本篇文章主要从事务的分类,操作,事务隔离级别几个方面进行阐述。
一、概述
事务是数据库系统区别文件系统的一个重要特性。
事务会把数据库从一种状态转为另一种状态。要么都修改,要么都不改。
事务可以是一个简单的sql,也可以是一个复杂的sql,事务是访问并更新数据库中各个数据项的一个程序执行单元
事务的四大特性为ACID,而innodb存储引擎完全符合ACID:
1、原子性(automicity):指整个数据库事务不可分割。要么都执行,要么都不执行。 2、一致性(consistency):指事务将数据库从一种状态转为另一种一致的状态,在事务开始前和结束后,数据库完整约束没有被破坏。 3、隔离性(isolation):(其他称呼:并发控制,可串行化,锁)指各个读写事务对象对其他事务操作相互分离,不可见。 4、持久性(durability):指事务完成后,其结果是永久的,即使机器宕机,也能够恢复。
二、提交方式
1.显式开启和提交。
使用begin或者start transaction来显式开启一个事务,显式开启的事务必须使用commit或者rollback显式提交或回滚。几种特殊的情况除外:行版本隔离级别下的更新冲突和死锁会自动回滚。
在存储过程中开启事务时必须使用start transaction,因为begin会被存储过程解析为begin...end结构块。
2.自动提交。(MySQL默认的提交方式)
set autocommit = 0 禁用自动提交
不需要显式begin或者start transaction来显式开启事务,也不需要显式提交或回滚事务,每次执行DML和DDL语句都会在执行语句前自动开启一个事务,执行语句结束后自动提交或回滚事务
3.隐式提交事务
主要包括如下操作:
1.DDL语句(其中有truncate table)。 2.隐式修改mysql数据库架构的操作:create user,drop user,grant,rename user,revoke,set password。 3.管理语句:analyze table、cache index、check table、load index into cache、optimize table、repair table。
隐式提交的事务不受任何人为控制。truncate不能回滚
三、分类
主要分为如下五类:
1、扁平事务 2、带有保存点的扁平事务 3、链事务 4、嵌套事务 5、分布式事务
3.1、扁平事务
简单,所有操作都在同一个层次上,由begin work开始,由commit work或者rollback work结束,其操作都是原子的,要么都执行,要么都回滚,扁平事务三种不同的结果,分别是commit,rollback,等待超时。扁平事务的主要限制是不能提交或者回滚一部分,或者分几步提交。
3.2、带有保存点的扁平事务
除了支持扁平事务外,还能在事务的回滚中回滚到一个较早的状态。
保存点用来记录当前事务的状态,并告知系统。save work命令设置保存点,扁平事务默认有一个保存点1,也就是事务begin的地方,所以当我们设置保存点的时候是从2开始的。保存点在事务内是递增的。可以通过rollback work:2,回到保存点2。事务还处于活动状态,只有执行了rollback work,事务才结束
3.3、链事务
在提交一个事务时,释放不需要的数据对象,将必要处理的上下文隐式的传给下一个要开始的事务, 注意:提交事务操作和下一个事务开始操作合并为一个原子操作,这意味着下一个事务将看到上一个事务的结果。链事务不能随意回滚,只能回滚当前事务,即恢复到最近的一个保存点。链事务在执行commit操作立即释放持有锁,而带有保存点的扁平事务不影响迄今为止持有的锁。链事务的工作方式如下图所示:

3.4、嵌套事务
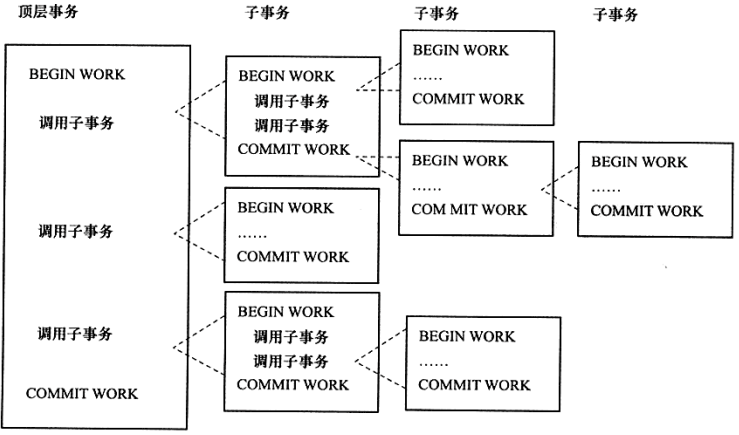
是一个层次结构框架,由一个顶层事务,控制着各个层次的事务。
嵌套事务是由若干事务组成的一棵树,子树既可以是嵌套事务,也可以是扁平事务
位于根节点的事务为顶层事务,其他为子事务,
子事务可以提交,也可以回滚,提交不会立马生效,要等其父事务提交。也就是要等顶层事务commit,才能保证每个子事务提交生效。
树中任意一个事务的回滚会引起它的所有子事务一同回滚,故子事务只保留了ACI特性,没有D
嵌套事务层次结构图如下图所示:
3.5、分布式事务
通常是一个分布式环境下的扁平事务。将多个服务器上的事务(节点)组合形成一个遵循事务特性(acid)的分布式事务。
innodb提供对XA事务的支持,并通过XA事务来支持分布式事务的实现,分布式事务允许多个独立的事务资源参与到一个全局的事务中。全局事务要求其中的事务要么全部提交,要么全部回滚。在使用分布式事务时,innodb存储引擎必须把事务隔离级别设置为SERIALIZABLE.
XA事务由一个多者多个资源管理器、一个事务管理器以及一个应用程序组成。
资源管理器:提供事务访问资源的方法,通常一个数据库就是一个资源管理器
事务管理器:协调参与全局事务中的各个事务,需要和参与全局事务的所有资源管理器进行通信
应用程序:定义事务的边界,指全局事务中的操作。
分布式事务采用两段式提交。在第一阶段参与全局事务的节点都开始准备,告诉事务管理器它们准备好了,在第二阶段,事务管理器通知资源管理器执行commit操作或者是rollback操作。
如上所说的分布式事务是外部事务,在mysql内部还有另外一种分布式事务,存在引擎和插件之间,又或存在引擎和引擎之间,称之为内部XA事务。
最常见的内部XA事务存在binlog和Innodb引擎之间,在主从复制中,在事务提交时,先写binlog日志,然后在写redo log日志。对上述的两个操作要求原子性,即binlog和redo log必须同时写入,如果binlog先写入了,而在写redo log的时候宕机了,那么slave会接收到master的binlog执行,导致主从不一致,如图下图所示:

如果执行完1,2后,在步骤3之前mysql发生了宕机,同样会导致主从不一致,为了解决这个问题,mysql在binlog和innodb引擎之间增加了内部XA事务。
当事务提交时,innodb引擎会做一个repeate操作,将事务的xid写入,接着写binlog,如果在写完binlog后宕机了,重启数据库会先检查准备的UXID事务是否提交,若没有,则存储引擎会继续提交一次。如下图所示:

四、事务控制语句
事务控制语句如下:
mysql默认自动提交事务,set autocommit = 0 禁用自动提交 显示开启事务:begin | start transaction 提交事务:commit | commit work 回滚事务:rollback | rollback work 设置保存点:savepoint identifier 删除保存点:release savepoint identifier 回滚到某个保存点:rollback to [savepoint] identifier 设置事务隔离级别:set transaction :READ UNCOMMITTED,READ COMMITTED,REPEATABLE READ,SERIALIZABLE
commit 和 commit work的区别(由参数completion_type控制):
completion_type=0:二者完全等价(也是默认方式)
completion_type=1:commit work等同于commit and chain,表示提交当前事务,并马上开启一个相同隔离级别的事务
completion_type=2:commit work等同于commit and release,表示提交事务后,断开与服务器的连接。
rollback和rollback work与commit和commit work的工作一样,不再赘述
五、事务隔离级别
事务隔离级别如下:
1.READ UNCOMMITTED 2.READ COMMITTED 3.REPEATABLE READ 4.SERIALIZABLE
5.1、查看和设置隔离级别
MySQL中默认的隔离级别是repeatable read,innodb存储引擎通过next-key lock解决幻读问题
设置隔离级别:
隔离级别是基于会话设置的,当然也可以基于全局进行设置,设置为全局时,不会影响当前会话的级别。设置的方法是:
set [global | session] transaction isolation level {type}
type:
read uncommitted | read committed | repeatable read | serializable
或者直接修改变量值:
set @@global.tx_isolation = 'read-uncommitted' | 'read-committed' | 'repeatable-read' | 'serializable'
set @@session.tx_isolation = 'read-uncommitted' | 'read-committed' | 'repeatable-read' | 'serializable'
查看当前会话的隔离级别:
mysql> select @@tx_isolation;
mysql> select @@global.tx_isolation;
5.2、read uncommitted
该级别称为未提交读,即允许读取未提交的数据(脏读)。
在该隔离级别下,读数据的时候不会申请读锁,所以也不会出现查询被阻塞的情况
该隔离级别问题太多,会导致脏读、丢失的更新、幻影读、读不一致的问题。但由于不申请读锁,从理论上来说,它的并发性是最佳的。所以在某些特殊情况下还是会考虑使用该级别。
5.3、read committed
允许不可重复读和允许幻读,不可重复读指在一个事务中多次读取同一份数据,在这个事务没有结束过程中,其他事务对这份数据进行了修改,这样就导致这个事务读取到的数据和之前一次的数据是不一样的,这就是不可重复读。
幻读和不可重复读的区别:
不可重复读:A事务在执行过程中,B事务对数据进行了修改或删除,导致A两次读取的数据不一致;重点在于delete和update操作,锁行可以解决问题
幻读:A事务在执行过程中,B事务新增了符合A事务要查询的数据,导致A两次读取的数据不一致;重点在于insert操作,锁表或者锁范围可以解决
5.4、repeatable read
MySQL中repeatable read级别总是会在事务开启的时候读取最新提交的行版本,并将该行版本一直持有到事务结束
innodb存储引擎使用next-key lock算法,它会进行范围锁定。这就避免了幻影读的问题
5.5、serializable
MySQL中的serializable其实类似于repeatable read,只不过所有的select语句会自动在后面加上lock in share mode。也就是说会对所有的读进行加锁,而不是读取行版本的快照数据,也就不再支持"一致性非锁定读"。这样就实现了串行化的事务隔离:每一个事务必须等待前一个事务(哪怕是只有查询的事务)结束后才能进行哪怕只是查询的操作
其他mysql文章请看:MYSQL学习系列
参考:
《msyql技术内幕:innodb存储引擎》
 在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...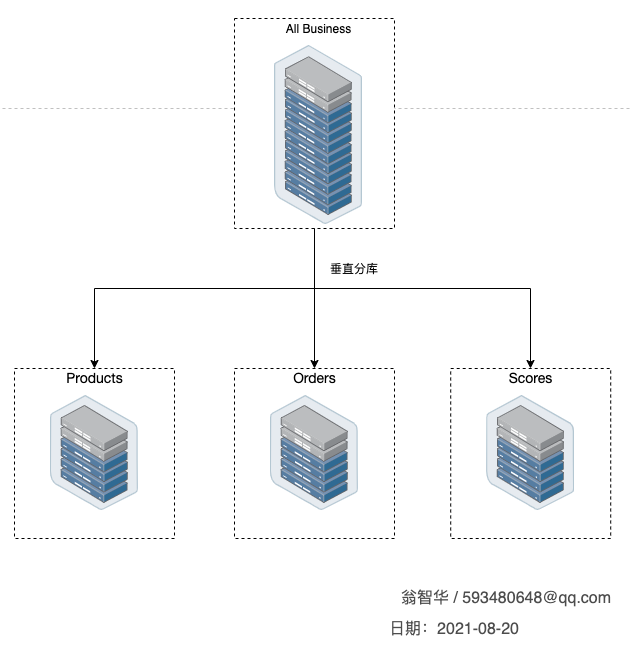 物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时...
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时... navicat查看某个表的所有字段的详细信息 navicat设计表只能一...
navicat查看某个表的所有字段的详细信息 navicat设计表只能一... 文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...