1. 前言
循环神经网络(recurrent neural network)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。
传统的机器学习算法非常依赖于人工提取的特征,使得基于传统机器学习的图像识别、语音识别以及自然语言处理等问题存在特征提取的瓶颈。而基于全连接神经网络的方法也存在参数太多、无法利用数据中时间序列信息等问题。随着更加有效的循环神经网络结构被不断提出,循环神经网络挖掘数据中的时序信息以及语义信息的深度表达能力被充分利用,并在语音识别、语言模型、机器翻译以及时序分析等方面实现了突破。
2. RNN模型结构
循环神经网络的主要用途是处理和预测序列数据。在之前介绍的全连接神经网络或卷积神经网络模型中,网络结构都是从输入层到隐含层再到输出层,层与层之间是全连接或部分连接的,但每层之间的节点是无连接的。考虑这样一个问题,如果要预测句子的下一个单词是什么,一般需要用到当前单词以及前面的单词,因为句子中前后单词并不是独立的。比如,当前单词是“很”,前一个单词是“天空”,那么下一个单词很大概率是“蓝”。循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上时刻隐藏层的输出。
RNN结构如下图:
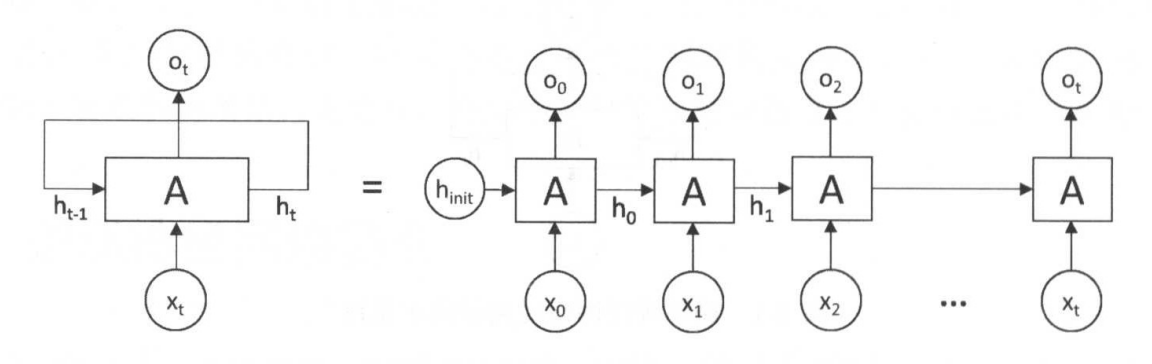
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号t附近RNN的模型。其中:
1、xt代表在序列索引号t时训练样本的输入。同样的,xt−1和xt+1代表在序列索引号t−1和t+1时训练样本的输入。
2、ht代表在序列索引号t时模型的隐藏状态。ht由xt和ht−1共同决定。
3、ot代表在序列索引号t时模型的输出。ot只由模型当前的隐藏状态ht决定。
4、A代表RNN模型。
3. RNN前向传播算法
最后,给出经典RNN结构的严格数学定义。
输入为x1,x2,···,xt对应的隐状态为h1,h2,ht
输出为y1,y2,yt,如,则经典RNN的运算过程可以表示为
ht=f(Uxt+Wht−1+b)
yt=softmax(Vht+c)
其中,U,W,V,b,c均为参数,而f()表示激活函数,一般为tanh函数。
4.总结
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失时的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。
 Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具...
Newtonsoft.JsonNewtonsoft.Json是.Net平台操作Json的工具... NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一...
NLP(NaturalLanguageProcessing)自然语言处理是人工智能的一... 做一个中文文本分类任务,首先要做的是文本的预处理,对文本...
做一个中文文本分类任务,首先要做的是文本的预处理,对文本...