交叉熵
熵/信息熵
假设一个发送者想传输一个随机变量的值给接收者。这个过程中,他们传输的平均信息量为:
![\large H[x]=-\sum_xp(x){log}_{2}p(x)](https://www.jb51.cc/res/2021/03-17/00/3fd30fab3ea3de2a1e9b369da637f8e1.jpg%3D-%5Csum_xp%28x%29%7Blog%7D_%7B2%7Dp%28x%29)
![\large H[x]](https://www.jb51.cc/res/2021/03-17/00/3fd30fab3ea3de2a1e9b369da637f8e1.jpg)
叫随机变量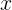
的熵,其中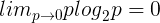
把熵扩展到连续变量
的概率分布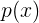
,则熵变为
![\large H[x]=-\int p(x)lnp(x)dx](https://www.jb51.cc/res/2021/03-17/00/f809551e284735468eae34b2b1e3a16b.jpg)
被称为微分熵。
在离散分布下,最大熵对应于变量的所有可能状态的均匀分布。
最大化微分熵的分布是高斯分布
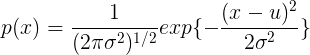
相对熵/KL散度
考虑某个未知分布
,假设我们使用一个近似分布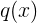
对其进行建模。如果我们使用
来建立一个编码体系,用来把
传递给接收者,由于我们使用了
而不是真实分布
,因此在具体化
时,我们需要一些附加信息。我们需要的附加信息量为:
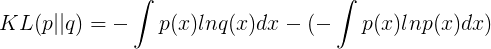
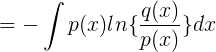
这被称为分布
与分布
之间的相对熵,或者KL散度。KL散度大于等于零,当两个分布一致时等于零。
交叉熵
交叉熵本质上可以看成,用一个猜测的分布的编码去编码真实的分布,得到的信息量:

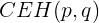
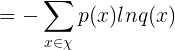
![\large =-[P_p(x=1)lnP_q(x=1)+P_p(x=0)P_q(x=0)]](https://www.jb51.cc/res/2021/03-17/00/e728cff70f26850d00e402227efe0ddc.jpg)
![\large =-[plnq+(1-p)ln(1-q)]](https://www.jb51.cc/res/2021/03-17/00/c53142a9f88ea5d23a9f7a96ca689b8d.jpg)
![\large =-[ylnh_\theta(x)+(1-y)ln(1-h_\theta(x))]](https://www.jb51.cc/res/2021/03-17/00/ec6975c7c17afb5f5422645fd8fba22d.jpg)
对所有训练样本取均值得到:
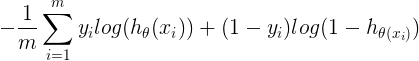
对数损失函数
对数损失函数的表达式为:
参见https://blog.csdn.net/qq_38625259/article/details/88362765
交叉熵和对数损失函数之间的关系
交叉熵中未知真实分布
相当于对数损失中的真实标记
,寻找的近似分布
相当于我们的预测值。如果把所有样本取均值就把交叉熵转化成了对数损失函数。
本文转载自:https://blog.csdn.net/qq_38625259/article/details/88371462?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
 Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具...
Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具... NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一...
NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一... 做一个中文文本分类任务,首先要做的是文本的预处理,对文本...
做一个中文文本分类任务,首先要做的是文本的预处理,对文本...