我有一个填充了规范化地址的客户数据库.有重复.
每个用户都创建了自己的记录,并输入了自己的地址.因此,我们在用户和地址之间建立了一对一的关系:
CREATE TABLE `users` (
`UserID` INT UNSIGNED NOT NULL AUTO_INCREMENT,`Name` VARCHAR(63),`Email` VARCHAR(63),`AddressID` INT UNSIGNED,PRIMARY KEY (`UserID`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `addresses` (
`AddressID` INT UNSIGNED NOT NULL AUTO_INCREMENT,`Duplicate` VARCHAR(1),`Address1` VARCHAR(63) DEFAULT NULL,`Address2` VARCHAR(63) DEFAULT NULL,`City` VARCHAR(63) DEFAULT NULL,`State` VARCHAR(2) DEFAULT NULL,`ZIP` VARCHAR(10) DEFAULT NULL,PRIMARY KEY (`AddressID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
而数据:
INSERT INTO `users` VALUES
(1,'Michael','michael@email.com',1),(2,'Steve','steve@email.com',2),(3,'Judy','judy@email.com',3),(4,'Kathy','kathy@email.com',4),(5,'Mark','mark@email.com',5),(6,'Robert','robert@email.com',6),(7,'Susan','susan@email.com',7),(8,'Paul','paul@email.com',8),(9,'Patrick','patrick@email.com',9),(10,'Mary','mary@email.com',10),(11,'James','james@email.com',11),(12,'Barbara','barbara@email.com',12),(13,'Peter','peter@email.com',13);
INSERT INTO `addresses` VALUES
(1,'','1234 Main Street','Springfield','KS','54321'),'Y','5678 Sycamore Lane','Upstate','NY','50000'),'1000 State Street','Apt C','Sunnydale','OH','Apt A','1000 Main Street','9999 Valleyview','54321');
哦,是的,让我加上那个外键关系:
ALTER TABLE `users` ADD CONSTRAINT `AddressID`
FOREIGN KEY `AddressID` (`AddressID`)
REFERENCES `addresses` (`AddressID`);
我们通过第三方服务清理了我们的地址列表,该服务对数据进行了规范化并指出了我们重复的位置.这是Duplicate列的来源.如果有’Y’,则它是另一个地址的副本.主要地址未标记为重复,如示例数据中所示.
我显然想要删除所有重复记录,但有用户记录指向它们.我需要它们指向不重复的地址版本.
那么如何更新用户的AddressID以匹配非重复地址?
我能想到的唯一方法就是使用高级语言迭代所有数据,但我很确定MySQL拥有以更好的方式做这样的事情所需的所有工具.
这是我尝试过的:
SELECT COUNT(*) as cnt,GROUP_CONCAT(AddressID ORDER BY AddressID) AS ids
FROM addresses
GROUP BY Address1,Address2,City,State,ZIP
HAVING cnt > 1;
+-----+--------------+
| cnt | ids |
+-----+--------------+
| 2 | 5,7 |
| 6 | 1,2,3,6,8,10 |
| 2 | 4,11 |
+-----+--------------+
3 rows in set (0.00 sec)
从那里,我可以遍历每个结果行并执行此操作:
UPDATE `users` SET `AddressID` = 1 WHERE `AddressID` IN (2,10);
但是必须有一个更好的MySQL方式,不应该吗?
一切都说完了,数据应该是这样的:
SELECT * FROM `users`;
+--------+---------+-------------------+-----------+
| UserID | Name | Email | AddressID |
+--------+---------+-------------------+-----------+
| 1 | Michael | michael@email.com | 1 |
| 2 | Steve | steve@email.com | 1 |
| 3 | Judy | judy@email.com | 1 |
| 4 | Kathy | kathy@email.com | 4 |
| 5 | Mark | mark@email.com | 5 |
| 6 | Robert | robert@email.com | 1 |
| 7 | Susan | susan@email.com | 5 |
| 8 | Paul | paul@email.com | 1 |
| 9 | Patrick | patrick@email.com | 9 |
| 10 | Mary | mary@email.com | 1 |
| 11 | James | james@email.com | 4 |
| 12 | Barbara | barbara@email.com | 1 |
| 13 | Peter | peter@email.com | 13 |
+--------+---------+-------------------+-----------+
13 rows in set (0.00 sec)
SELECT * FROM `addresses`;
+-----------+-----------+--------------------+----------+-------------+-------+-------+
| AddressID | Duplicate | Address1 | Address2 | City | State | ZIP |
+-----------+-----------+--------------------+----------+-------------+-------+-------+
| 1 | | 1234 Main Street | | Springfield | KS | 54321 |
| 4 | | 5678 Sycamore Lane | | Upstate | NY | 50000 |
| 5 | | 1000 State Street | Apt C | Sunnydale | OH | 54321 |
| 9 | | 1000 State Street | Apt A | Sunnydale | OH | 54321 |
| 13 | | 9999 Valleyview | | Springfield | KS | 54321 |
+-----------+-----------+--------------------+----------+-------------+-------+-------+
5 rows in set (0.00 sec)
救命?
最佳答案
要选择要查看的结果:
SELECT a.UserID,a.Name,a.Email,(
SELECT addressID
FROM addresses c
WHERE c.Address1 = b.Address1
AND c.Address2 = b.Address2
AND c.City = b.City
AND c.State = b.State
AND c.ZIP = b.ZIP
AND DUPLICATE != 'Y'
) as AddressID
FROM users a
JOIN addresses b
ON a.AddressID = b.AddressID
这会将users表更新为上面查询中显示的结果.
UPDATE users a
JOIN addresses b
ON a.AddressID = b.AddressID
SET a.addressID =
(
SELECT addressID
FROM addresses c
WHERE c.Address1 = b.Address1
AND c.Address2 = b.Address2
AND c.City = b.City
AND c.State = b.State
AND c.ZIP = b.ZIP
AND Duplicate != 'Y'
)
WHERE Duplicate = 'Y'
请注意,对于您提供的示例数据,#12 Barbara的ID在SELECT查询中为空,因为她的地址被标记为重复,而实际上它对于提供的列表是唯一的.它与地址1不匹配,如“它应该如何看”结果中所示.
编辑
为了处理不正确的重复标记,例如#12 Barbara,或者可能是其他未标记的重复标记,您可以跳过重复标记列检查并使用ORDER BY&对子查询进行LIMIT,以便它将返回第一个最低匹配地址ID,而不管重复标记如何:
UPDATE users a
JOIN addresses b
ON a.AddressID = b.AddressID
SET a.addressID =
(
SELECT addressID
FROM addresses c
WHERE c.Address1 = b.Address1
AND c.Address2 = b.Address2
AND c.City = b.City
AND c.State = b.State
AND c.ZIP = b.ZIP
ORDER BY c.addressID ASC
LIMIT 1
)
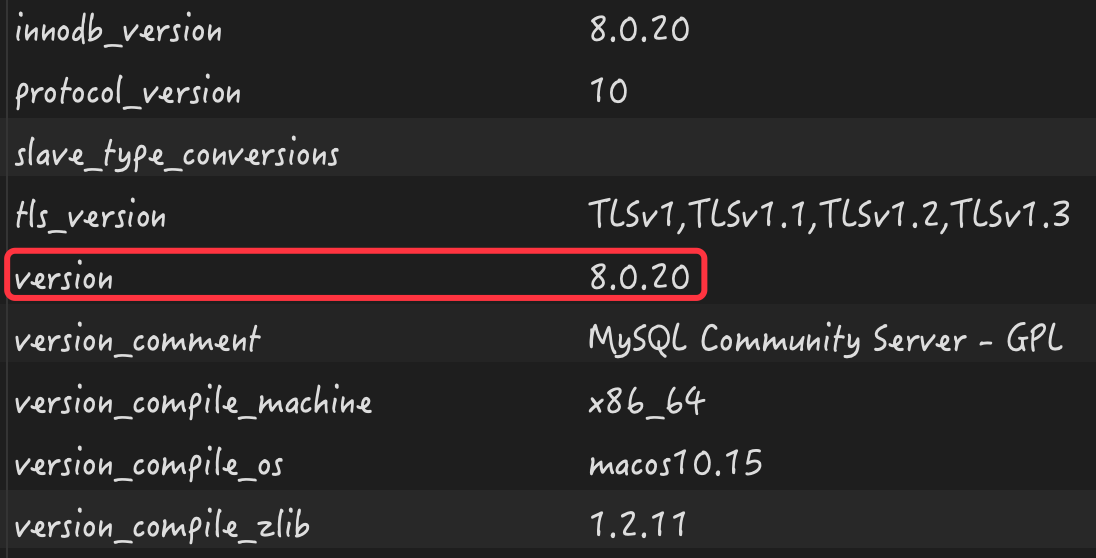 在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...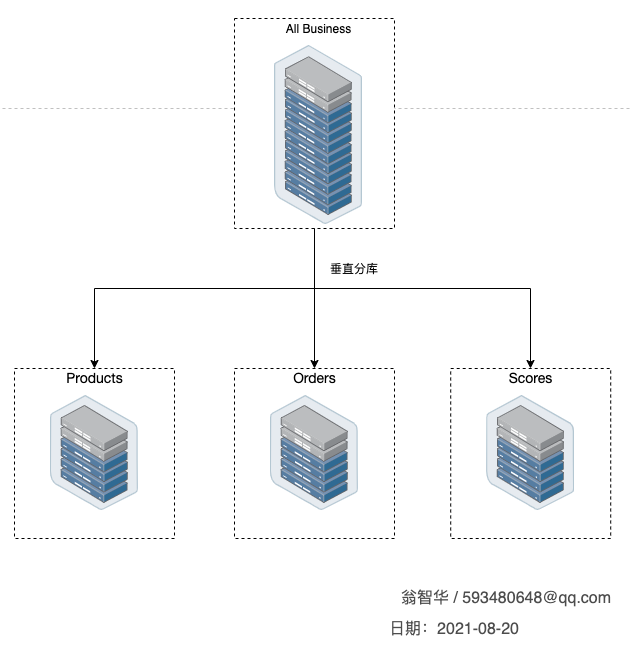 物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时...
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时... navicat查看某个表的所有字段的详细信息 navicat设计表只能一...
navicat查看某个表的所有字段的详细信息 navicat设计表只能一... 文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...