Kibana安装
1.下载tar包
2.添加elk用户
useradd elk
usermod -s /sbin/nologion elk #不让elk用户来登陆系统
3.解压
tar -xvf kibana-6.5.4-linux-x86_64.tar.gz
4.修改配置文件
cd /usr/kibana-6.5.4-linux-x86_64/config
vi kibana.yml
server.port: 5601
server.host: “0.0.0.0” 开通公网访问
#elasticsearch.url: "http://localhost:9200" 调用数据地址
#elasticsearch.username: "user" 配置elasticsearch用户名密码
#elasticsearch.password: "pass"
5.把kibana目录改成elk用户
chown -R elk:elk /usr/kibana-6.5.4-linux-x86_64
6.编写启动脚本
nohup /usr/kibana-6.5.4-linux-x86_64/bin/start.sh >> /usr/kibana-6.5.4-linux-x86_64/log/kibana.log 2>&1 &
chmod -R 755 start.sh
7.用普通用户启动
su -s /bin/bash elk '/usr/kibana-6.5.4-linux-x86_64/bin/start.sh'
8.然后就可以直接访问了
9.把elasticsearch 目录改成elk用户
chown -R elk:elk /usr/elasticsearch-6.5.3
nginx安装
1.进入目录
/etc/yum.repos.d
vim nginx.repo
2.粘贴配置
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
3.安装nginx
yum install nginx
4.产看安装
rpm -ql nginx
5.启动nginx
nginx 启动
nginx -s stop 停止
nginx -t 检查语法
nginx -s reload 重新加载配置文件
worker_cpu_affinity [cpumast] 绑定cpu提高缓存命中率 cpumast 00000001 0号cpu 00000010 1号cpu
worker_priority number worker进程优先级 【-20,20】
worker_rlimit_nofile number worker进程所能打开的文件数量上限
daemon on | off on后台启动 off 前台启动
events配置
accept_mutex on | off 处理新的连接请求的方法 on 由各个worker轮训处理请求。 off 唤起所有worker ,然后进行竞争
http相关配置
配置一个虚拟主机
server{
listen address [:port]|port;
server_name:server_name;
root /path/to/document_root;
}
server{
listen address [:port]|port;
ip:ip;
root /path/to/document_root;
}
监听5609端口
server {
listen 5609;
access_log /usr/local/logs/kibana_access.log main;
error_log /usr/local/logs/kibana_error.log error;
location / {
allow 127.0.0.1;
deny all;
proxy_pass http://127.0.0.1:5601; }
}
密码认证登陆
location / {
auth_basic "elk auth";
auth_basic_user_file /etc/nginx/pass/htpasswd;
proxy_pass http://127.0.0.1:5601;
}
printf "elk:$(openssl passwd -1 elk)\n" >/etc/nginx/pass/htpasswd
logstash 安装
1.下载并解压安装包
tar -zxvf logstash-6.5.3.tar.gz
2.更改内存(根据个人机器)
cd /usr/logstash-6.5.3/config
vi jvm.options
-Xms150M
-Xmx150M
3: logstash配置
cd /usr/logstash-6.5.3/config
vim logstash.conf
input {
file {
path => "/usr/local/nginx/logs/kibana_access.log"
}
}
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"] }
}
4.制作启动脚本
nohup /usr/logstash-6.5.3/bin/logstash -f /usr/logstash-6.5.3/config/logstash.conf >> /usr/logstash-6.5.3/log/logstash.log 2>&1 &
chmod -R 755 start.sh
5.启动
1: logstash最简单配置,输入什么,就输出什么,方便我们测试正则表达式 input{
stdin{} }
output{
stdout{
codec=>rubydebug
}
}
2.感受一下提取cron日志
输入日志:Mar 16 15:00:01 elk CROND[6300]: (root) CMD (/usr/lib64/sa/sa1 1 1)
input{
stdin{}
}
filter {
grok {
match => {
"message" => '(?<mydate>[a-zA-Z]+ [0-9]+ [0-9]+:[0-9]+:[0-9]+) .*'
} }
}
output{
stdout{
codec=>rubydebug
}
}
#提取时间
"message" => '(?<mydate>[a-zA-Z]+ [0-9]+ [0-9]+:[0-9]+:[0-9]+) .*'
#提取时间+主机名
"message" => '(?<mydate>[a-zA-Z]+ [0-9]+ [0-9]+:[0-9]+:[0-9]+) (?<myhostname>[^ ]+) .*' #提取时间+主机名+运行用户
"message" => '(?<mydate>[a-zA-Z]+ [0-9]+ [0-9]+:[0-9]+:[0-9]+) (?<myhostname>[^ ]+) CROND\[[0-9]+\]: \((?<myuser>[0-9a-zA-Z]+)\) .*'
#提取时间+主机名+运行用户+运行命令
"message" => '(?<mydate>[a-zA-Z]+ [0-9]+ [0-9]+:[0-9]+:[0-9]+) (?<myhostname>[^ ]+) CROND\[[0-9]+\]: \((?<myuser>[0-9a-zA-Z-]+)\) CMD \((?<mycommand>.*)\)'
3.感受tomcat日志提取
10.251.254.211 - - [16/Mar/2018:15:44:04 +0800] "GET /test HTTP/1.1" 404 1078
#提取ip
"message" => '(?<myip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - .*'
#提取ip+时间
"message" => '(?<myip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - \[(?<mydate>[^ ]+) \+\d+\] ".*' #提取ip+时间+请求方法
"message" => '(?<myip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - \[(?<mydate>[^ ]+) \+\d+\] "(?
<mymethod>[A-Z]+) .*'
#提取ip+时间+请求方法+url+response code+响应大小
"message" => '(?<myip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - \[(?<mydate>[^ ]+) \+\d+\] "(?
<mymethod>[A-Z]+) (?<myurl>[^ ]+) HTTP/\d.\d" (?<myresponsecode>[0-9]+) (?<myresponsesize>[0-9]+)'
4: 正则匹配不了就不输出到elasticsearch output{
if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] {
stdout{
codec=>rubydebug
} }
}
1: 覆盖logstash的日期 filter {
grok {
match => {
"message" => '(?<myip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - \[(?<mydate>[^ ]+) \+\d+\] "(?<mymethod>[A-Z]+) (?<myurl>[^ ]+) HTTP/\d.\d" (?<myresponsecode>[0-9]+) (?<myresponsesize>[0-9]+)'
}
}
date {
match => ["mydate", "dd/MMM/yyyy:HH:mm:ss"]
target => "@timestamp"
} }
#yyyy-MM-dd HH:mm:ss,SSS
#2018-03-16 15:44:04,077
2: 使用logstash自带的常用正则
cat /usr/local/logstash-6.1.1/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
"message" => '%{IP:myip2} - - \[%{HTTPDATE:mydate2}\] "(?<mymethod>[A-Z]+) (?<myurl>[^ ]+) HTTP/\d.\d" (?<myresponsecode>[0-9]+) (?<myresponsesize>[0-9]+)'
16/Mar/2018:15:44:04 +0800
match => ["mydate2", "dd/MMM/yyyy:HH:mm:ss Z"]
3正则提取nginx配置
input {
file {
path => "/usr/local/nginx/logs/kibana_access.log" start_position => "beginning"
sincedb_path => "/dev/null"
} }
filter {
grok {
match => {
"message" => '(?<source_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - [a-zA-Z0-9-]+ \[(?
<nginx_time>[^ ]+) \+\d+\] "(?<method>[A-Z]+) (?<request_url>[^ ]+) HTTP/\d.\d" (?<status>\d+) \d+ " (?<referer>[^"]+)" "(?<agent>[^"]+)" ".*"'
}
remove_field => ["message"]
}
date {
match => ["nginx_time", "dd/MMM/yyyy:HH:mm:ss"]
target => "@timestamp" }
}
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"] }
}
filebeat安装
1.下载并解压安装包
tar -zxvf filebeat-6.5.3-linux-x86_64.tar.gz
2.filebeat的配置文件vim /usr/filebeat-6.5.3-linux-x86_64/filebeat.yml
filebeat:
prospectors:
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/kibana_access.log
output:
elasticsearch:
hosts: ["127.0.0.1:9200"]
3: 启动filebeat(/usr/filebeat-6.5.3-linux-x86_64/start.sh)
nohup /usr/filebeat-6.5.3-linux-x86_64/filebeat -e -c /usr/filebeat-6.5.3-linux-x86_64/filebeat.yml >> /usr/filebeat-6.5.3-linux-x86_64/log/filebeat.log 2>&1 &
chmod -R 777 start.sh
4: 启动 sh start.sh
5: 使用filebeat-开头的去创建索引,filebeat不支持正则提取的功能。
logstash结合filebeat进行日志收集
因此,我们需要结合filebeat的轻量和logstash的正则提取。 logstash -> elasticsearch -> kibana
filebeat -> elasticsearch -> kibana
filebeat -> logstash(需要开启端口监听) -> elastic -> kibana
1: filebeat配置vim /usr/local/filebeat-6.1.1/filebeat.yml filebeat:
prospectors:
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /usr/local/nginx/logs/kibana_access.log
output:
logstash:
hosts: ["127.0.0.1:5044"]
2: logstash配置vim /usr/local/logstash-6.1.1/config/logstash.conf
input {
beats {
host => '127.0.0.1'
port => 5044
} }
filter {
grok {
match => {
"message" => '(?<source_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - [a-zA-Z0-9-]+ \[(?
<nginx_time>[^ ]+) \+\d+\] "(?<method>[A-Z]+) (?<request_url>[^ ]+) HTTP/\d.\d" (?<status>\d+) \d+ " (?<referer>[^"]+)" "(?<agent>[^"]+)" ".*"'
}
remove_field => ["message", "beat"]
}
date {
match => ["nginx_time", "dd/MMM/yyyy:HH:mm:ss"]
target => "@timestamp" }
}
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"] }
}
在filebeat和logstash中引入redis
1.filebeat配置:/usr/local/filebeat-6.1.1/filebeat.yml filebeat:
prospectors:
- input_type: log
tail_files: true
backoff: "1s" #every second check log file paths:
- /usr/local/nginx/logs/kibana_access.log
output:
redis:
hosts: ["127.0.0.1"]
port: 6379
password: 'test1234'
key: 'nginx_log'
2: logstash配置:/usr/local/logstash-6.1.1/config/logstash.conf input {
redis {
host => '127.0.0.1' port => 6379
key => "nginx_log"
data_type => "list"
password => 'test1234'
} }
filter {
grok {
#125.119.2.71 - elk [17/Mar/2018:17:40:11 +0800] "POST /elasticsearch/_msearch HTTP/1.1" 200 9550 "http://144.202.123.228:5609/app/kibana" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36" "-"
match => {
"message" => '(?<source_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - [a-zA-Z0-9-]+ \[(? <nginx_time>[^ ]+) \+\d+\] "(?<method>[A-Z]+) (?<request_url>[^ ]+) HTTP/\d.\d" (?<status>\d+) \d+ " (?<referer>[^"]+)" "(?<agent>[^"]+)" ".*"'
}
remove_field => ["message"]
}
date {
match => ["nginx_time", "dd/MMM/yyyy:HH:mm:ss"]
target => "@timestamp" }
}
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"] }
}
索引自定义
output {
elasticsearch {
hosts => ["http://127.0.0.1:9200"] index => "nginx-%{+YYYY.MM.dd}"
} }
logstash分析多日志
1: filebeat读取多个日志文件配置
filebeat:
prospectors:
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/messages
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/cron
output:
logstash:
hosts: ["127.0.0.1:5044"]
2: logstash的输出观察
input {
beats {
host => '127.0.0.1'
port => 5044
}
}
output{
stdout{
codec=>rubydebug
}
}
3: filebeat增加字段(观察输出)
filebeat:
prospectors:
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/messages
fields:
type: messages
- input_type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/cron
fields:
type: cron
output:
logstash:
hosts: ["127.0.0.1:5044"]
4: logstash通过source来区分不同的日志文件,output和filter里面均可以做判断
#May 27 02:25:49 guest crontab[1704]: PAM pam_end: NULL pam handle passed
input {
beats {
host => '127.0.0.1'
port => 5044
}
}
filter {
if [source] == "/var/log/cron" {
grok {
match => {
"message" => '(?<crondate>[a-zA-Z]+ \d+ \d+:\d+:\d+) .*'
}
}
}
}
output{
if [source] == "/var/log/cron" {
stdout{
codec=>rubydebug
}
}else if [source] == "/var/log/messages" {
file{
path=>"/tmp/shijiange.log"
}
}
}
5: logstash通过filelds字段进行判断
input {
beats {
host => '127.0.0.1'
port => 5044
}
}
output{
if [fields][type] == "cron" {
elasticsearch {
hosts => ["http://127.0.0.1:9200"]
index => "cron-%{+YYYY.MM.dd}"
}
}else if [fields][type] == "messages" {
elasticsearch {
hosts => ["http://127.0.0.1:9200"]
index => "messages-%{+YYYY.MM.dd}"
}
}
}
 文章浏览阅读3.7k次,点赞2次,收藏5次。Nginx学习笔记一、N...
文章浏览阅读3.7k次,点赞2次,收藏5次。Nginx学习笔记一、N... 文章浏览阅读1.7w次,点赞14次,收藏61次。我们在使用容器的...
文章浏览阅读1.7w次,点赞14次,收藏61次。我们在使用容器的...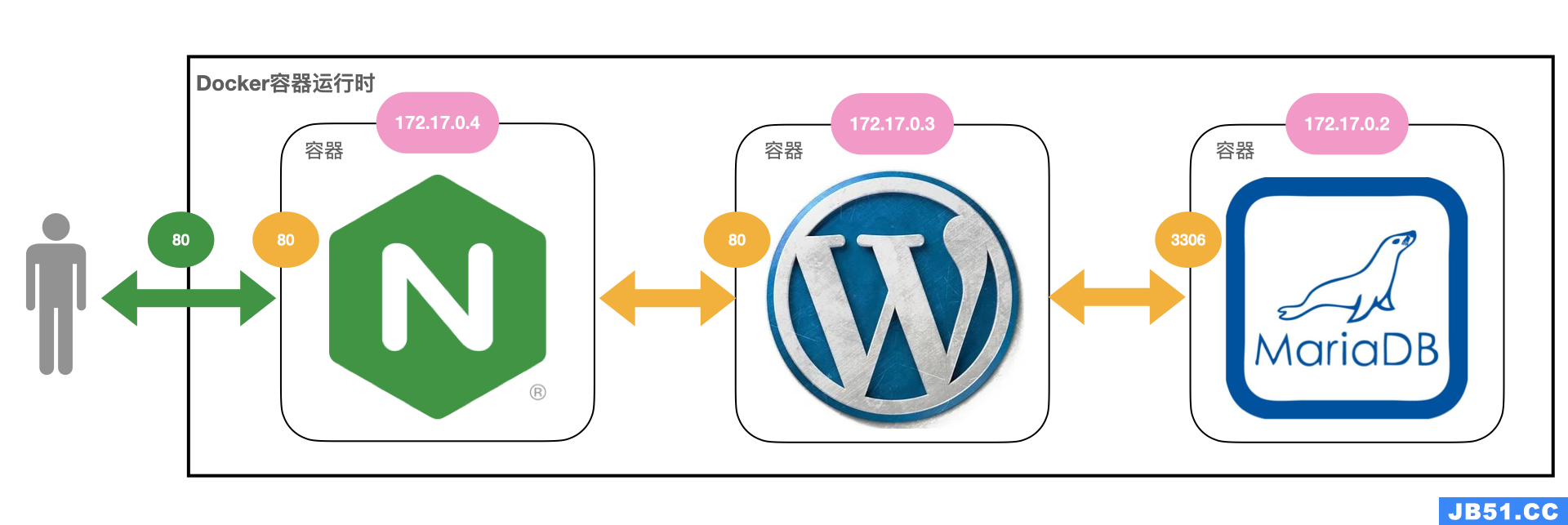 文章浏览阅读2.7k次。docker 和 docker-compose 部署 nginx+...
文章浏览阅读2.7k次。docker 和 docker-compose 部署 nginx+...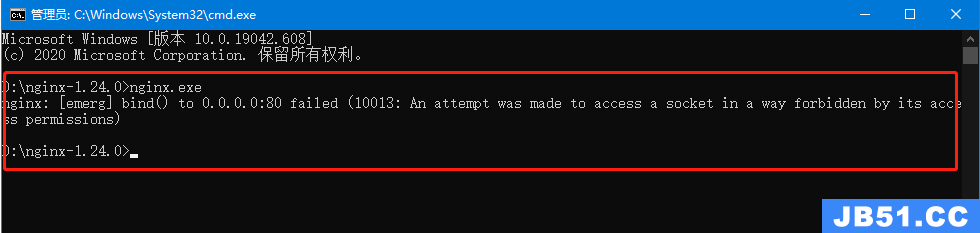 文章浏览阅读1.3k次。5:再次启动nginx,可以正常启动,可以...
文章浏览阅读1.3k次。5:再次启动nginx,可以正常启动,可以... 文章浏览阅读3.1w次,点赞105次,收藏182次。高性能:Nginx ...
文章浏览阅读3.1w次,点赞105次,收藏182次。高性能:Nginx ...