我有一张有300,000条记录的大桌子.该表具有一个称为“速度”的整数值,并且它的值是从0到100.
在firsts记录中,该值为0,我要删除.我想从查询中删除速度场重复超过10次的记录.例如:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 5 10 12 13 15 20 30 20 15 10 8 5 2 1 0 0 0 0 4 5 10 20 …
[——-删除此———–] ………………………………. ……………………………………. [—— —]<-请勿删除 谢谢
最佳答案
最简单的方法是使用循环.
您可以编写一个遍历记录的存储过程,也可以在数据库外部进行存储过程.如果需要执行一次,我会那样做.如果这是一个连续的过程,最好先确保没有将多余的数据插入数据库中.
您可以编写一个遍历记录的存储过程,也可以在数据库外部进行存储过程.如果需要执行一次,我会那样做.如果这是一个连续的过程,最好先确保没有将多余的数据插入数据库中.
无论如何,如果您坚持在纯SQL中执行此操作,而没有带循环的存储过程,则可以使用如下查询:
set @groupnum=0;
select
GroupNum,count(*) as RecsInGroup
from
(
select
t1.id as Id,t1.velocity as velocity1,t2.velocity as velocity2,if(t1.velocity<>t2.velocity,@groupnum:=@groupnum+1,@groupnum) as GroupNum
from
VelocityTable as t1
join
VelocityTable as t2
on
t1.id=t2.id-1
) as groups
group by
GroupNum
having RecsInGroup>10
这里会发生什么?
第1步
内部查询只是选择表中的所有记录,而是将数据分成连续的组.
因此,以您的示例为例:
velocity : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 5 10 12 13 15 20 30 20 15 10 8 5 2 1 0 0 0 0 4 5 10 20
Groupnum : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 18 18 18 19 20 21 22
它通过将表自身连接起来,链接表中的后续记录来实现.每当左右速度不同时,GroupNum都会增加.否则,它保持不变.
第2步
如果查询被包装在外部查询中并按GroupNum分组,则结果为.同样,使用您的示例将导致以下结果:
GroupNum,RecsInGroup
0,15 // !!
1,1
2,1
3,1
4,1
5,1
6,1
7,1
8,1
9,1
10,1
11,1
12,1
13,1
14,1
15,1
16,1
17,1
18,4 // !!
19,1
20,1
21,1
通过添加具有RecsInGroup> 10子句,结果变为:
GroupNum,15
现在,使用此GroupNum列表,您可以删除记录.
第三步
通过上面的查询,您可以:
>所有记录的列表,并添加了GroupNum列.
>需要删除的GroupNum的列表.
此时,删除记录应该很容易.
 在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...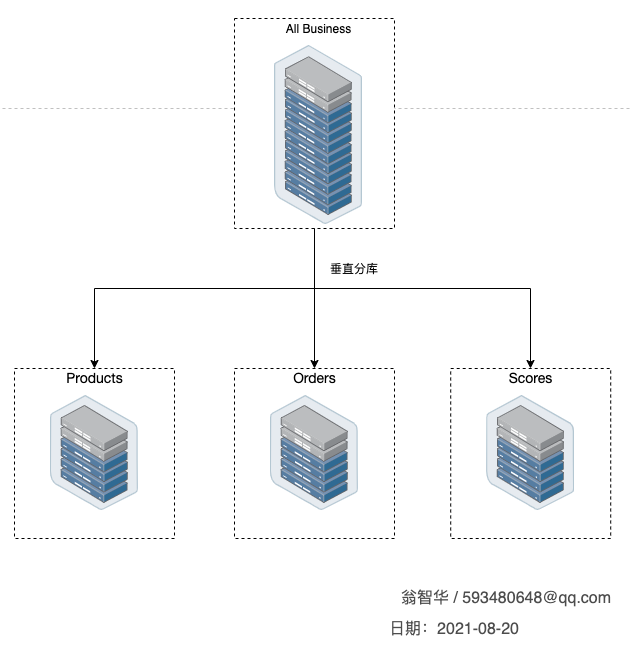 物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时...
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时... navicat查看某个表的所有字段的详细信息 navicat设计表只能一...
navicat查看某个表的所有字段的详细信息 navicat设计表只能一... 文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...