之前写过MysqL导入千万数据的几种方法,参考文章MysqL千万级数据量插入的几种方案耗时,看完就知道如何选择
现在再讲讲第三方ETL工具kettle,毕竟这工具在企业中也是比较常用的数据处理工具。
优化配置后,效率也挺高

环境准备
在虚拟机中安装好MysqL8.0.19,存储引擎选择innoDB,并新增一个数据库,并创建t_user表,为简单起见,就2个字段,id和name;为减少网络可能存在问题。不需要建立索引,毕竟导入大数据,有索引的话,还需而外维护,那性能更慢。create table t_user(id int, name varchar(20));
可到官网下载KETTLE,国内网站只更新到8.0,我下了最新版本《pdi-ce-9.0.0.0-423.zip》,使用方法一样,解压就能用,当然它是java编写的,所以需要jdk支持,测试过,只支持jdk1.8,jdk11以上不支持。所以我改了我本机的jdk环境。
具体操作
kettle可以放在某个本机目录下,然后解压如图所示
kettle启动,windows下执行spoon.bat,mac下执行spoon.sh,spoon是kettle的图形化界面。
我这是mac机器,所以执行以下命令
./spoon.sh
正常的话就能看到@R_502_6360@面

新建一个转换。在输入选项里面选择文本输入,文本输入可以理解为数据源,把这个数据源导入到MysqL当中,文本文件数据类似下图,有1000万条数据,我是用程序自动生成。简单起见,只有id和name字段。
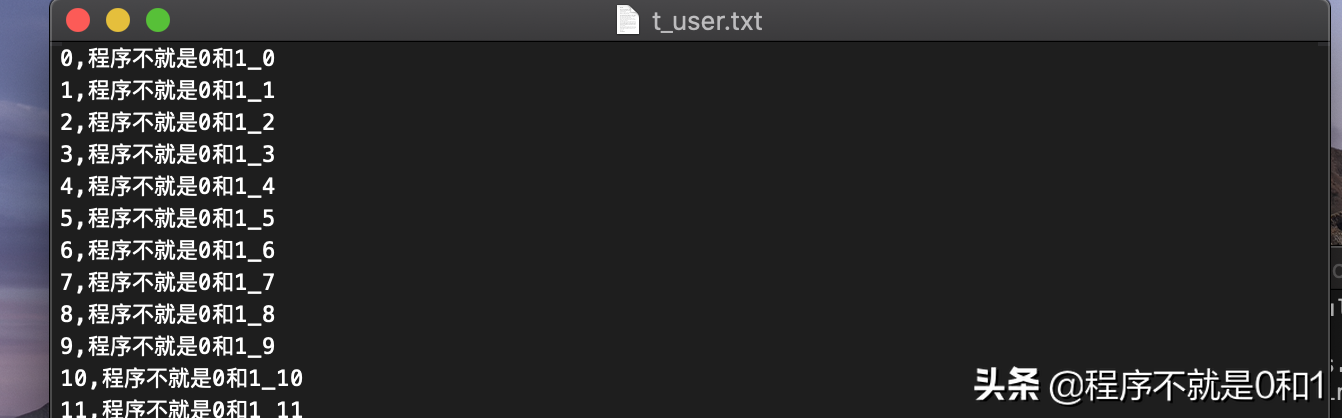
拖拽文本输入控件,并做一些简单配置,因为我这txt文件用了逗号分隔,所以只要再内容选项中设置分隔符,其余保持默认就好了
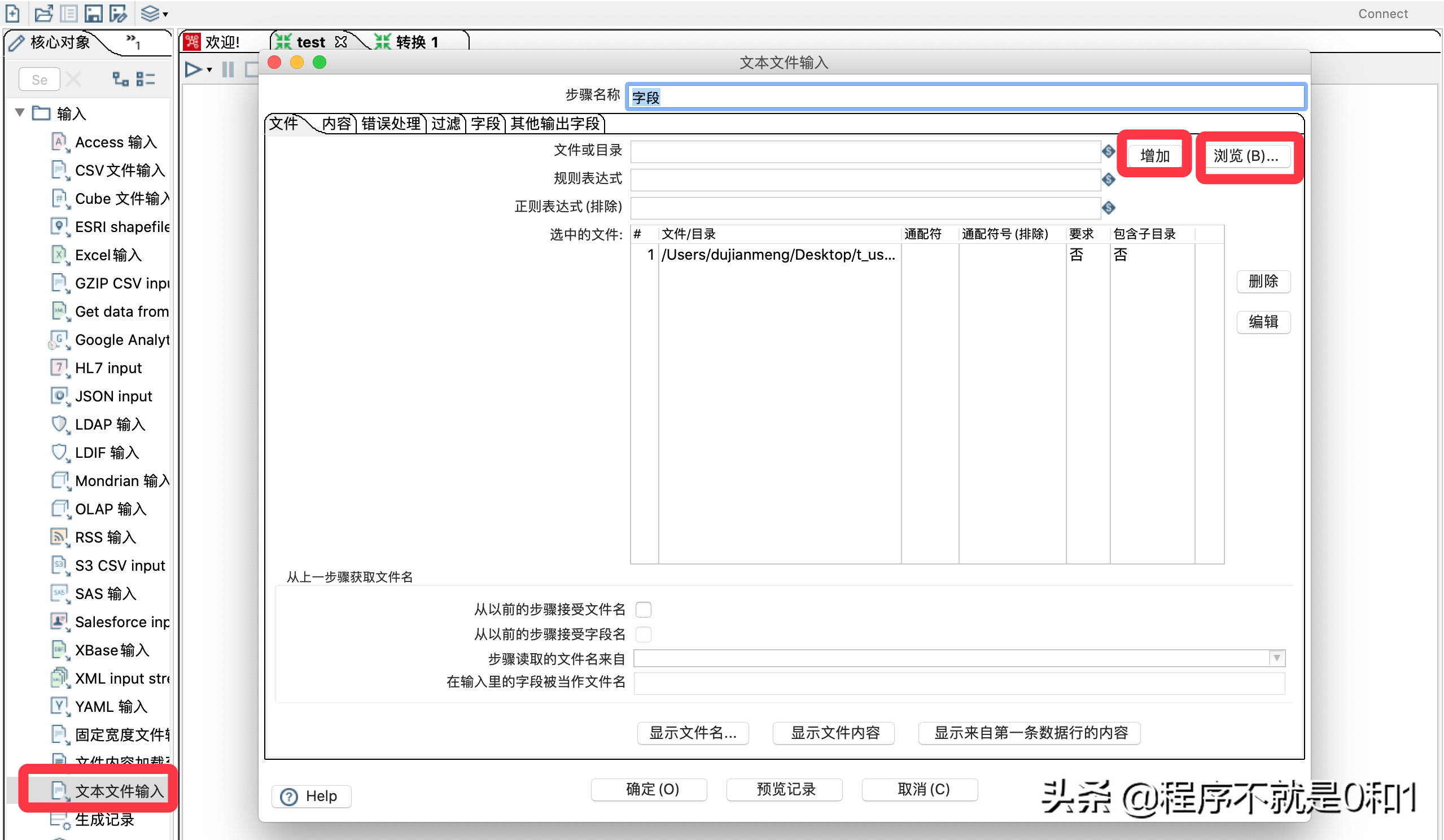
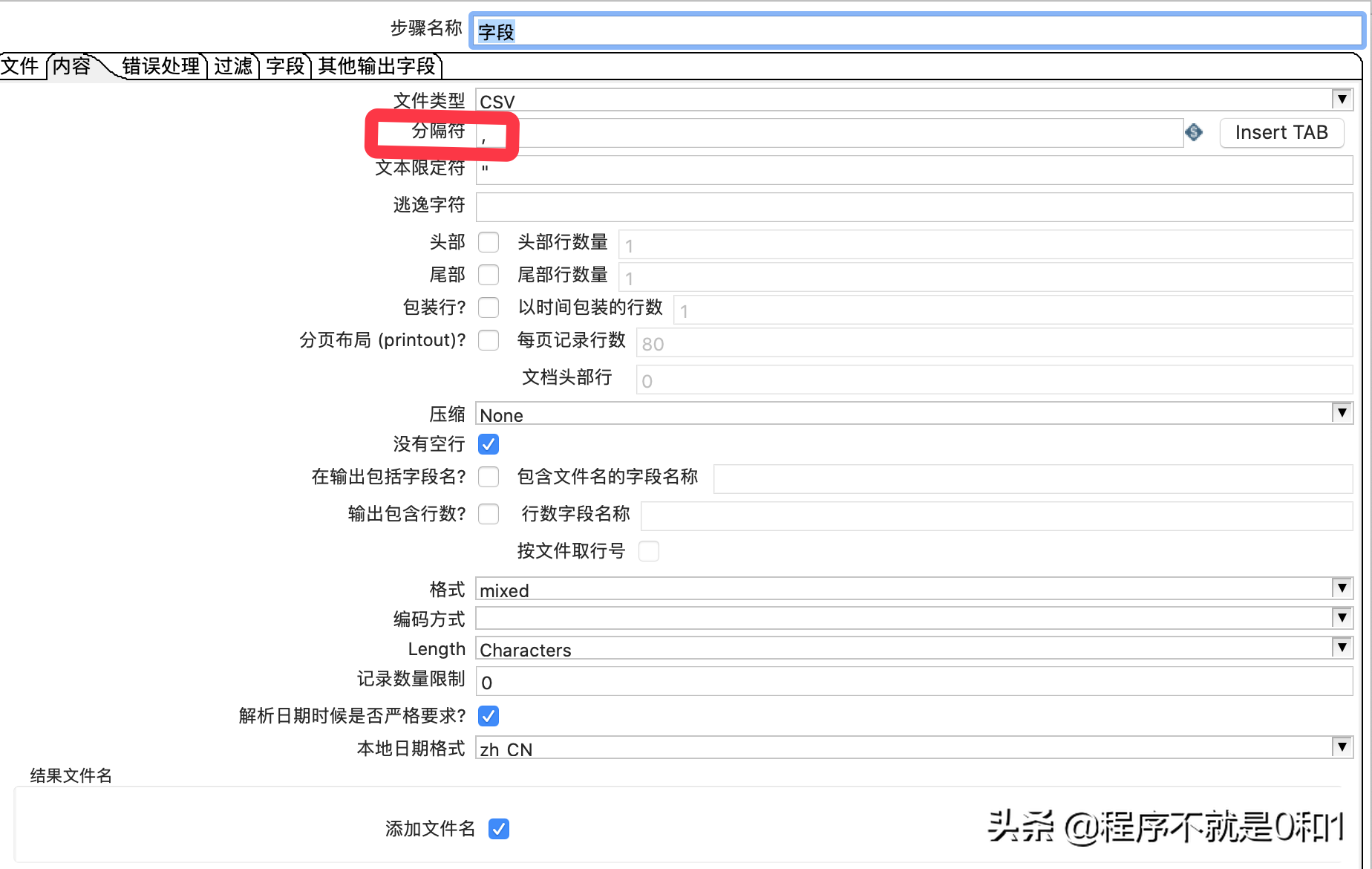
在字段选项生成字段
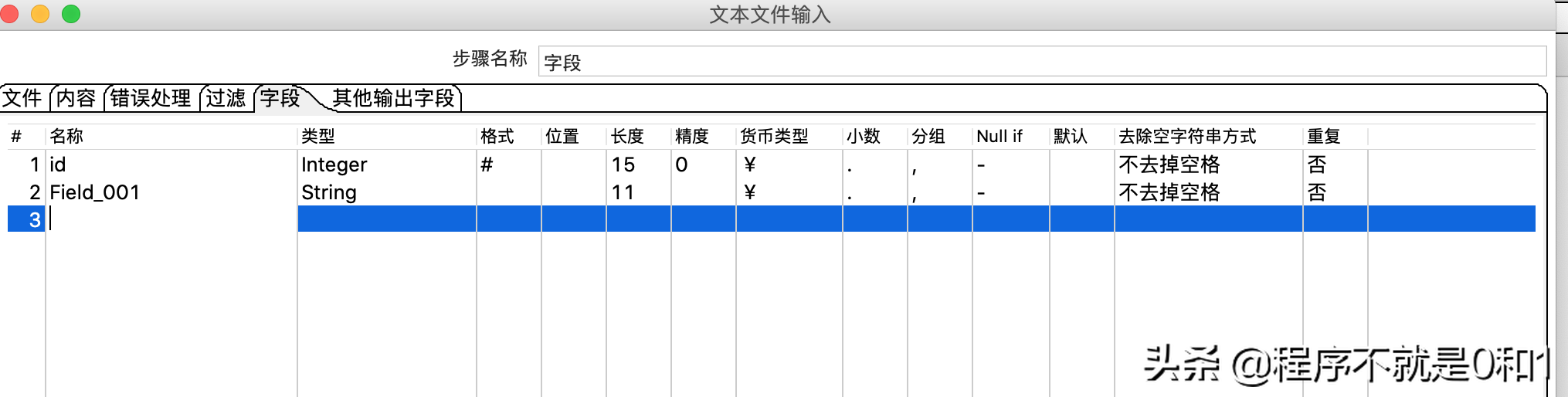
新增一个表输出,此项就是需要把数据导入的目标。因为我们需要导入到MysqL当中,所以需要把MysqL驱动导入到kettle的安装目录的lib包下,需要重启kettle。

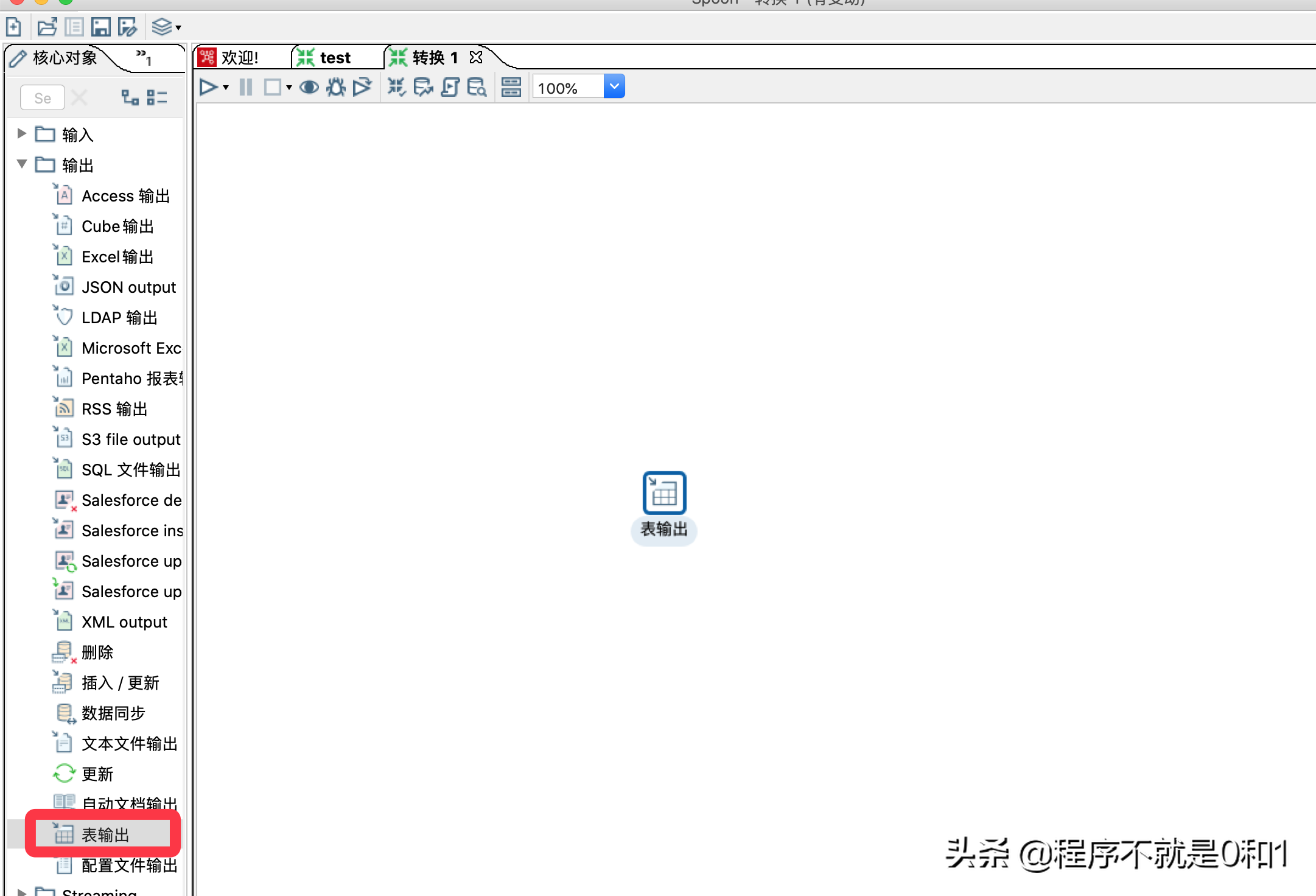
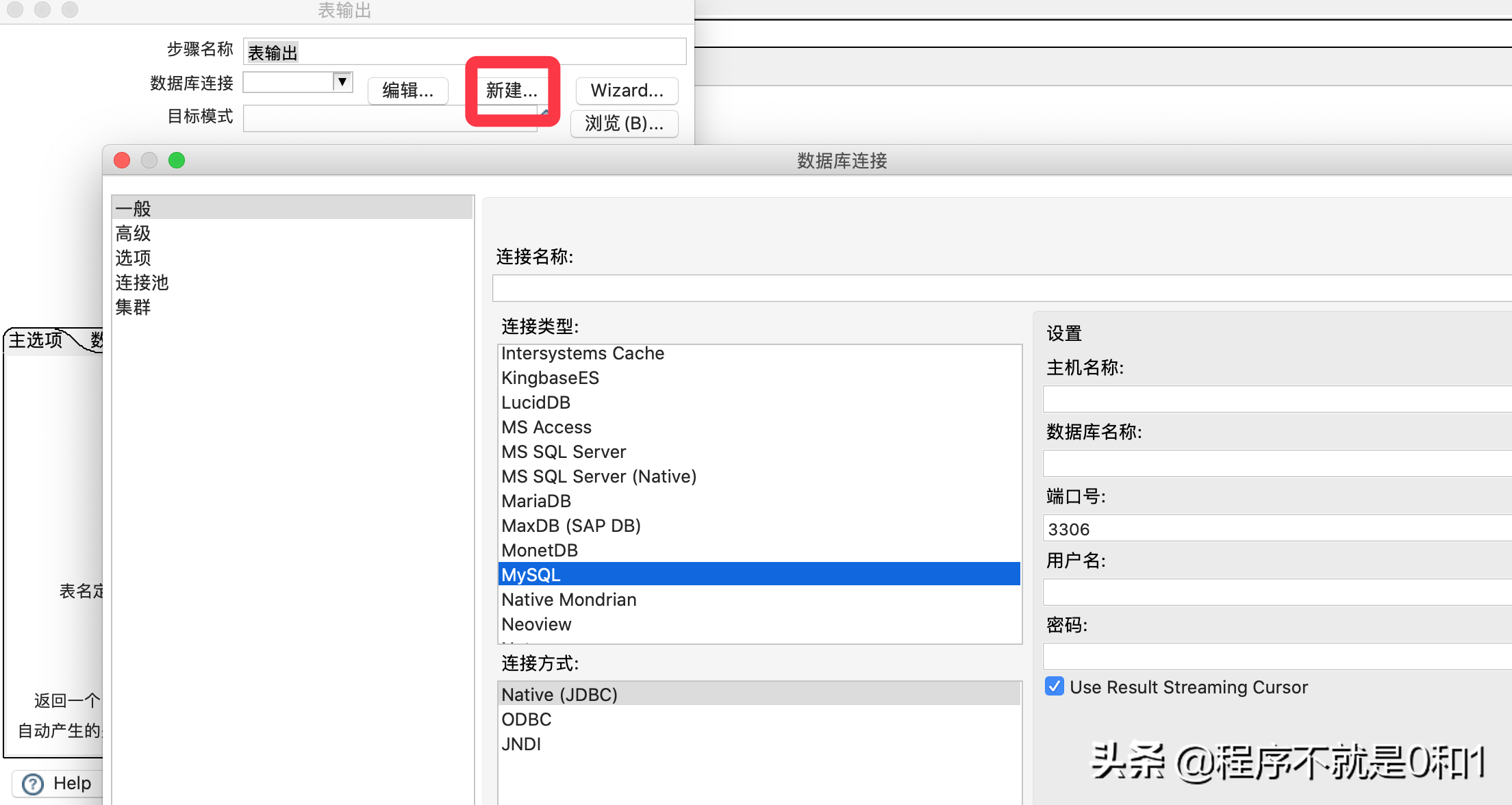
最后,在文本输入和表输出之间建立一个关联关系,有个专门的术语-跳,表示数据的流向关系,从文本获取数据源,传到数据库表中。大概的配置就完成了,之后再执行前,做一些优化工作,提高性能。
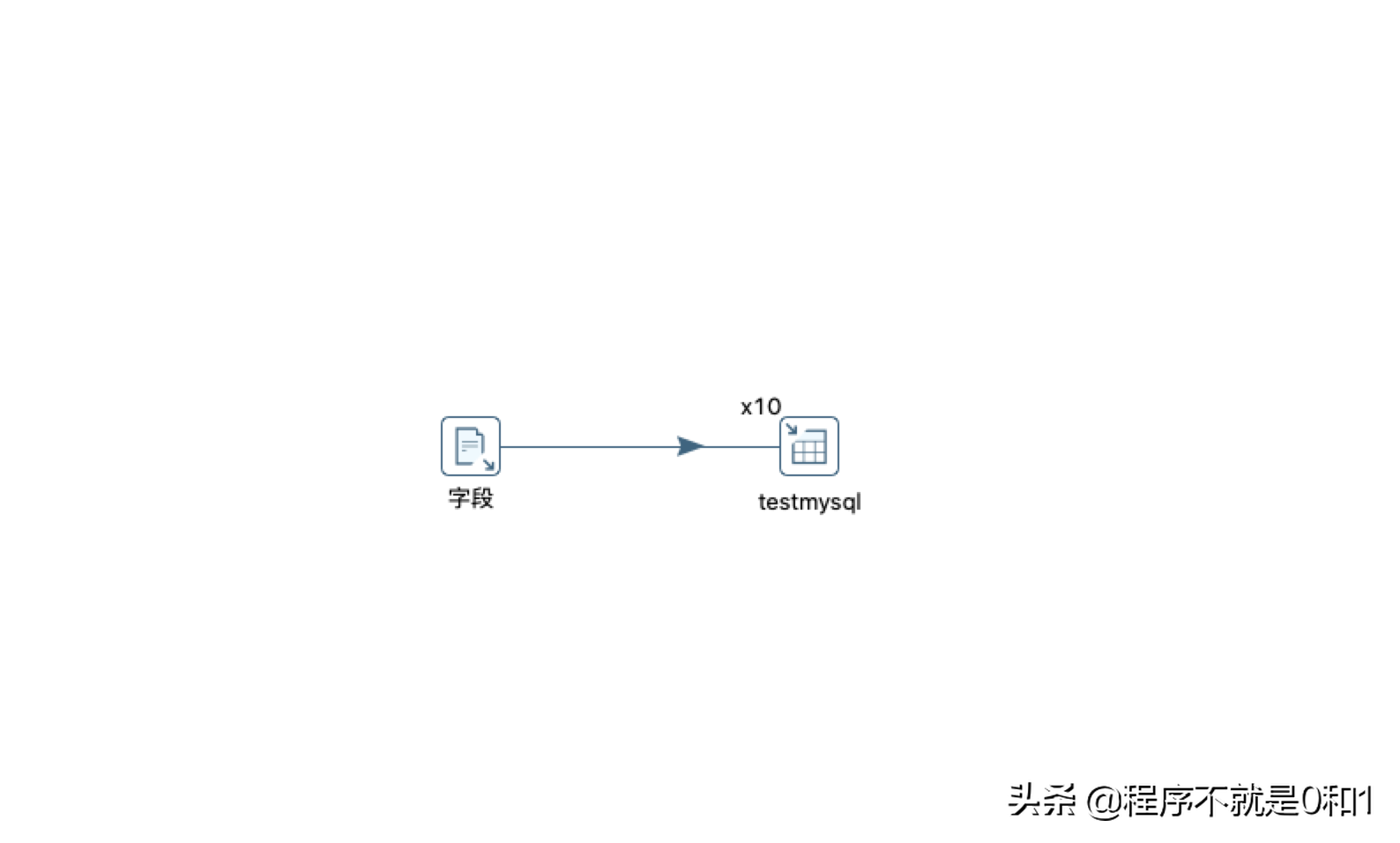
优化建议
在db连接选项中配置参数,目的是使用批量插入的方式,并且利用压缩数据方式,提高传递到服务器的效率useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true

因为是大批量数据迁移,主要影响抽取速度的是表输出,因此目标数据数据库我开了10个线程进行写入。这里注意,我文本输入1000万数据都在一个文本中,不需要开线程,否则会重复读取数据,当然可以建立多个输入,这样可以重复利用cpu。
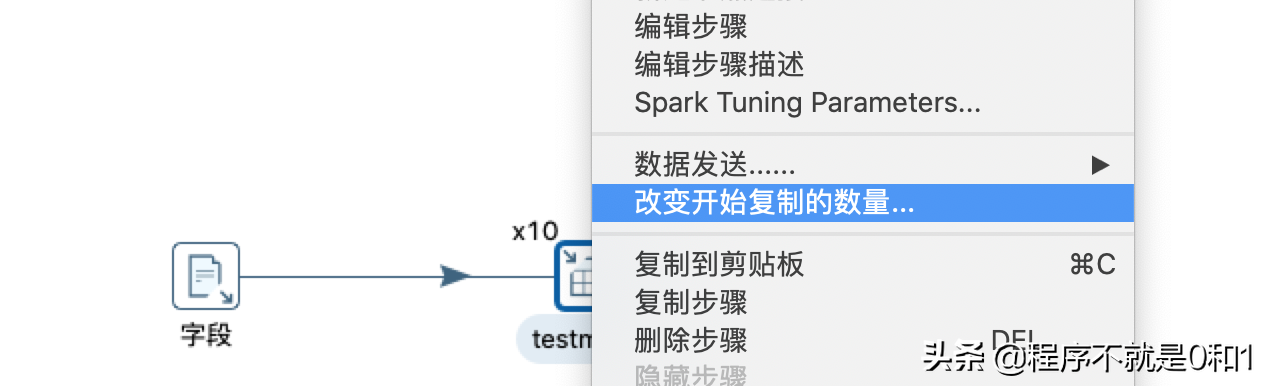
这样就可以执行数据导入了。
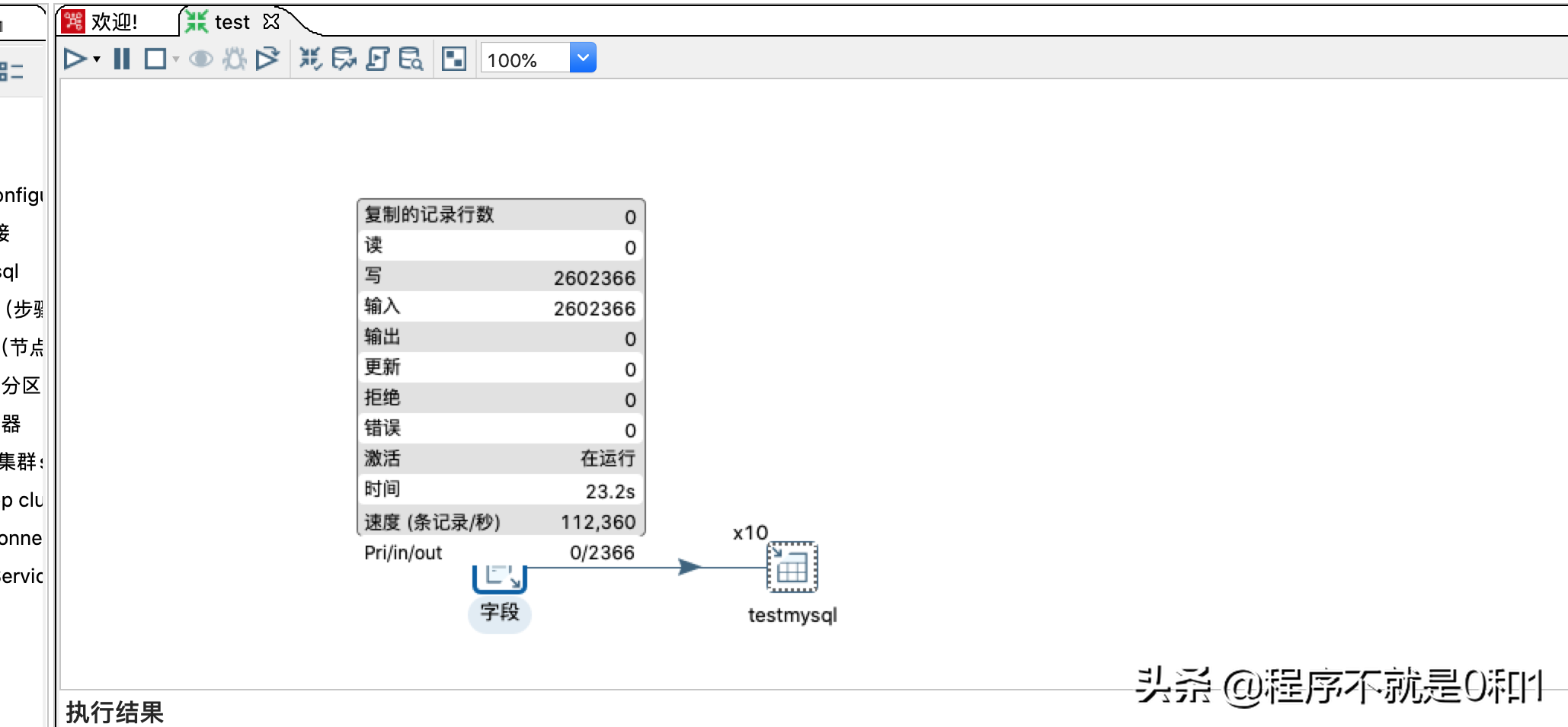
最终结果每秒读取11万条数据,最终完成1000万数据导入,2分钟不到。效率同mysqlimport命令,当然理论来说,jdbc效率是没有原生导入命令高的,所以不要指望kettle按秒来导入。
