我一直在尝试在MySQL中的两个表上执行联接,并且查询将运行一两分钟,然后再耗尽内存而没有结果.我距离数据库专家还很远,所以我不确定我的查询编写是否不好,是否配置了一些MySQL设置错误,或者我是否真的应该对查询做其他事情.仅供参考,数据库位于我的计算机本地.
我有一个大表(约200万条记录),其中一列是进入小表(约3000条记录)的ID.在这种情况下,ID在大表中不是唯一的,而在小表中是唯一的.我尝试了以下查询的各种形式,但似乎没有任何效果:
SELECT big_table.*,small_table.col
FROM big_table
left outer join small_table on (big_table.small_id = small_table.id)
我正在对确实需要全部200万行的数据进行大量分析,尽管不一定要在单个查询中进行.这是我的“显示创建表”的结果:
'big_table','CREATE TABLE 'big_table' (
'BIG_ID_1',varchar(12) NOT NULL,'BIG_ID_2',int(100) NOT NULL,'SMALL_ID' varchar(8) DEFAULT NULL,'TYPICAL_OTHER_COLUMN' varchar(3) DEFAULT NULL,...
PRIMARY KEY ('BIG_ID_1','BIG_ID_2')
) ENGINE=MyISAM DEFAULT CHARSET=latin1'
'small_table','CREATE TABLE `small_table` (
`id`,varchar(8) NOT NULL DEFAULT '''',`col`,varchar(1) DEFAULT NULL,...
PRIMARY KEY (`id`),KEY `inx_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1'
这是我的一个候选查询的“解释”结果:
id select_type table type possible_keys key key_len ref rows extra 1 SIMPLE big_table ALL NULL NULL NULL NULL 1962193 1 SIMPLE small_table eq_ref PRIMARY,inx_id PRIMARY 10 db_name.big_table.SMALL_ID 1
最佳答案
您在单个查询中选择大约200万条记录.根据每一行中的数据量,它可能是您要请求的数百兆字节的数据.
您可能想尝试的事情:
>如果不需要所有列,请查询所需的列,而不要使用SELECT table.*.
>查看是否可以将部分(或全部)处理移至数据库,而不是获取数据并在客户端中进行处理.
>避免一次将整个结果集读入存储器.
>一次处理数千行,而不是一次获取所有行.
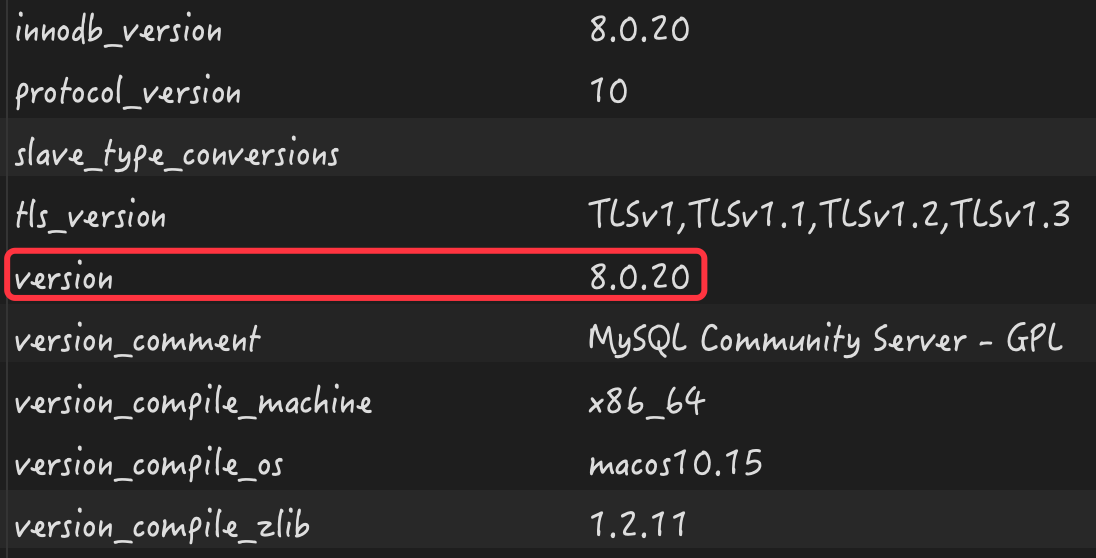 在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...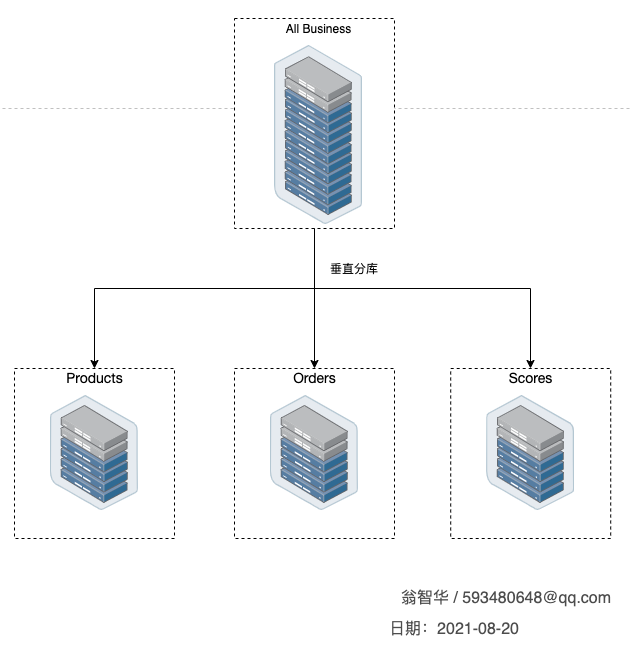 物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时...
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时... navicat查看某个表的所有字段的详细信息 navicat设计表只能一...
navicat查看某个表的所有字段的详细信息 navicat设计表只能一... 文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...