么是误删? 线程1发生了业务阻塞,锁超时释放了自己的锁,后面正常执行业务后,线程1又执行锁释放把线程2的锁给释放了
如何解决?:在释放锁的时候判断锁是否属于自己
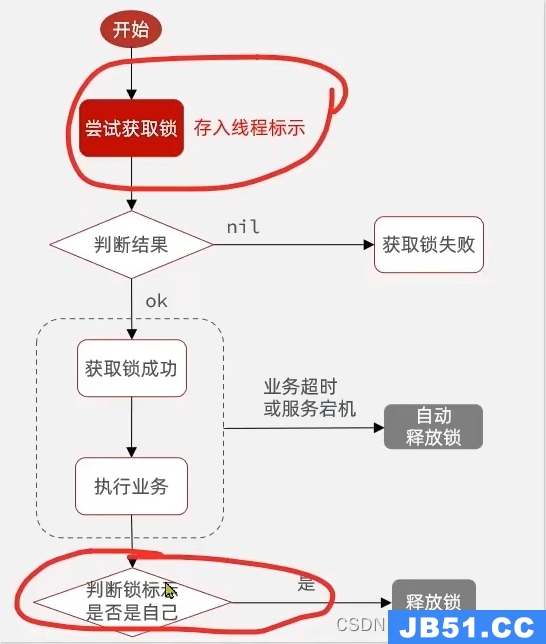
4.3 分布式锁的原子性问题
判断锁和释放锁是两个不同的动作!需要让判断和释放锁变成一个原子操作
利用lua脚本
4.4 存在的问题
不可重入
不可重试
超时释放
主从一致性
5. 基于Redission的分布式锁(对setnex的优化)
5.1 不可重入
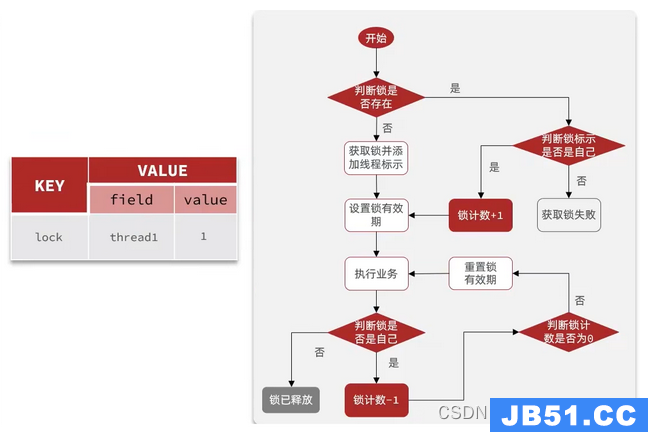
5.2 锁重试和watchdog机制
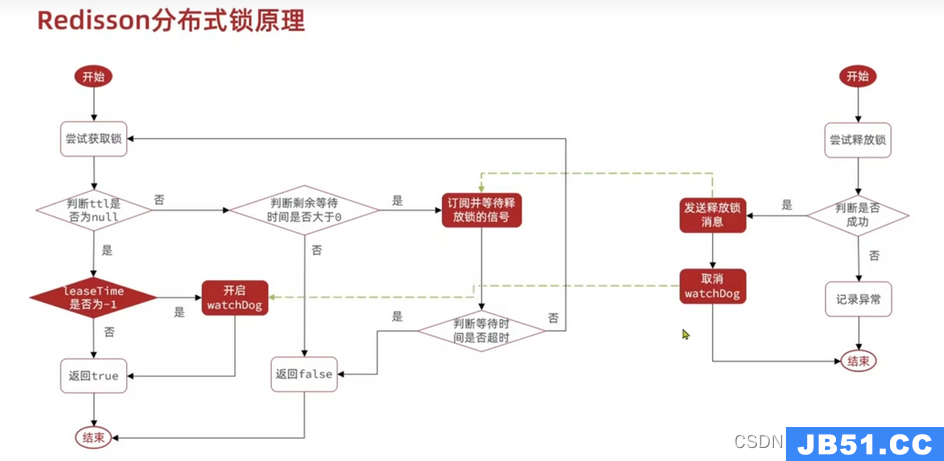

5.3 MultiLock解决主从不一致问题
redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性
6. 异步秒杀优化

- 基于阻塞队列的思路
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
内存限制问题
数据安全问题 - 基于Redis的Stream结构作为消息队列,实现异步秒杀下单
- 创建一个Stream类型的消息队列,名为stream.orders
- 修改之前的秒杀下单Lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包含voucherId、userId、orderId
- 项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单 (用Java代码消息队列中的信息),出现异常需要读取Pending List的
- Stream类型消息队列的消费者组的特点
四. 点赞排行榜
SortedSet数据结构 根据时间进行排行的
- 问题一:代码细节
List<UserDTO> userDTOS = userService.query()
.in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
- 问题二:SortedSet底层
hash结构:关联元素和权重
跳跃表:空间换时间,提高查找效率
五. 附近商户
-
设计思路
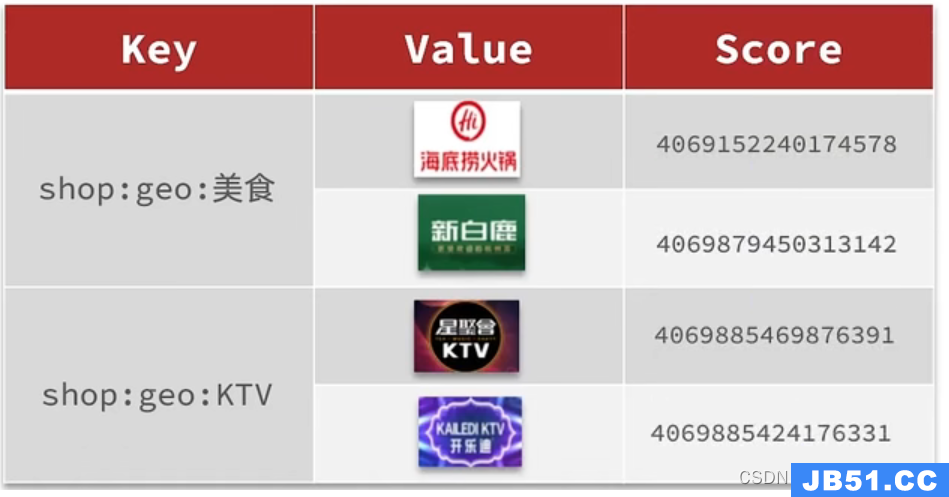
- 选择geo数据结构
- 分组
根据type来对数据进行筛选,所以我们可以按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可 - 导入数据
数据库表中的数据导入到redis中去,redis中的GEO,GEO在redis中就一个menber和一个经纬度,我们把x和y轴传入到redis做的经纬度位置去,但我们不能把所有的数据都放入到menber中去,毕竟作为redis是一个内存级数据库,如果存海量数据,redis还是力不从心,所以我们在这个地方存储他的id即可。
六. 用户签到
0. 数据结构
Bitmap
bitMap返回的数据是10进制

1. 签到功能
@Override
public Result sign() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix; //user:sign:5:202302
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.写入Redis SETBIT key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}
2. 统计签到天数
思路:
bitMap返回的数据是10进制,哪假如说返回一个数字8,那么我哪儿知道到底哪些是0,哪些是1呢?我们只需要让得到的10进制数字和1做与运算就可以了,因为1只有遇见1 才是1,其他数字都是0 ,我们把签到结果和1进行与操作,每与一次,就把签到结果向右移动一位,依次内推,我们就能完成逐个遍历的效果了。
七. UV统计
数据结构的选择HyperLogLog
八. 共同关注
选择的数据结构是set,比如用户1关注了A B C,那么就是 1:A B C
同理对用户2有同样的操作,求共同关注就是求两个set的交集
//设置key:当前登录用户,关注的对象
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
//求交集
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
九. 推模式Feed流
1. Feed流理论
- feed流:内容推送给用户
- feed流两种模式:Timeline和智能排序
- Timeline三种实现方式:推、拉、推拉结合
拉模式:
当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序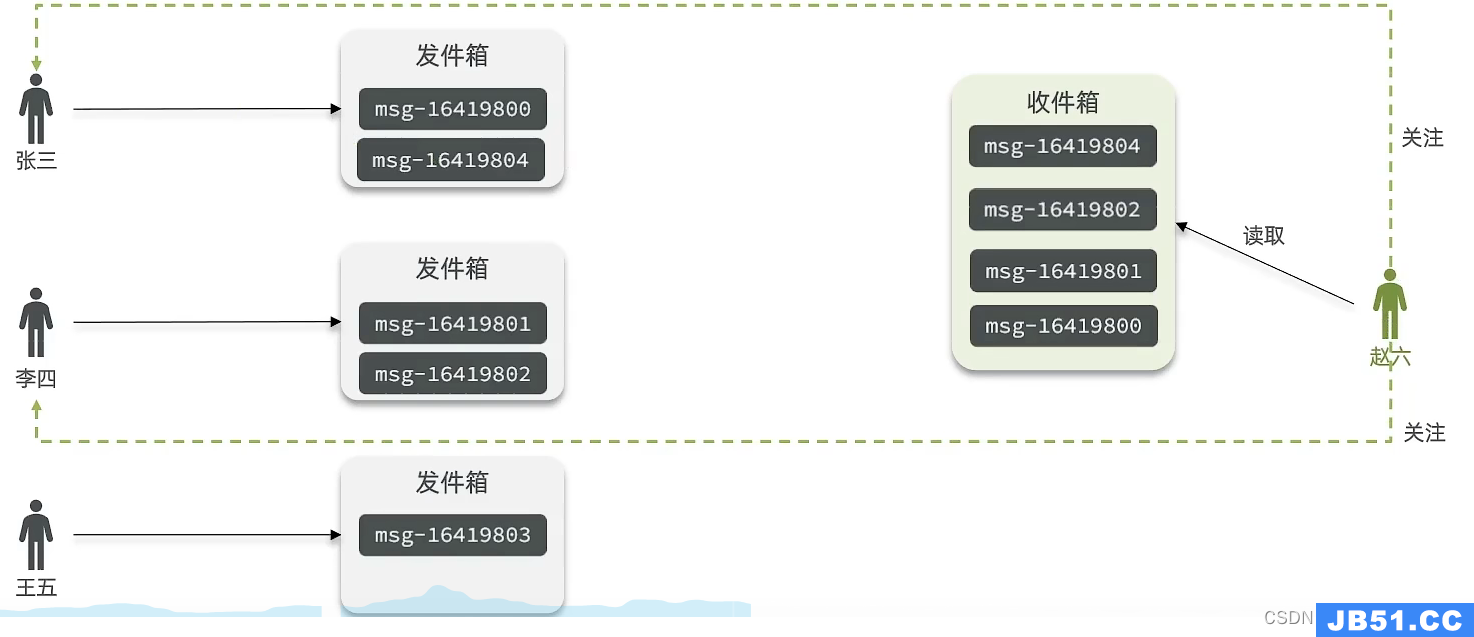
推模式:
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
优点:时效快,不用临时拉取
缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多分数据到粉丝那边去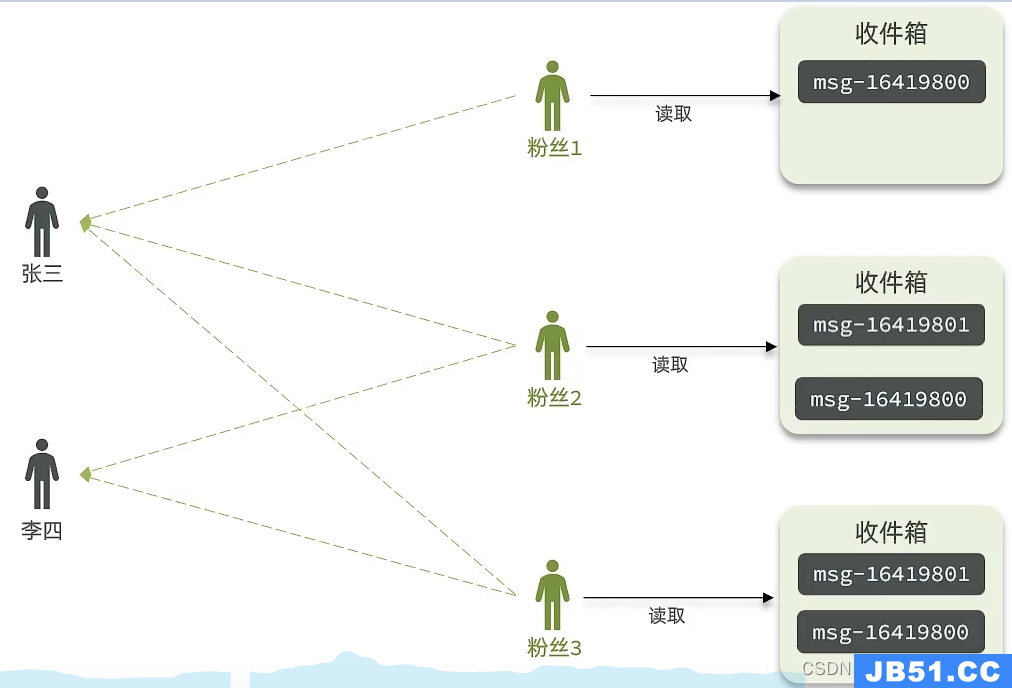
推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。
推拉模式是一个折中的方案,站在发件人这一段,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力,如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去,现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
2. 实现方案
在保存完探店笔记后,获得到当前笔记的粉丝,然后把数据推送到粉丝的redis中去。按照时间顺序feed,数据结构
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}
功能二:实现分页查询
思路分析
1、每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
2、我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
综上:我们的请求参数中就需要携带 lastId:上一次查询的最小时间戳 和偏移量这两个参数。
这两个参数第一次会由前端来指定,以后的查询就根据后台结果作为条件,再次传递到后台。
 文章浏览阅读752次。关系型数据库关系型数据库是一个结构化的...
文章浏览阅读752次。关系型数据库关系型数据库是一个结构化的...