NLP进阶之(九)BiLSTM-CRF模型
一、BiLSTM-CRF构造
对于NER而言,我们可以构造BiLSTM-CRF来实现
NER中,往往需要得到一个序列标注:
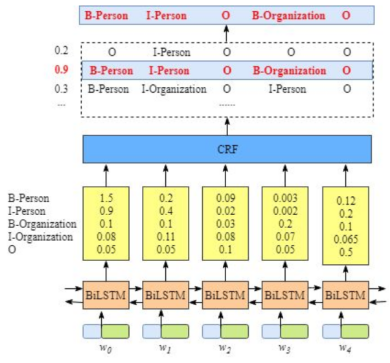
二、CRF构造序列标注
2.1 CRF两类得分
2.1.1 Emission-Score
从上述图示中,我们可以看到,当我们输入一个w0抑或是w1就可以得到相对应每个标签序列的得分。如输入w0即得到B-Person得分值为1.5,而输入w1得到B-Person得分值为0.2,这个分数是由我们的BiLSTM所构造所得。
为了方便索引,我们给每个标签一个id索引:
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
其中,Xi,yj=2代表分数,i是单词的位置索引,yj是类别索引,根据上述表示可得:
Xi,yj=2=Xw1,B−Organization=0.1
表示单词w1被预测出来为B-Organization的分数为0.1。表示单词w1输入到我们BiLSTM层进行计算时,输出的B-Person的概率就是0.1。我们由这个神经网络的计算输出可得到下面的两种分数。
2.1.2 Transaction-Score
| START | B-Person | I-Person | B-Organization | I-Organization | O | END | |
|---|---|---|---|---|---|---|---|
| START | 0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| B-Person | 0 | 0.6 | 0.9 | 0.2 | 0.0006 | 0.6 | 0.009 |
| I-Person | -1 | 0.5 | 0.053 | 0.55 | 0.25 | 0.0003 | 0.008 |
| B-Organization | 0 | 0.8 | 0.001 | 0.7 | 0.0008 | 0.9 | 0.08 |
| I-Organization | 0 | 0.8 | 0.053 | 0.7 | 0.053 | 0.9 | 0.08 |
| O | 0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| END | 0 | 0.8 | 0.24 | 0.7 | 0.47 | 0.9 | 0.08 |
从上表中我们可以得到如下三个结论:
- 句子的第一个单词是B-或O-,而不是I。(从START -> I-Person 或者 I-Organzation的转移分数很低,分别是
-0.9以及-1) - B-Label1 I-Label2 I-Label3…,在该模式中,类别1,2,3应该是同一种实体类别。比如,B-Organization是正确的,而B-Person I-Organizaiton则是错误的。(B-Organzation-> I-Person的分数很低)
- O I-Label是错误的,命名实体的开头应该是B-而不是I-。
说归说,在实际过程中,我们是怎么样得到这个转移矩阵的呢?
实际上,转移矩阵是BiLSTM-CRF模型的一个参数,在训练模型之前,可以随机初始化转移矩阵的分数。这些分数将会随着迭代的过程被更新,换句话说,CRF层可以自己学到这些约束条件。
2.2 CRF 损失函数
对于CRF的损失函数而言,其由两个部分组成,一个是真实路径得分,一个是总路径得分。真实路径的分数应该是所有路径中分数最高的。那么这两个概念是怎么来的呢?其实,也是同样从类别标签中出现的。于是,我们的数据集在下面有集中类别:
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
| START | 5 |
| END | 6 |
一个句子包含5个状态序列,那么可能的类别序列如下:
- 1.START B-Person B-Person B-Person B-Person B-Person END
- 2.START B-Person I-Person B-Person B-Person B-Person END
- 3…
- 10.START B-Person I-Person O B-Organization O END
- N. O O O O O O
这样,每种可能的路径分数为Pi,共有N条路径,那么路径的总分是:
Ptotal=P1+P2+...+PN
每个标签Pi可以表示为eSi,其中i代表着第i条路径,e是常数e。
如果第十条路径是真实路径,也就是说第十条是正确的预测结果,那么第十条路径的分数应该是所有可能路径里最高的,根据如下的损失函数,在训练过程中,BiLSTM-CRF模型的参数值将在迭代过程中不断更新,使得真实路径所占的比值越来越大。这样,我们可以计算出我们的损失函数:
LossFunction=P1+P2+...+PNPRealPath
其中,最主要的问题依然是如何定义Pi,就是我们的路径分数。对于真实路径的分数而言,计算eSi,我们以START B-Person I-Person O B-Organization O END这条真实路径而言,句子中有5个单词w1,w2,w3,w4,w5,加上START和END在句子的开始位置和结束位置,记为w0和w6,那么我们的总分数就是:
Si=EmissionScore+TransitionScore
(1) EmissionScore
可以计算EmissionScore=x0,START+x1,B−Person+x2,I−Person+x3,O+x4,B−Organization+x5,O+x6,END 其中,这些分数都来自于BiLSTM层的输出,至于x0,START与x6,END则设置为0。
(1) TransitionScore
计算完EmissionScore(排放分数)后,我们可以计算TransitionScore(转移分数)了:
TransitionScore=t0,START−>B−Person+t1,B−Person−>I−Person+t2,I−Person−>O+tO−>B−Organization+tO−>END
这些分数都来自于CRF层,将这两类的分数相加即可得到Si和eSi。
那么如何计算所有路径的总分呢?由于我们前面所定义的损失函数为:LossFunction=P1+P2+...+PNPRealPath 我们将损失函数求log变换得:Log(LossFunction)=logP1+P2+...+PNPRealPath
由于我们训练的目标通常都是最小化损失函数,所以加上负号得:Log(LossFunction)=logeS1+eS2+...+eSNeSRealPath 之后损失函数可求得:
−(i=1∑Nxiyi+i=1∑N−1tyiyi+1−log(eS1+eS2+...+eSN))
2.3 CRF Demo
为了简化问题,我们假定我们的句子只有3个单词组成:
x=[w0,w1,w2]
另外,我们只有两个类别:
LabelSet=l1,l2
状态分数EmissionScore如下:
| l1 | l2 | |
|---|---|---|
| w0 | x01 | x02 |
| w1 | x11 | x12 |
| w2 | x21 | x22 |
转移矩阵TranscitionScore如下:
| l1 | l2 | |
|---|---|---|
| l1 | t11 | t12 |
| l2 | t21 | t22 |
我们的目标是:log(eS1+eS2+...+eSN)
整个过程就是一个分数积聚的过程,其思想有点类似于动态规划。首先,w0所有路径的总分鲜卑计算出来,然后,我们计算w0−>w1的所有路径得分,最后计算w0−>w1−>w2 的所有路径得分,也就是我们所需要的结果。
接下来,会出现两个变量Previous以及obs,Previous存储了之前步骤的结果,obs代表当前单词所带的信息。
w0: obs=[x01,x02] previous=None
如果我们的句子只有一个单词,我们就没有之前的步骤,所以previous是空值,我们只能观测到状态分数 obs=[x01,x02]
w0的所有路径总分就是:TotalScore(w0)=log(ex01+ex02)
w0−>w1: obs=[x11,x12] previous=[x01,x02]
我们的previous为
previous=(x01x01x02x02)
我们的obvious观察为
obvious=(x11x12x11x12)
那为什么要扩展previous和obvious矩阵呢?因为接下来操作可以是一个高效存在:
scores=(x01x01x02x02)+(x11x12x11x12)+(t11t12t21t22)
得到
scores=(x01+x11+t11x01+x12+t12x02+x11+t21x02+x12+t22)
将我们的转移矩阵变成前向后得到
previous=[log(ex01+x11+t11+ex02+x11+t21),log((ex01+x12+t12+ex02+x12+t22)]
实际上,第二次迭代过程也就是随着迭代进行而完成。
TotalScore(w0−>w1) =log(epervious[0]+eprevious[1]) =log(epervious[0]+eprevious[1]) =log(epervious[0]+eprevious[1])
推导过程参考以下链接(mardown公式太难编辑,有空再编辑),作上述步骤的目的是为了得到一个总体的路径规划,通过previous以及obvious可得到:log(eS1+eS2+...+eSN)
对于我们的句子中,一共有3个单词以及两个类别,一共有8条路径。
2.4 探索词性标注
1. BiLSTM-CRF模型得到的排放分数和转移分数
假定我们的句子一共3个单词组成:
X=[w0,w1,w2]
并且,我们已经从模型中得到了发射分数,如下:
EmissionScore
| l_1 | l_2 | |
|---|---|---|
| w0 | x01 | x02 |
| w1 | x11 | x12 |
| w2 | x21 | x22 |
TransactionScore
| l_1 | l_2 | |
|---|---|---|
| l_1 | t11 | t12 |
| l_2 | t21 | t22 |
开始预测,若熟悉Viterbi算法,当然会非常简单。当然,不熟悉的也无所谓,整个预测过程和之前求所有路径总分的过程非常类似,我们将逐步解释清楚,我们先从左到右的顺序来运行预测算法。
- w0
- w0−>w1
- w0−>w1−>w2
在这个过程中,将会看到两类变量,分别是obs和previous。Previous存储了上一个步骤的最终结果,Obs代表当前单词包含的信息(发射分数)。
Alpha0是历史最佳分数,Alpha1是最佳分数所对应的类别索引。这两类变量详细信息会做说明。我们根据最大得分找到最佳路径。那么Alpha0与Alpha1将会被用来寻找最佳路径。


