前言
System.Text.RegularExpressions 命名空间已经在 .NET 中使用了多年,一直追溯到 .NET Framework 1.1。它在 .NET 实施本身的数百个位置中使用,并且直接被成千上万个应用程序使用。在所有这些方面,它也是 CPU 消耗的重要来源。
但是,从性能角度来看,正则表达式在这几年间并没有获得太多关注。在 2006 年的 .NET Framework 2.0 中更改了其缓存策略。 .NET Core 2.0 在 RegexOptions.Compiled 之后看到了这个实现的到来(在 .NET Core 1.x 中,RegexOptions.Compiled 选项是一个 nop)。 .NET Core 3.0 受益于 Regex 内部的一些内部更新,以在某些情况下利用 Span<T> 提高内存利用率。在此过程中,一些非常受欢迎的社区贡献改进了目标区域,例如 dotnet/corefx#32899,它减少了使用表达式 RegexOptions.Compiled | RegexOptions.IgnoreCase 时对CultureInfo.CurrentCulture 的访问。但除此之外,实施很大程度上还是在15年前。
对于 .NET 5(本周发布了 Preview 2),我们已对 Regex 引擎进行了一些重大改进。在我们尝试过的许多表达式中,这些更改通常会使吞吐量提高3到6倍,在某些情况下甚至会提高更多。在本文中,我将逐步介绍 .NET 5 中 System.Text.RegularExpressions 进行的许多更改。这些更改对我们自己的使用产生了可衡量的影响,我们希望这些改进将带来可衡量的胜利在您的库和应用中。
Regex内部知识
要了解所做的某些更改,了解一些Regex内部知识很有帮助。
Regex构造函数完成所有工作,以采用正则表达式模式并准备对其进行匹配输入:
-
RegexParser。该模式被送入内部RegexParser类型,该类型理解正则表达式语法并将其解析为节点树。例如,表达式a|bcd被转换为具有两个子节点的“替代”RegexNode,一个子节点表示单个字符a,另一个子节点表示“多个”bcd。解析器还对树进行优化,将一棵树转换为另一个等效树,以提供更有效的表示和/或可以更高效地执行该树。 -
RegexWriter。节点树不是执行匹配的理想表示,因此解析器的输出将馈送到内部RegexWriter类,该类会写出一系列紧凑的操作码,以表示执行匹配的指令。这种类型的名称是“ writer”,因为它“写”出了操作码。其他引擎通常将其称为“编译”,但是 .NET 引擎使用不同的术语,因为它保留了“编译”术语,用于 MSIL 的可选编译。 -
RegexCompiler(可选)。如果未指定RegexOptions.Compiled选项,则内部RegexInterpreter类稍后在匹配时使用RegexWriter输出的操作码来解释/执行执行匹配的指令,并且在Regex构造过程中不需要任何操作。但是,如果指定了RegexOptions.Compiled,则构造函数将获取先前输出的资产,并将其提供给内部RegexCompiler类。然后,RegexCompiler使用反射发射生成MSIL,该MSIL表示解释程序将要执行的工作,但专门针对此特定表达式。例如,当与模式中的字符“ c”匹配时,解释器将需要从变量中加载比较值,而编译器会将“ c”硬编码为生成的IL中的常量。
一旦构造了正则表达式,就可以通过IsMatch,Match,Matches,Replace和Split等实例方法将其用于匹配(Match返回Match对象,该对象公开了NextMatch方法,该方法可以迭代匹配并延迟计算) 。这些操作最终以“扫描”循环(某些其他引擎将其称为“传输”循环)结束,该循环本质上执行以下操作:
while (FindFirstChar())
{
Go();
if (_match != null)
return _match;
_pos++;
}
return null;
_pos是我们在输入中所处的当前位置。virtual FindFirstChar从_pos开始,并在输入文本中查找正则表达式可能匹配的第一位;这并不是执行完整引擎,而是尽可能高效地进行搜索,以找到值得运行完整引擎的位置。 FindFirstChar可以最大程度地减少误报,并且找到有效位置的速度越快,表达式的处理速度就越快。如果找不到合适的起点,则可能没有任何匹配,因此我们完成了。如果找到了一个好的起点,它将更新_pos,然后通过调用virtual Go来在找到的位置执行引擎。如果Go找不到匹配项,我们会碰到当前位置并重新开始,但是如果Go找到匹配项,它将存储匹配信息并返回该数据。显然,执行Go的速度也越快越好。
所有这些逻辑都在公共RegexRunner基类中。 RegexInterpreter派生自RegexRunner,并用解释正则表达式的实现覆盖FindFirstChar和Go,这由RegexWriter生成的操作码表示。 RegexCompiler使用DynamicMethods生成两种方法,一种用于FindFirstChar,另一种用于Go。委托是从这些创建的、从RegexRunner派生的另一种类型调用。
.NET 5的改进
在本文的其余部分中,我们将逐步介绍针对 .NET 5 中的 Regex 进行的各种优化。这不是详尽的清单,但它突出了一些最具影响力的更改。
CharInClass
正则表达式支持“字符类”,它们定义了输入字符应该或不应该匹配的字符集,以便将该位置视为匹配字符。字符类用方括号表示。这里有些例子:
-
[abc]匹配“ a”,“ b”或“ c”。 -
[^\n]匹配换行符以外的任何字符。 (除非指定了RegexOptions.Singleline,否则这是您在表达式中使用的确切字符类。) -
[a-cx-z]匹配“ a”,“ b”,“ c”,“ x”,“ y”或“ z”。 -
[\d\s\p{IsGreek}]匹配任何Unicode数字,空格或希腊字符。 (与大多数其他正则表达式引擎相比,这是一个有趣的区别。例如,在其他引擎中,默认情况下,\d通常映射到[0-9],您可以选择加入,而不是映射到所有Unicode数字,即[\p{Nd}],而在.NET中,您默认情况下会使用后者,并使用RegexOptions.ECMAScript选择退出。)
当将包含字符类的模式传递给Regex构造函数时,RegexParser的工作之一就是将该字符类转换为可以在运行时更轻松地查询的字符。解析器使用内部RegexCharClass类型来解析字符类,并从本质上提取三件事(还有更多东西,但这对于本次讨论就足够了):
- 模式是否被否定
- 匹配字符范围的排序集
- 匹配字符的Unicode类别的排序集
这是所有实现的详细信息,但是该信息然后保留在字符串中,该字符串可以传递给受保护的 RegexRunner.CharInClass 方法,以确定字符类中是否包含给定的Char。
在.NET 5之前,每一次需要将一个字符与一个字符类进行匹配时,它将调用该CharInClass方法。然后,CharInClass对范围进行二进制搜索,以确定指定字符是否存储在一个字符中;如果不存储,则获取目标字符的Unicode类别,并对Unicode类别进行线性搜索,以查看是否匹配。因此,对于^\d*$之类的表达式(断言它在行的开头,然后匹配任意数量的Unicode数字,然后断言在行的末尾),假设输入了1000位数字,这加起来将对CharInClass进行1000次调用。
在 .NET 5 中,我们现在更加聪明地做到了这一点,尤其是在使用RegexOptions.Compiled时,通常,只要开发人员非常关心Regex的吞吐量,就可以使用它。一种解决方案是,对于每个字符类,维护一个查找表,该表将输入字符映射到有关该字符是否在类中的是/否决定。虽然我们可以这样做,但是System.Char是一个16位的值,这意味着每个字符一个位,我们需要为每个字符类使用8K查找表,并且这还要累加起来。取而代之的是,我们首先尝试使用平台中的现有功能或通过简单的数学运算来快速进行匹配,以处理一些常见情况。例如,对于\d,我们现在不生成对RegexRunner.CharInClass(ch,charClassString) 的调用,而是仅生成对 char.IsDigit(ch)的调用。 IsDigit已经使用查找表进行了优化,可以内联,并且性能非常好。类似地,对于\s,我们现在生成对char.IsWhitespace(ch)的调用。对于仅包含几个字符的简单字符类,我们将生成直接比较,例如对于[az],我们将生成等价于(ch =='a') | (ch =='z')。对于仅包含单个范围的简单字符类,我们将通过一次减法和比较来生成检查,例如[a-z]导致(uint)ch-'a'<= 26,而 [^ 0-9] 导致 !((uint)c-'0'<= 10)。我们还将特殊情况下的其他常见规范;例如,如果整个字符类都是一个Unicode类别,我们将仅生成对char.GetUnicodeInfo(也具有快速查找表)的调用,然后进行比较,例如[\p{Lu}]变为char.GetUnicodeInfo(c)== UnicodeCategory.UppercaseLetter。
当然,尽管涵盖了许多常见情况,但当然并不能涵盖所有情况。而且,因为我们不想为每个字符类生成8K查找表,并不意味着我们根本无法生成查找表。相反,如果我们没有遇到这些常见情况之一,那么我们确实会生成一个查找表,但仅针对ASCII,它只需要16个字节(128位),并且考虑到正则表达式中的典型输入,这往往是一个很好的折衷方案基于方案。由于我们使用DynamicMethod生成方法,因此我们不容易将附加数据存储在程序集的静态数据部分中,但是我们可以做的就是利用常量字符串作为数据存储; MSIL具有用于加载常量字符串的操作码,并且反射发射对生成此类指令具有良好的支持。因此,对于每个查找表,我们只需创建所需的8个字符的字符串,用不透明的位图数据填充它,然后在IL中用ldstr吐出。然后我们可以像对待其他任何位图一样对待它,例如为了确定给定的字符是否匹配,我们生成以下内容:
bool result = ch < 128 ? (lookup[c >> 4] & (1 << (c & 0xF))) != 0 : NonAsciiFallback;
换句话说,我们使用字符的高三位选择查找表字符串中的第0至第7个字符,然后使用低四位作为该位置16位值的索引; 如果是1,则表示匹配,如果不是,则表示没有匹配。 对于大于等于128的字符,我们需要一个回退,根据对字符类进行的一些分析,回退可能是各种各样的事情。 最糟糕的情况是,回退只是对RegexRunner.CharInClass的调用,否则我们会做得更好。 例如,很常见的是,我们可以从输入模式中得知所有可能的匹配项均小于<128,在这种情况下,我们根本不需要回退,例如 对于字符类[0-9a-fA-F](又称十六进制),我们将生成以下内容:
bool result = ch < 128 && (lookup[c >> 4] & (1 << (c & 0xF))) != 0;
相反,我们可以确定127以上的每个字符都将去匹配。 例如,字符类[^aeiou](除ASCII小写元音外的所有字符)将产生与以下代码等效的代码:
bool result = ch >= 128 || (lookup[c >> 4] & (1 << (c & 0xF))) != 0;
等等。
以上都是针对RegexOptions.Compiled,但解释表达式并不会被冷落。 对于解释表达式,我们当前会生成一个类似的查找表,但是我们这样做是很懒惰的,第一次看到给定输入字符时会填充该表,然后针对该字符类针对该字符的所有将来评估存储该答案。 (我们可能会重新研究如何执行此操作,但这是从 .NET 5 Preview 2 开始存在的方式。)
这样做的最终结果可能是频繁评估字符类的表达式的吞吐量显着提高。 例如,这是一个微基准测试,可将ASCII字母和数字与具有62个此类值的输入进行匹配:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("[a-zA-Z0-9]*",RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("abcdefghijklmnopqrstuvwxyz123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ");
}
这是我的项目文件:
<project Sdk="Microsoft.NET.Sdk">
<propertygroup>
<langversion>preview</langversion>
<outputtype>Exe</outputtype>
<targetframeworks>netcoreapp5.0;netcoreapp3.1</targetframeworks>
</propertygroup>
<itemgroup>
<packagereference Include="benchmarkdotnet" Version="0.12.0.1229"></packagereference>
</itemgroup>
</project>
在我的计算机上,我有两个目录,一个包含.NET Core 3.1,一个包含.NET 5的内部版本(此处标记为master,因为它是dotnet/runtime的master分支的内部版本)。 当我执行以上操作针对两个版本运行基准测试:
dotnet run -c Release -f netcoreapp3.1 --filter ** --corerun d:\coreclrtest\netcore31\corerun.exe d:\coreclrtest\master\corerun.exe
我得到了以下结果:
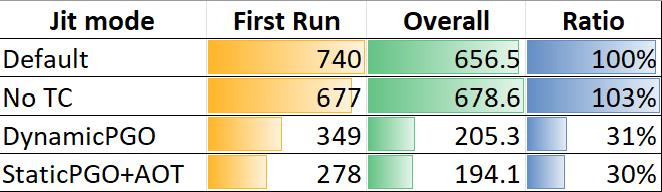
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 102.3 ns | 1.33 ns | 1.24 ns | 0.17 |
| IsMatch | \netcore31\corerun.exe | 585.7 ns | 2.80 ns | 2.49 ns | 1.00 |
开发人员可能会写的代码生成器
如前所述,当RegexOptions.Compiled与Regex一起使用时,我们使用反射发射为其生成两种方法,一种实现FindFirstChar,另一种实现Go。 为了支持回溯,Go最终包含了很多通常不需要的代码。 生成代码的方式通常包括不必要的字段读取和写入,导致检查JIT无法消除的边界等。 在 .NET 5 中,我们改进了为许多表达式生成的代码。
考虑表达式@"a\sb",它匹配一个'a',任何Unicode空格和一个'b'。 以前,反编译为Go发出的IL看起来像这样:
public override void Go()
{
string runtext = base.runtext;
int runtextstart = base.runtextstart;
int runtextbeg = base.runtextbeg;
int runtextend = base.runtextend;
int num = runtextpos;
int[] runtrack = base.runtrack;
int runtrackpos = base.runtrackpos;
int[] runstack = base.runstack;
int runstackpos = base.runstackpos;
CheckTimeout();
runtrack[--runtrackpos] = num;
runtrack[--runtrackpos] = 0;
CheckTimeout();
runstack[--runstackpos] = num;
runtrack[--runtrackpos] = 1;
CheckTimeout();
if (num < runtextend && runtext[num++] == 'a')
{
CheckTimeout();
if (num < runtextend && RegexRunner.CharInClass(runtext[num++],"\0\0\u0001d"))
{
CheckTimeout();
if (num < runtextend && runtext[num++] == 'b')
{
CheckTimeout();
int num2 = runstack[runstackpos++];
Capture(0,num2,num);
runtrack[--runtrackpos] = num2;
runtrack[--runtrackpos] = 2;
goto IL_0131;
}
}
}
while (true)
{
base.runtrackpos = runtrackpos;
base.runstackpos = runstackpos;
EnsureStorage();
runtrackpos = base.runtrackpos;
runstackpos = base.runstackpos;
runtrack = base.runtrack;
runstack = base.runstack;
switch (runtrack[runtrackpos++])
{
case 1:
CheckTimeout();
runstackpos++;
continue;
case 2:
CheckTimeout();
runstack[--runstackpos] = runtrack[runtrackpos++];
Uncapture();
continue;
}
break;
}
CheckTimeout();
num = runtrack[runtrackpos++];
goto IL_0131;
IL_0131:
CheckTimeout();
runtextpos = num;
}
那里有很多东西,需要斜视和搜索才能将实现的核心看作方法的中间几行。 现在在.NET 5中,相同的表达式导致生成以下代码:
protected override void Go()
{
string runtext = base.runtext;
int runtextend = base.runtextend;
int runtextpos;
int start = runtextpos = base.runtextpos;
ReadOnlySpan<char> readOnlySpan = runtext.AsSpan(runtextpos,runtextend - runtextpos);
if (0u < (uint)readOnlySpan.Length && readOnlySpan[0] == 'a' &&
1u < (uint)readOnlySpan.Length && char.IsWhiteSpace(readOnlySpan[1]) &&
2u < (uint)readOnlySpan.Length && readOnlySpan[2] == 'b')
{
Capture(0,start,base.runtextpos = runtextpos + 3);
}
}
如果您像我一样,则可以注视着眼睛看第一个版本,但是如果您看到第二个版本,则可以真正阅读并了解它的功能。 除了易于理解和易于调试之外,它还减少了执行的代码,消除了边界检查,减少了对字段和数组的读写等方面的工作。 最终的结果是它的执行速度也快得多。 (这里还有进一步改进的可能性,例如删除两个长度检查,可能会重新排序一些检查,但总的来说,它比以前有了很大的改进。)
向量化的基于 Span 的搜索
正则表达式都是关于搜索内容的。 结果,我们经常发现自己正在运行循环以寻找各种事物。 例如,考虑表达式 hello.*world。 以前,如果要反编译我们在Go方法中生成的用于匹配.*的代码,则该代码类似于以下内容:
while (--num3 > 0)
{
if (runtext[num++] == '\n')
{
num--;
break;
}
}
换句话说,我们将手动遍历输入文本字符串,逐个字符地查找 \n(请记住,默认情况下,.表示“ \n以外的任何内容”,因此.*表示“匹配所有内容,直到找到\n” )。 但是,.NET早已拥有完全执行此类搜索的方法,例如IndexOf,并且从最新版本开始,IndexOf是矢量化的,因此它可以同时比较多个字符,而不仅仅是单独查看每个字符。 现在,在.NET 5中,我们不再像上面那样生成代码,而是得到如下代码:
num2 = runtext.AsSpan(runtextpos,num).IndexOf('\n');
使用IndexOf而不是生成我们自己的循环,则意味着对Regex中的此类搜索进行隐式矢量化,并且对此类实现的任何改进也都应归于此。 这也意味着生成的代码更简单。 可以用这样的基准测试来查看其影响:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("hello.*world",RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("hello. this is a test to see if it's able to find something more quickly in the world.");
}
即使输入的字符串不是特别大,也会产生可衡量的影响:
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 71.03 ns | 0.308 ns | 0.257 ns | 0.47 |
| IsMatch | \netcore31\corerun.exe | 149.80 ns | 0.913 ns | 0.809 ns | 1.00 |
IndexOfAny最终还是.NET 5实现中的重要工具,尤其是对于FindFirstChar的实现。 .NET Regex实现使用的现有优化之一是对可以开始表达式的所有可能字符进行分析。 生成一个字符类,然后FindFirstChar使用该字符类对可能开始匹配的下一个位置生成搜索。 这可以通过查看表达式([ab]cd|ef [g-i])jklm的生成代码的反编译版本来看到。 与该表达式的有效匹配只能以'a','b'或'e'开头,因此优化器生成一个字符类[abe],FindFirstChar然后使用:
public override bool FindFirstChar()
{
int num = runtextpos;
string runtext = base.runtext;
int num2 = runtextend - num;
if (num2 > 0)
{
int result;
while (true)
{
num2--;
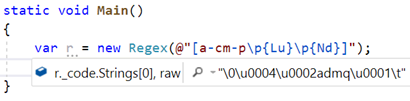
if (!RegexRunner.CharInClass(runtext[num++],"\0\u0004\0acef"))
{
if (num2 <= 0)
{
result = 0;
break;
}
continue;
}
num--;
result = 1;
break;
}
runtextpos = num;
return (byte)result != 0;
}
return false;
}
这里需要注意的几件事:
-
正如前面所讨论的,我们可以看到每个字符都是通过
CharInClass求值的。 我们可以看到传递给CharInClass的字符串是该类的内部可搜索表示(第一个字符表示没有取反,第二个字符表示有四个用于表示范围的字符,第三个字符表示没有Unicode类别) ,然后接下来的四个字符代表两个范围,分别包含下限和上限。 -
我们可以看到我们分别评估每个字符,而不是能够一起评估多个字符。
-
我们只看第一个字符,如果匹配,我们退出以允许引擎完全执行
Go。
在.NET 5 Preview 2中,我们现在生成此代码:
protected override bool FindFirstChar()
{
int runtextpos = base.runtextpos;
int runtextend = base.runtextend;
if (runtextpos <= runtextend - 7)
{
ReadOnlySpan<char> readOnlySpan = runtext.AsSpan(runtextpos,runtextend - runtextpos);
for (int num = 0; num < readOnlySpan.Length - 2; num++)
{
int num2 = readOnlySpan.Slice(num).IndexOfAny('a','b','e');
num = num2 + num;
if (num2 < 0 || readOnlySpan.Length - 2 <= num)
{
break;
}
int num3 = readOnlySpan[num + 1];
if ((num3 == 'c') | (num3 == 'f'))
{
num3 = readOnlySpan[num + 2];
if (num3 < 128 && ("\0\0\0\0\0\0ΐ\0"[num3 >> 4] & (1 << (num3 & 0xF))) != 0)
{
base.runtextpos = runtextpos + num;
return true;
}
}
}
}
base.runtextpos = runtextend;
return false;
}
这里要注意一些有趣的事情:
-
现在,我们使用
IndexOfAny搜索三个目标字符。IndexOfAny是矢量化的,因此它可以利用SIMD指令一次比较多个字符,并且我们为进一步优化IndexOfAny所做的任何未来改进都将隐式归于此类FindFirstChar实现。 -
如果
IndexOfAny找到匹配项,我们不只是立即返回以给Go机会执行。相反,我们对接下来的几个字符进行快速检查,以增加这实际上是匹配项的可能性。在原始表达式中,您可以看到可能与第二个字符匹配的唯一值是'c'和'f',因此该实现对这些字符进行了快速比较检查。您会看到第三个字符必须与'd'或[g-i]匹配,因此该实现将这些字符组合到单个字符类[dg-i]中,然后使用位图对其进行评估。后两个字符检查都突出了我们现在为字符类发出的改进的代码生成。
我们可以在这样的测试中看到这种潜在的影响:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System;
using System.Linq;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private static Random s_rand = new Random(42);
private Regex _regex = new Regex("([ab]cd|ef[g-i])jklm",RegexOptions.Compiled);
private string _input = string.Concat(Enumerable.Range(0,1000).Select(_ => (char)('a' + s_rand.Next(26))));
[Benchmark] public bool IsMatch() => _regex.IsMatch(_input);
}
在我的机器上会产生以下结果:
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 1.084 us | 0.0068 us | 0.0061 us | 0.08 |
| IsMatch | \netcore31\corerun.exe | 14.235 us | 0.0620 us | 0.0550 us | 1.00 |
先前的代码差异也突出了另一个有趣的改进,特别是旧代码的int num2 = runtextend-num;`` if(num2> 0)和新代码的if(runtextpos <= runtextend-7)之间的差异。。如前所述,RegexParser将输入模式解析为节点树,然后对其进行分析和优化。 .NET 5包括各种新的分析,有些简单,有些更复杂。较简单的示例之一是解析器现在将对表达式进行快速扫描,以确定是否必须有最小输入长度才能匹配输入。考虑一下表达式[0-9]{3}-[0-9]{2}-[0-9]{4},该表达式可用于匹配美国的社会保险号(三个ASCII数字,破折号,两个ASCII数字,一个破折号,四个ASCII数字)。我们可以很容易地看到,此模式的任何有效匹配都至少需要11个字符;如果为我们提供了10个或更少的输入,或者如果我们在输入末尾找到10个字符以内却没有找到匹配项,那么我们可能会立即使匹配项失败而无需进一步进行,因为这是不可能的匹配。
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Diagnosers;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private readonly Regex _regex = new Regex("[0-9]{3}-[0-9]{2}-[0-9]{4}",RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("123-45-678");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 19.39 ns | 0.148 ns | 0.139 ns | 0.04 |
| IsMatch | \netcore31\corerun.exe | 459.86 ns | 1.893 ns | 1.771 ns | 1.00 |
回溯消除
.NET Regex实现当前使用回溯引擎。这种实现可以支持基于DFA的引擎无法轻松或有效地支持的各种功能,例如反向引用,并且在内存利用率以及常见情况下的吞吐量方面都非常高效。但是,回溯有一个很大的缺点,那就是可能导致退化的情况,即匹配在输入长度上花费了指数时间。这就是.NET Regex类公开设置超时的功能的原因,因此失控匹配可能会被异常中断。
.NET文档提供了更多详细信息,但可以这样说,开发人员可以编写正则表达式,而不会受到过多的回溯。一种方法是采用“原子组”,该原子组告诉引擎,一旦组匹配,实现就不得回溯到它,通常在这种回溯不会带来好处的情况下使用。考虑与输入aaaa匹配的示例表达式a+b:
-
Go引擎开始匹配a+。此操作是贪婪的,因此它匹配第一个a,然后匹配aa,然后匹配aaa,然后匹配aaaa。然后,它会显示在输入的末尾。 -
没有
b匹配,因此引擎回溯1,而a+现在匹配aaa。 -
仍然没有
b匹配,因此引擎回溯1,而a+现在匹配aa。 -
仍然没有
b匹配,因此引擎回溯1,而a+现在匹配a。 -
仍然没有
b可以匹配,而a+至少需要1个a,因此匹配失败。
但是,所有这些回溯都被证明是不必要的。 a+不能匹配b可以匹配的东西,因此在这里进行大量的回溯是不会有成果的。看到这一点,开发人员可以改用表达式(?>a+)b。 (?>和)是原子组的开始和结束,它表示一旦该组匹配并且引擎经过该组,则它一定不能回溯到该组中。然后,使用我们之前针对aaaa进行匹配的示例,则将发生这种情况:
-
Go引擎开始匹配
a+。此操作是贪婪的,因此它匹配第一个a,然后匹配aa,然后匹配aaa,然后匹配aaaa。然后,它会显示在输入的末尾。 -
没有匹配的b,因此匹配失败。
简短得多,这只是一个简单的示例。因此,开发人员可以自己进行此分析并找到手动插入原子组的位置,但是,实际上,有多少开发人员认为这样做或花费时间呢?
相反,.NET 5现在将正则表达式作为节点树优化阶段的一部分进行分析,在发现原子组不会产生语义差异但可以帮助避免回溯的地方添加原子组。例如:
a+b将变成(?>a+)b1,因为没有任何a+可以“回馈”与b相匹配的内容
\d+\s*将变成(?>\d+)(?>\s*),因为没有任何可以匹配\d的东西也可以匹配\s,并且\s在表达式的末尾。
a*([xyz]|hello)将变为(?>a*)([xyz]|hello),因为在成功匹配中,a可以跟着x,y,z或h,并且没有与任何这些重叠。
这只是.NET 5现在将执行的树重写的一个示例。它将进行其他重写,部分目的是消除回溯。例如,现在它将合并彼此相邻的各种形式的循环。考虑退化的例子a*a*a*a*a*a*a*b。在.NET 5中,现在将其重写为功能上等效的a*b,然后根据前面的讨论将其进一步重写为(?>a*)b。这将潜在的非常昂贵的执行转换为具有线性执行时间的执行。由于我们正在处理不同的算法复杂性,因此显示示例基准几乎没有意义,但是无论如何我还是会这样做,只是为了好玩:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("a*a*a*a*a*a*a*b",RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("aaaaaaaaaaaaaaaaaaaaa");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 379.2 ns | 2.52 ns | 2.36 ns | 0.000 |
| IsMatch | \netcore31\corerun.exe | 22,367,426.9 ns | 123,981.09 ns | 115,971.99 ns | 1.000 |
回溯减少不仅限于循环。轮换表示回溯的另一个来源,因为实现方式的匹配方式与您手动匹配时的方式类似:尝试一个轮换分支并继续进行,如果匹配失败,请返回并尝试下一个分支,依此类推。因此,减少交替产生的回溯也是有用的。
现在执行的此类重写之一与交替前缀分解有关。考虑针对文本什么是表达式(?:this|that)的表达式。引擎将匹配内容,然后尝试与此匹配。它不会匹配,因此它将回溯并尝试与此匹配。但是交替的两个分支都以th开头。如果我们将其排除在外,然后将表达式重写为th(?:is|at),则现在可以避免回溯。引擎将匹配,然后尝试将th与它匹配,然后失败,仅此而已。
这种优化还最终使更多文本暴露给FindFirstChar使用的现有优化。如果模式的开头有多个固定字符,则FindFirstChar将使用Boyer-Moore实现在输入字符串中查找该文本。暴露给Boyer-Moore算法的模式越大,在快速找到匹配并最小化将导致FindFirstChar退出到Go引擎的误报中所能做的越好。通过从这种交替中拉出文本,在这种情况下,我们增加了Boyer-Moore可用的文本量。
作为另一个相关示例,.NET 5现在发现即使开发人员未指定也可以隐式锚定表达式的情况,这也有助于消除回溯。考虑用*hello匹配abcdefghijk。该实现将从位置0开始,并在该位置计算表达式。这样做会将整个字符串abcdefghijk与.*匹配,然后从那里回溯以尝试匹配hello,这将无法完成。引擎将使匹配失败,然后我们将升至下一个位置。然后,引擎将把字符串bcdefghijk的其余部分与.*进行匹配,然后从那里回溯以尝试匹配hello,这将再次失败。等等。在这里观察到的是,通过碰到下一个位置进行的重试通常不会成功,并且表达式可以隐式地锚定为仅在行的开头匹配。然后,FindFirstChar可以跳过可能不匹配的位置,并避免在这些位置尝试进行引擎匹配。
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Diagnosers;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private readonly Regex _regex = new Regex(@".*text",RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("This is a test.\nDoes it match this?\nWhat about this text?");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 644.1 ns | 3.63 ns | 3.39 ns | 0.21 |
| IsMatch | \netcore31\corerun.exe | 3,024.9 ns | 22.66 ns | 20.09 ns | 1.00 |
(只是为了清楚起见,许多正则表达式仍将在 .NET 5 中采用回溯,因此开发人员仍然需要谨慎运行不可信的正则表达式。)
Regex.* 静态方法和并发
Regex类同时公开实例方法和静态方法。静态方法主要是为了方便起见,因为它们仍然需要在Regex实例上使用和操作。每次使用这些静态方法之一时,该实现都可以实例化一个新的Regex并经历完整的解析/优化/代码生成例程,但是在某些情况下,这将浪费大量的时间和空间。相反,Regex会保留最近使用的Regex对象的缓存,并按使它们唯一的所有内容(例如,模式,RegexOptions甚至在CurrentCulture下(因为这可能会影响IgnoreCase匹配)。此缓存的大小受到限制,以Regex.CacheSize为上限,因此该实现采用了最近最少使用的(LRU)缓存:当缓存已满并且需要添加另一个Regex时,实现将丢弃最近最少使用的项。缓存。
实现这种LRU缓存的一种简单方法是使用链接列表:每次访问某项时,它都会从列表中删除并重新添加到最前面。但是,这种方法有一个很大的缺点,尤其是在并发世界中:同步。如果每次读取实际上都是一个突变,则我们需要确保并发读取(并发突变)不会破坏列表。这样的列表正是.NET早期版本所采用的列表,并且使用了全局锁来保护它。在.NET Core 2.1中,社区成员提交的一项不错的更改通过允许访问最近使用的无锁项在某些情况下对此进行了改进,从而提高了通过静态使用相同Regex的工作负载的吞吐量和可伸缩性。方法反复。但是,对于其他情况,实现仍然锁定在每种用法上。
通过查看诸如Concurrency Visualizer之类的工具,可以看到此锁定的影响,该工具是Visual Studio的扩展,可在其扩展程序库中使用。通过在分析器下运行这样的示例应用程序:
using System.Text.RegularExpressions;
using System.Threading.Tasks;
class Program
{
static void Main()
{
Parallel.Invoke(
() => { while (true) Regex.IsMatch("abc","^abc$"); },() => { while (true) Regex.IsMatch("def","^def$"); },() => { while (true) Regex.IsMatch("ghi","^ghi$"); },() => { while (true) Regex.IsMatch("jkl","^jkl$"); });
}
}
我们可以看到这样的图像:

每行都是一个线程,它是此Parallel.Invoke的一部分。 绿色区域是线程实际执行代码的时间。 黄色区域表示操作系统已抢占该线程的原因,因为该线程需要内核运行另一个线程。 红色区域表示线程被阻止等待某物。 在这种情况下,所有红色是因为线程正在等待Regex缓存中的共享全局锁。
在.NET 5中,图片看起来像这样:

注意,没有更多的红色部分。 这是因为缓存已被重写为完全无锁的读取; 唯一获得锁的时间是将新的Regex添加到缓存中,但是即使发生这种情况,其他线程也可以继续从缓存中读取实例并使用它们。 这意味着,只要为应用程序及其常规使用的Regex静态方法正确调整Regex.CacheSize的大小,此类访问将不再招致它们过去的延迟。 到今天为止,该值默认为15,但是该属性具有设置器,因此可以对其进行更改以更好地满足应用程序的需求。
静态方法的分配也得到了改进,方法是精确地更改缓存内容,从而避免分配不必要的包装对象。 我们可以通过上一个示例的修改版本看到这一点:
using System.Text.RegularExpressions;
using System.Threading.Tasks;
class Program
{
static void Main()
{
Parallel.Invoke(
() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("abc",() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("def",() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("ghi",() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("jkl","^jkl$"); });
}
}
使用Visual Studio中的.NET对象分配跟踪工具运行它。 左边是.NET Core 3.1,右边是.NET 5 Preview 2:
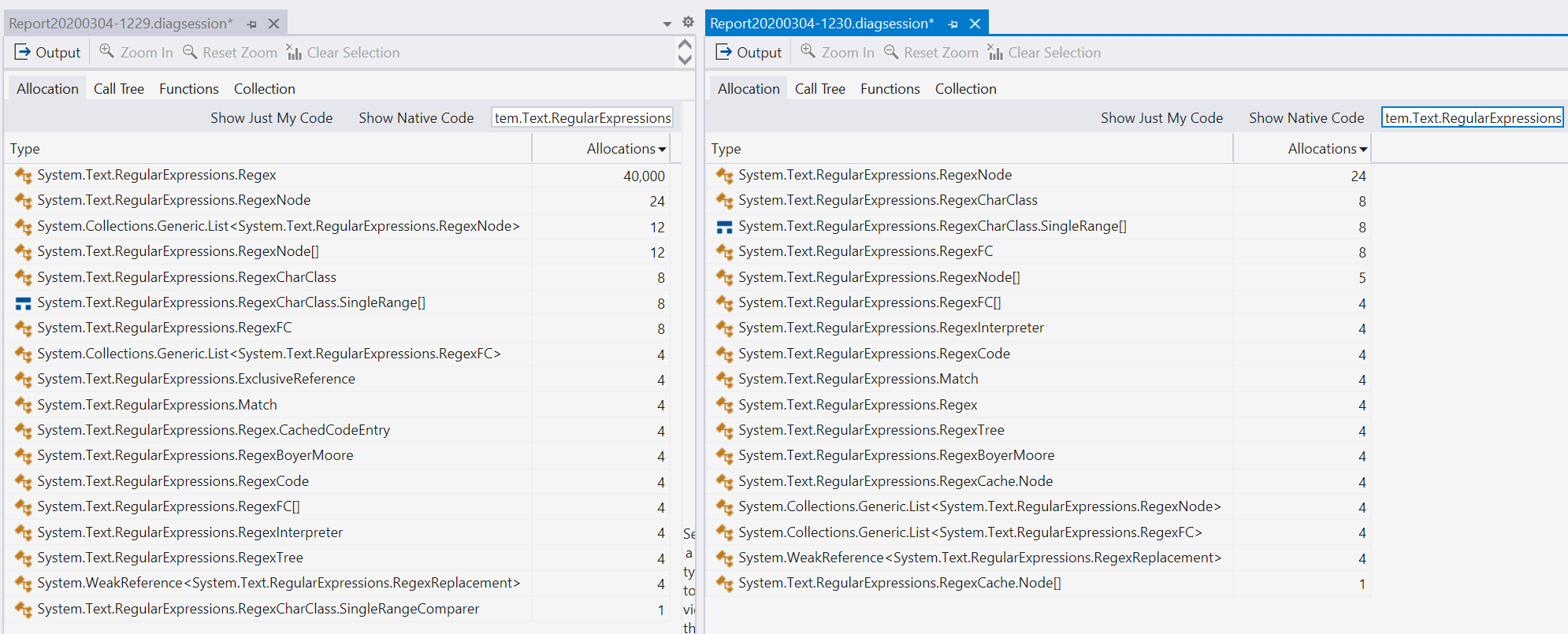
特别要注意的是,左侧包含40,000个分配的行,而右侧只有4个。
其他开销减少
我们已经介绍了.NET 5中对正则表达式进行的一些关键改进,但该列表绝不是完整的。 到处都有一些较小的优化清单,尽管我们不能在这里列举所有的优化清单,但我们可以逐步介绍更多。
在某些地方,我们已经采用了前面讨论过的矢量化形式。 例如,当使用RegexOptions.Compiled且该模式包含一个字符串字符串时,编译器将分别检查每个字符。 如果查看诸如abcd之类的表达式的反编译代码,就会看到以下内容:
if (4 <= runtextend - runtextpos &&
runtext[runtextpos] == 'a' &&
runtext[runtextpos + 1] == 'b' &&
runtext[runtextpos + 2] == 'c' &&
runtext[runtextpos + 3] == 'd')
在.NET 5中,当使用DynamicMethod创建编译后的代码时,我们现在尝试比较Int64值(在64位系统上,或在32位系统上比较Int32),而不是比较单个字符。 这意味着对于上一个示例,我们现在改为生成与此类似的代码:
if (3u < (uint)readOnlySpan.Length && *(long*)readOnlySpan._pointer == 28147922879250529L)
(我说“类似”,因为我们无法在C#中表示生成的确切IL,这与使用Unsafe类型的成员更加一致。)我们这里不必担心字节顺序问题,因为生成用于比较的Int64/Int32值的代码与加载用于比较的输入值的同一台计算机(甚至在同一进程中)发生。
另一个示例是先前在先前生成的代码示例中实际显示的内容,但已被掩盖。在比较@"a\sb"表达式的输出时,您可能之前已经注意到,以前的代码包含对CheckTimeout()的调用,但是新代码没有。此CheckTimeout()函数用于检查我们的执行时间是否超过了Regex构造时提供给其的超时值所允许的时间。但是,在没有提供超时的情况下使用的默认超时是“无限”,因此“无限”是非常常见的值。由于我们永远不会超过无限超时,因此当我们为RegexOptions.Compiled正则表达式编译代码时,我们会检查超时,如果是无限超时,则跳过生成这些CheckTimeout()调用。
在其他地方也存在类似的优化。例如,默认情况下,Regex执行区分大小写的比较。仅在指定RegexOptions.IgnoreCase的情况下(或者表达式本身包含执行不区分大小写的匹配的指令)才使用不区分大小写的比较,并且仅当使用不区分大小写的比较时,我们才需要访问CultureInfo.CurrentCulture以确定如何进行比较。此外,如果指定了RegexOptions.InvariantCulture,则我们也无需访问CultureInfo.CurrentCulture,因为它将永远不会使用。所有这些意味着,如果我们证明不再需要它,则可以避免生成访问CultureInfo.CurrentCulture的代码。最重要的是,我们可以通过发出对char.ToLowerInvariant而不是char.ToLower(CultureInfo.InvariantCulture)的调用来使RegexOptions.InvariantCulture更快,尤其是因为.NET 5中ToLowerInvariant也得到了改进(还有另一个示例,其中将Regex更改为使用其他框架功能时,只要我们改进这些已利用的功能,它就会隐式受益。
另一个有趣的更改是Regex.Replace和Regex.Split。这些方法被实现为对Regex.Match的封装,将其功能分层。但是,这意味着每次找到匹配项时,我们都将退出扫描循环,逐步遍历抽象的各个层次,在匹配项上执行工作,然后调回引擎,以正确的方式进行工作返回到扫描循环,依此类推。最重要的是,每个匹配项都需要创建一个新的Match对象。现在在.NET 5中,这些方法在内部使用了一个专用的基于回调的循环,这使我们能够停留在严格的扫描循环中,并一遍又一遍地重用同一个Match对象(如果公开公开,这是不安全的,但是可以作为内部实施细节来完成)。在实现“替换”中使用的内存管理也已调整为专注于跟踪要替换或不替换的输入区域,而不是跟踪每个单独的字符。这样做的最终结果可能对吞吐量和内存分配都产生相当大的影响,尤其是对于输入量非常长且替换次数很少的输入。
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Linq;
using System.Text.RegularExpressions;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("a",RegexOptions.Compiled);
private string _input = string.Concat(Enumerable.Repeat("abcdefghijklmnopqrstuvwxyz",1_000_000));
[Benchmark] public string Replace() => _regex.Replace(_input,"A");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| Replace | \master\corerun.exe | 93.79 ms | 1.120 ms | 0.935 ms | 0.45 | – | – | – | 81.59 MB |
| Replace | \netcore31\corerun.exe | 209.59 ms | 3.654 ms | 3.418 ms | 1.00 | 33666.6667 | 666.6667 | 666.6667 | 371.96 MB |
看看效果
所有这些结合在一起,可以在各种基准上产生明显更好的性能。 为了说明这一点,我在网上搜索了正则表达式基准并进行了几次测试。
mariomka/regex-benchmark的基准测试已经具有C#版本,因此简单地编译和运行这很容易:
using System;
using System.IO;
using System.Text.RegularExpressions;
using System.Diagnostics;
class Benchmark
{
static void Main(string[] args)
{
if (args.Length != 1)
{
Console.WriteLine("Usage: benchmark <filename>");
Environment.Exit(1);
}
StreamReader reader = new System.IO.StreamReader(args[0]);
string data = reader.ReadToEnd();
// Email
Benchmark.Measure(data,@"[\w\.+-]+@[\w\.-]+\.[\w\.-]+");
// URI
Benchmark.Measure(data,@"[\w]+://[^/\s?#]+[^\s?#]+(?:\?[^\s#]*)?(?:#[^\s]*)?");
// IP
Benchmark.Measure(data,@"(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9])\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9])");
}
static void Measure(string data,string pattern)
{
Stopwatch stopwatch = Stopwatch.StartNew();
MatchCollection matches = Regex.Matches(data,pattern,RegexOptions.Compiled);
int count = matches.Count;
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed.TotalMilliseconds.ToString("G",System.Globalization.CultureInfo.InvariantCulture) + " - " + count);
}
}
在我的机器上,这是使用.NET Core 3.1的控制台输出:
966.9274 - 92
746.3963 - 5301
65.6778 - 5
以及使用.NET 5的控制台输出:
274.3515 - 92
159.3629 - 5301
15.6075 - 5
破折号前的数字是执行时间,破折号后的数字是答案(因此,第二个数字保持不变是一件好事)。 执行时间急剧下降:分别提高了3.5倍,4.6倍和4.2倍!
我还找到了 https://zherczeg.github.io/sljit/regex_perf.html,它具有各种基准,但没有C#版本。 我将其转换为Benchmark.NET测试:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.IO;
using System.Text.RegularExpressions;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private static string s_input = File.ReadAllText(@"d:\mtent12.txt");
private Regex _regex;
[GlobalSetup]
public void Setup() => _regex = new Regex(Pattern,RegexOptions.Compiled);
[Params(
@"Twain",@"(?i)Twain",@"[a-z]shing",@"Huck[a-zA-Z]+|Saw[a-zA-Z]+",@"\b\w+nn\b",@"[a-q][^u-z]{13}x",@"Tom|Sawyer|Huckleberry|Finn",@"(?i)Tom|Sawyer|Huckleberry|Finn",@".{0,2}(Tom|Sawyer|Huckleberry|Finn)",@".{2,4}(Tom|Sawyer|Huckleberry|Finn)",@"Tom.{10,25}river|river.{10,25}Tom",@"[a-zA-Z]+ing",@"\s[a-zA-Z]{0,12}ing\s",@"([A-Za-z]awyer|[A-Za-z]inn)\s"
)]
public string Pattern { get; set; }
[Benchmark] public bool IsMatch() => _regex.IsMatch(s_input);
}
并对照该页面提供的大约20MB文本文件输入运行它,得到以下结果:
| Method | Toolchain | Pattern | Mean | Ratio |
|---|---|---|---|---|
| IsMatch | \master\corerun.exe | (?i)T(…)Finn [31] | 12,703.08 ns | 0.32 |
| IsMatch | \netcore31\corerun.exe | (?i)T(…)Finn [31] | 40,207.12 ns | 1.00 |
| IsMatch | \master\corerun.exe | (?i)Twain | 159.81 ns | 0.84 |
| IsMatch | \netcore31\corerun.exe | (?i)Twain | 189.49 ns | 1.00 |
| IsMatch | \master\corerun.exe | ([A-Z(…)nn)\s [29] | 6,903,345.70 ns | 0.10 |
| IsMatch | \netcore31\corerun.exe | ([A-Z(…)nn)\s [29] | 67,388,775.83 ns | 1.00 |
| IsMatch | \master\corerun.exe | .{0,2(…)Finn) [35] | 1,311,160.79 ns | 0.68 |
| IsMatch | \netcore31\corerun.exe | .{0,942,021.93 ns | 1.00 | |
| IsMatch | \master\corerun.exe | .{2,4(…)Finn) [35] | 1,202,730.97 ns | 0.67 |
| IsMatch | \netcore31\corerun.exe | .{2,790,485.74 ns | 1.00 | |
| IsMatch | \master\corerun.exe | Huck[(…)A-Z]+ [26] | 282,030.24 ns | 0.01 |
| IsMatch | \netcore31\corerun.exe | Huck[(…)A-Z]+ [26] | 19,908,290.62 ns | 1.00 |
| IsMatch | \master\corerun.exe | Tom.{(…)5}Tom [33] | 8,817,983.04 ns | 0.09 |
| IsMatch | \netcore31\corerun.exe | Tom.{(…)5}Tom [33] | 94,075,640.48 ns | 1.00 |
| IsMatch | \master\corerun.exe | TomS(…)Finn [27] | 39,214.62 ns | 0.14 |
| IsMatch | \netcore31\corerun.exe | TomS(…)Finn [27] | 281,452.38 ns | 1.00 |
| IsMatch | \master\corerun.exe | Twain | 64.44 ns | 0.77 |
| IsMatch | \netcore31\corerun.exe | Twain | 83.61 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-q][^u-z]{13}x | 1,695.15 ns | 0.09 |
| IsMatch | \netcore31\corerun.exe | [a-q][^u-z]{13}x | 19,412.31 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-zA-Z]+ing | 3,042.12 ns | 0.31 |
| IsMatch | \netcore31\corerun.exe | [a-zA-Z]+ing | 9,896.25 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-z]shing | 28,212.30 ns | 0.24 |
| IsMatch | \netcore31\corerun.exe | [a-z]shing | 117,954.06 ns | 1.00 |
| IsMatch | \master\corerun.exe | \b\w+nn\b | 32,278,974.55 ns | 0.21 |
| IsMatch | \netcore31\corerun.exe | \b\w+nn\b | 152,395,335.00 ns | 1.00 |
| IsMatch | \master\corerun.exe | \s[a-(…)ing\s [21] | 1,181.86 ns | 0.23 |
| IsMatch | \netcore31\corerun.exe | \s[a-(…)ing\s [21] | 5,161.79 ns | 1.00 |
这些比例中的一些非常有趣。
另一个是“The Computer Language Benchmarks Game”中的“ regex-redux”基准。 在dotnet/performance回购中利用了此实现,因此我运行了该代码:
| Method | Toolchain | options | Mean | Error | StdDev | Median | Min | Max | Ratio | RatioSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RegexRedux_5 | \master\corerun.exe | Compiled | 7.941 ms | 0.0661 ms | 0.0619 ms | 7.965 ms | 7.782 ms | 8.009 ms | 0.30 | 0.01 | – | – | – | 2.67 MB |
| RegexRedux_5 | \netcore31\corerun.exe | Compiled | 26.311 ms | 0.5058 ms | 0.4731 ms | 26.368 ms | 25.310 ms | 27.198 ms | 1.00 | 0.00 | 1571.4286 | – | – | 12.19 MB |
因此,在此基准上,.NET 5的吞吐量是.NET Core 3.1的3.3倍。
呼吁社区行动
我们希望您的反馈和贡献有多种方式。
下载.NET 5 Preview 2并使用正则表达式进行尝试。您看到可衡量的收益了吗?如果是这样,请告诉我们。如果没有,也请告诉我们,以便我们共同努力,为您最有价值的表达方式改善效果。
是否有对您很重要的特定正则表达式?如果是这样,请与我们分享;我们很乐意使用来自您的真实正则表达式,您的输入数据以及相应的预期结果来扩展我们的测试套件,以帮助确保在对我们进行进一步改进时,不会退回对您而言重要的事情代码库。实际上,我们欢迎PR到dotnet/runtime来以这种方式扩展测试套件。您可以看到,除了成千上万个综合测试用例之外,Regex测试套件还包含大量示例,这些示例来自文档,教程和实际应用程序。如果您认为应该在此处添加表达式,请提交PR。作为性能改进的一部分,我们已经更改了很多代码,尽管我们一直在努力进行验证,但是肯定会漏入一些错误。您对自己的重要表达的反馈将有助于您实现这一目标!
与 .NET 5中已经完成的工作一样,我们还列出了可以探索的其他已知工作的清单,这些工作已编入dotnet/runtime#1349。我们将在这里欢迎其他建议,更欢迎在此处概述的一些想法的实际原型设计或产品化(通过适当的性能审查,测试等)。一些示例:
-
改进自动添加原子组的循环。如本文所述,我们现在自动在多个位置插入原子组,我们可以检测到它们可能有助于减少回溯,同时保持语义相同。我们知道,但是,我们的分析存在一些空白,填补这些空白非常好。例如,该实现现在将
a*b+c更改为(?>a*)(?>b+)c,因为它将看到b+不会提供任何可以匹配c的东西,而a*不会给出可以匹配b的任何东西(b+表示必须至少有一个b)。但是,即使后者合适,表达式a*b*c也会转换为a*(?>b*)c而不是(?>a*)(?>b*)c。这里的问题是,我们目前仅查看序列中的下一个节点,并且b*可能匹配零项,这意味着a*之后的下一个节点可能是c,而我们目前的眼光并不那么远。 -
改进原子基团自动交替添加的功能。根据对交替的分析,我们可以做更多的工作来将交替自动升级为原子。例如,给定类似
(Bonjour|Hello),.*的表达式,我们知道,如果Bonjour匹配,则Hello也不可能匹配,因此可以将这种替换设置为原子的。 -
改善
IndexOfAny的向量化。如本文所述,我们现在尽可能使用内置函数,这样对这些表达式的改进也将使Regex受益(除了使用它们的所有其他工作负载)。现在,我们在某些正则表达式中对IndexOfAny的依赖度很高,以至于它可以代表处理的很大一部分,例如在前面显示的“ regex redux”基准上,约有30%的时间花费在IndexOfAny上。这里有机会改进此功能,从而也改进Regex。这由 dotnet/runtime#25023 单独引入。 -
制作DFA实现原型。 .NET正则表达式支持的某些方面很难使用基于DFA的正则表达式引擎来完成,但是某些操作应该是可以实现的,而不必担心。例如,
Regex.IsMatch不必关心捕获语义(.NET在捕获方面有一些额外的功能,这使其比其他实现更具挑战性),因此,如果该表达式不包含诸如反向引用之类的问题构造,或环顾四周,对于IsMatch,我们可以探索使用基于DFA的引擎,并且有可能随着时间的推移而得到更广泛的使用。 -
改善测试。如果您对测试的兴趣超过对实施的兴趣,那么在这里也需要做一些有价值的事情。我们的代码覆盖率已经很高,但是仍然存在差距。插入这些代码(并可能在该过程中找到无效代码)将很有帮助。查找并合并其他经过适当许可的测试套件以提供更多涵盖各种表达式的内容也很有价值。