TextRank 算法是一种用于文本的基于图的排序算法,其基本思想来源于谷歌的 PageRank算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要。
自动文本摘要是自然语言处理(NLP)领域中最具挑战性和最有趣的问题之一。它是一个从多种文本资源(如书籍、新闻文章、博客帖子、研究类论文、电子邮件和微博)生成简洁而有意义的文本摘要的过程。由于大量文本数据的可获得性,目前对自动文本摘要系统的需求激增。本文主要研究基于TextRank的文本摘要算法。
一、文本摘要方法
文本摘要可以大致分为两类——抽取型摘要和抽象型摘要:
-
抽取型摘要:这种方法依赖于从文本中提取几个部分,例如短语、句子,把它们堆叠起来创建摘要。因此,这种抽取型的方法最重要的是识别出适合总结文本的句子。
-
抽象型摘要:这种方法应用先进的NLP技术生成一篇全新的总结。可能总结中的文本甚至没有在原文中出现。
本文,我们将关注于抽取式摘要方法。
二、TextRank算法的基本原理
TextRank算法是由网页重要性排序算法PageRank算法迁移而来:PageRank算法根据万维网上页面之间的链接关系计算每个页面的重要性;TextRank算法将词视为“万维网上的节点”,根据词之间的共现关系计算每个词的重要性,并将PageRank中的有向边变为无向边。所以,在介绍TextRank算法之前,先介绍一下PageRank算法。
2.1 PageRank算法的原理
PageRank对于每个网页页面都给出一个正实数,表示网页的重要程度,PageRank值越高,表示网页越重要,在互联网搜索的排序中越可能被排在前面。假设整个互联网是一个有向图,节点是网页,每条边是转移概率。网页浏览者在每个页面上依照连接出去的超链接,以等概率跳转到下一个网页,并且在网页上持续不断地进行这样的随机跳转,这个过程形成了一阶马尔科夫链,比如下图,每个笑脸是一个网页,既有其他网页跳转到该网页,该网页也会跳转到其他网页。在不断地跳转之后,这个马尔科夫链会形成一个平稳分布,而PageRank就是这个平稳分布,每个网页的PageRank值就是平稳概率。

PageRank的核心公式是PageRank值的计算公式。这个公式来自于《统计学习方法》,和很多博客上的公式有点轻微的差别,那就是等号右边的平滑项不是(1-d),而是(1-d)/n。

加平滑项是因为有些网页没有跳出去的链接,那么转移到其他网页的概率将会是0,这样就无法保证存在马尔科夫链的平稳分布。于是,我们假设网页以等概率(1/n)跳转到任何网页,再按照阻尼系数d,对这个等概率(1/n)与存在链接的网页的转移概率进行线性组合,那么马尔科夫链一定存在平稳分布,一定可以得到网页的PageRank值。
所以PageRank的定义意味着网页浏览者,按照以下方式在网上随机游走:在任意一个网页上,浏览者以概率d按照存在的超链接随机跳转,这时以等概率从连接出去的超链接跳转到下一个页面;或以概率(1-d)进行完全随机跳转,这时以等概率1/n跳转到任意网页。第二个机制保证从没有连接出去的超链接的网页也可以跳转。
2.2 TextRank算法
在文本自动摘要的案例中,TextRank和PageRank的相似之处在于:
-
用句子代替网页
-
任意两个句子的相似性等价于网页转换概率
-
相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
不过公式有些小的差别,那就是用句子的相似度类比于网页转移概率,用归一化的句子相似度代替了PageRank中相等的转移概率,这意味着在TextRank中,所有节点的转移概率不会完全相等。
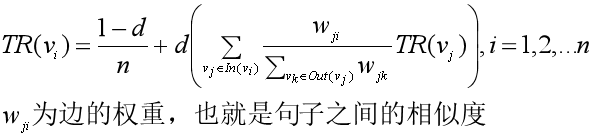
然后迭代过程就和PageRank一致了。
2.3 TextRank生成自动摘要的过程
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
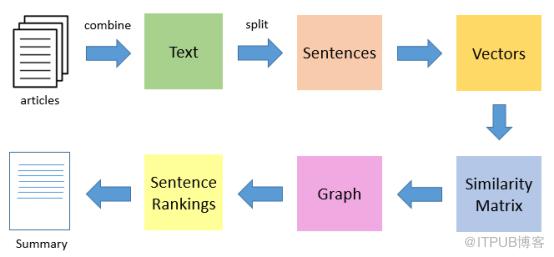
1. 第一步是把所有文章整合成文本数据
2. 接下来把文本分割成单个句子
3. 然后,我们将为每个句子找到向量表示(词向量)。
4. 计算句子向量间的相似性并存放在矩阵中
5. 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
6. 最后,一定数量的排名最高的句子构成最后的摘要。
三、基于TextRank的中文新闻摘要实例
3.1 整合文档,划分句子
首先把文档读入,放在列表中,可以看到,有些句子已经被划分出来了。
['信息量巨大!易会满首秀,直面科创板8大问题,对散户加速入场笑而不语……','每日经济新闻','02-2717:56','每经编辑:郭鑫 王晓波','图片来源:新华社记者 李鑫 摄','易会满上任一个月,还没有在公开场合说过一句话。','2月27日下午三点半开始,中国证监会主席易会满在北京国新办出席其首场新闻发布会,离发布会开始前两小时现场已经座无虚席,只等易主席来到现场。此外,副主席李超、副主席方星海,上海证券交易所理事长黄红元等也共同出席。',...]
不过通过观察,我们可以发现存在两个问题:
一是以[。?!;]作为句子的分隔符,那么列表中的每个字符串元素中可能有多个句子;
二是每个字符串元素可能以[:,]结尾,也就是说可能是一个不完整的句子。
考虑到这只是一个小案例,所以就没花太多时间,仅仅处理一下第一个问题,把句子按照[。?!;]进行划分,如果字符串元素是不完整的句子,那也作为一句。
import numpy as np
pandas as pd
re,os,jieba
from itertools chain
"""第一步:把文档划分成句子"""
# 文档所在的文件夹
c_root = os.getcwd()+os.sep+"cnews"+os.sep
sentences_list = []
for file in os.listdir(c_root):
fp = open(c_root+file,'r',encoding=utf8")
for line fp.readlines():
if line.strip():
把元素按照[。!;?]进行分隔,得到句子。
line_split = re.split(r[。!;?]',line.strip())
[。!;?]这些符号也会划分出来,把它们去掉。
line_split = [line.strip() in line_split if line.strip() not in [。!?;'] and len(line.strip())>1]
sentences_list.append(line_split)
sentences_list = list(chain.from_iterable(sentences_list))
print(前10个句子为:\n)
print(sentences_list[:10])
前10个句子为:
[信息量巨大易会满首秀,直面科创板8大问题,对散户加速入场笑而不语……每日经济新闻02-2717:56每经编辑:郭鑫 王晓波图片来源:新华社记者 李鑫 摄易会满上任一个月,还没有在公开场合说过一句话2月27日下午三点半开始,中国证监会主席易会满在北京国新办出席其首场新闻发布会,离发布会开始前两小时现场已经座无虚席,只等易主席来到现场此外,副主席李超、副主席方星海,上海证券交易所理事长黄红元等也共同出席这可能是这个月国内关注的人最多的一场新闻发布会了']
3.2 文本预处理
文本预处理包括去除停用词和非汉字字符,并进行分词。处理的过程要保证处理之后的句子的数量和处理之前的一样,因为后面我们计算了每个句子的textrank值之后,需要根据textrank值的大小,取出相应的句子作为摘要。
比如 '02-2717:56' 这个句子整个被过滤了,那就令这个句子为[],下面也会给它一个句子的向量表示,只是元素都为0。
第二步:文本预处理,去除停用词和非汉字字符,并进行分词创建停用词列表 stopwords = [line.strip() in open(./stopwords.txtUTF-8).readlines()] 对句子进行分词 def seg_depart(sentence): 去掉非汉字字符 sentence = re.sub(r[^\u4e00-\u9fa5]+'' jieba.cut(sentence.strip()) word_list = [] for word sentence_depart: if word stopwords: word_list.append(word) 如果句子整个被过滤掉了,如:'02-2717:56'被过滤,那就返回[],保持句子的数量不变 return word_list sentence_word_list =for sentence sentences_list: line_seg = seg_depart(sentence) sentence_word_list.append(line_seg) 一共有",len(sentences_list),1)">个句子。\n前10个句子分词后的结果为:\n]) 保证处理后句子的数量不变,我们后面才好根据textrank值取出未处理之前的句子作为摘要。 if len(sentences_list) == len(sentence_word_list): \n数据预处理后句子的数量不变!")
一共有 347 个句子。
前10个句子分词后的结果为:
[[信息量],[易会满首秀直面科创板散户加速入场笑不语每日经济新闻每经编辑郭鑫王晓波图片来源李鑫摄上任一个月公开场合说一句话三点中国证监会主席北京国新办出席首场发布会前两小时现场座无虚席易来到副李超星海上海证券交易所理事长黄红元国内关注一场]]
数据预处理后句子的数量不变!
3.3 加载word2vec词向量
从这里下载了金融新闻word2vec词向量:https://github.com/Embedding/Chinese-Word-Vectors。
词向量是300维的,字和词语都有。我们把词向量加载进来,做成一个字典,共有467140个词语或字。
第三步:准备词向量"""
word_embeddings = {}
f = open(./sgns.financial.charutf-8 f:
把第一行的内容去掉
if 467389 300\n' line:
values = line.split()
第一个元素是词语
word = values[0]
embedding = np.asarray(values[1:],dtype=float32)
word_embeddings[word] = embedding
f.close()
"+str(len(word_embeddings))+个词语/字。")
一共有467140个词语/字。
3.4 得到词语的embedding,用WordAVG作为句子的向量表示
WordAVG也就是先得到句子中的所有词语的词向量,然后求词向量的平均,作为该句子的向量表示。WordAVG可以用来计算句子的相似度。
第四步:得到词语的embedding,用WordAVG作为句子的向量表示
sentence_vectors =for i sentence_word_list:
if len(i)!=0:
如果句子中的词语不在字典中,那就把embedding设为300维元素为0的向量。
得到句子中全部词的词向量后,求平均值,得到句子的向量表示
v = sum([word_embeddings.get(w,np.zeros((300,))) for w in i])/(len(i))
else:
如果句子为[],那么就向量表示为300维元素为0个向量。
v = np.zeros((300 3.5 计算句子之间的余弦相似度,构成相似度矩阵
第五步:计算句子之间的余弦相似度,构成相似度矩阵
sim_mat = np.zeros([len(sentences_list),len(sentences_list)])
from sklearn.metrics.pairwise cosine_similarity
range(len(sentences_list)):
for j range(len(sentences_list)):
if i != j:
sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,300),sentence_vectors[j].reshape(1,300))[0,0]
句子相似度矩阵的形状为:
句子相似度矩阵的形状为: (347,347)
3.6 迭代得到句子的textrank值,排序并取出摘要
以句子为节点、相似性得分为转移概率,构建图结构,然后迭代得到句子的TextRank分数。
对句子按照TextRank值进行降序排序,取出排名最靠前的10个句子作为摘要。
第六步:迭代得到句子的textrank值,排序并取出摘要"""
networkx as nx
利用句子相似度矩阵构建图结构,句子为节点,句子相似度为转移概率
nx_graph = nx.from_numpy_array(sim_mat)
得到所有句子的textrank值
scores = nx.pagerank(nx_graph)
根据textrank值对未处理的句子进行排序
ranked_sentences = sorted(((scores[i],s) for i,s in enumerate(sentences_list)),reverse=True)
取出得分最高的前10个句子作为摘要
sn = 10
range(sn):
第"+str(i+1)+条摘要:\n\n\n')
第1条摘要:
在新闻发布会上,易会满表示,我到证监会工作今天是31天,刚刚满月,是资本市场的新兵,从市场参与者到监管者,角色转换角色挑战很大,如履薄冰,不敢懈怠,唯恐辜负中央信任和市场期待,这也是我做好工作的动力, 近期加强调查研究,和部门协作维护市场平稳发展,维护科创板前期基础工作
第2条摘要:
易会满在新闻发布会上表示,防止发生系统性风险是底线和根本任务,当前受国内外多种因素影响,资本市场风险形式严峻复杂,证监会将坚持精准施策,做好股票质押私募基金、场外配资和地方各类场所的重点领域风险的防范化解 和处置工作,完善资本市场逆周期机制,健全及时反映风险波动系统,运用大数据、人工智能等手段对上市公司专业监管,平衡事前、事中、事后关系,监管端口前移,强化监管效能
第3条摘要:
证监会将坚持精准施策,做好股票质押私募基金、场外配资和地方各类场所的重点领域风险的防范化解和处置工作,完善资本市场逆周期机制,健全及时反映风险波动系统,运用大数据、人工智能等手段对上市公司专业监管, 平衡事前、事中、事后关系,监管端口前移,强化监管效能,切实做好打铁必须自身硬,做好中介机构和高管的强监管
第4条摘要:
这两者出发点和规则不同,我来证监会后不断学习研究,这么专业的问题证监会有专业化的团队,资本市场是大的生态,什么叫市场,应该是依靠市场各参与者,调动市场参与者,市场规律办事, 培养健康生态比什么都重要, 这一考验和要求比专业更重要,生态建设好了,资本市场的健康发展才有保证
第5条摘要:
证监会副主席李超今天也给市场吃下定心丸:“对二级市场影响的问题,(科创板)设立时已经高度关注,在一系列的制度、规则层面作了相应安排
第6条摘要:
他表示,第一,设立科创板主要目的是增强资本市场对实体经济的包容性,更好地服务具有核心技术、行业领先、有良好发展前景和口碑的企业,通过改革进一步完善支持创新的资本形成机制
第7条摘要:
一是提高宏观思维能力,贴近市场各参与方,坚持市场导向、法治导向、监管导向,加强对资本市场宏观战略问题的研究思考,加强顶层设计,增强战略定力,稳步推进重点关注问题的改革创新,在改革中、在发展中破解难题
第8条摘要:
集体学习的通稿中,中央给资本市场定的“法治化”要求有不少,比如“把好市场入口和市场出口两道关,加强全程监管”、“解决资本市场违法违规成本过低问题”
第9条摘要:
易会满表示,证监会将以xijinping新时代中国特色社会主义思想为指导,在国务院金融委的统一指挥协调下,主动加强与相关部委、地方党委政府和市场各方的沟通协作,努力形成工作合力,共同促进资本市场高质量发展
第10条摘要:
目前,资本市场已经回暖,这为改革提供了良好市场条件,我们要齐心协力,坚持“严标准、稳起步”的原则,积极做好落实和应对工作,注重各市场之间的平衡,确保改革平稳启动实施
这样就完成了一个文本自动摘要的小实践了。
参考:
https://blog.csdn.net/wotui1842/article/details/80351386
https://cloud.tencent.com/developer/article/1065278
http://blog.itpub.net/31562039/viewspace-2286669/
https://www.cnblogs.com/Luv-GEM/p/10884493.html
李航:《统计学习方法》(第二版)
 Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具...
Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具... NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一...
NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一... 做一个中文文本分类任务,首先要做的是文本的预处理,对文本...
做一个中文文本分类任务,首先要做的是文本的预处理,对文本...