增删改查:
插入一条数据:
insert into msg
(id,title,name,conten)
values
(2,'初来乍到','张三','那就这样吧');
一次性插入多条数据
insert into msg
(id,conten)
values
(3,'第三次','王五','爱你一万年'),
(4,'第四次','赵六','越过山丘'),
(5,'第五次','哈哈','漂洋过海来看你');
更新一条数据:
update msg
set
conten ='我爱你'
where
name = '张三';
update msg
set
conten ='我爱你'
where
name = '张三';
删除:
delete from msg; 删除整张表
delete from msg where id =2;
查(可以查询部分列部分行,部分列是通过from前面的字段控制的,部分行是通过where后面的条件控制的):
select * from msg;
select id,title from msg;
select * from msg where id>2;
所谓建表就是声明列的过程,
数据是以文件的形式存在硬盘(也有存放在内存中的)
列:不同的数据类型占的空间不一样
选列的原则:够用但不浪费
详解列类型:
整型:
Tintint(1)/smallint(2)/mediumint(3)/int(4)/bigint(8)
Tintint(1)
一个字符有八个字节,Tintint一个字符范围(0---255(2^8-1)),
Tintint默认是有符号的,存储-128(-2^7)-----127(2^7-1)之间
unsigned (无符号类型,非负0---255):
alter table class add age2 tinyint unsigned;
M:代表宽度(在zerofill时才有意义)
zerofill:零填充(如果某列zerofill,那么默认就是unsigned的)
M必须要配合zerofill才有意义,如果没有zerofill那么M也是没有意义的
列可以声明默认值,而且推荐声明默认值
Not null Default 0;
alter table class add age5 tinyint not null default 0;
浮点 float(M,D) :
M:精度(总位数,不包含小数点)
D:标度(小数位)
定点型 Decimal(M,D):
M:精度(总位数,不包含小数点)
D:标度(小数位)
Decimal相对更精确
栗如:
float(4,2) -->-99.99到+99.99
float(6,2) -->-9999.99到+9999.99
float(4,2) unsigned --->0.00到+99.99
create table goods(
name varchar (10) not null default '',
price float (6,2) not null default 0.00
)charset utf8;
insert into goods
(name,price)
values
('跑步机',688.896);
字符型:

char:定长字符串 char(M) M:代表宽度,可容纳的字符数
varchar:变长 varchar(M) M:代表宽度,可容纳的字符数
区别:
char定长:M个字符,如果存储的小于M个字符,实占M个字符,利用率可以小于或者等于100%。
varchar变长:M个字符,如果存储的小于M个字符,设为N个字符(N<M)实占N个字符,还需要一到两个字节还记录这个变长的字符真实所占用的字符数,
所以实际应该占用N+(1或者2),利用率永远是小于100%的不可能等于100%
char如果实际存储的的内容不足M个,则后面加空格补齐,
取出来的时候,在把后面的空格去掉,(所以如果内容最后有空格,将会被补齐)
M的范围的不一样,利用率不一样,对结尾处的空格处理不一样
text:不用加默认值,加了也没用
create table stu(
name varchar (10) not null default '',
waihao varchar(10) not null default ''
)charset utf8;
日期时间类型:
Year :年类型
1个字节表示 1901年-2155年,【0000年:表示错误时的年】
如果输入两位,00-69之间,表示2000到2069年
如果输入两位,70-99之间,表示1970到1999年
Date :日期类型
存储范围:1000-1-1--->9999-12-31
典型类型:1992-08-12
Time :时间类型
存储范围:-838:59:59--->838:59:59
典型格式:hh:mm:ss
DateTime:日期时间类型
就是日期跟时间类型的和,1989-05-06 14:32:08
存储范围:1000-01-01 00:00:00--->9999-12-31 23:59:59
注意:在开发的过程中很少用日期时间类型来表示精确到秒的事情,因为当碰到一些边界性的问题时容易出现问题,一般都用时间戳来表示
时间戳是1970-01-01 00:00:00 到当前的秒数,
时间戳用int来存储这样方便计算,对于显示也方便格式化
表中插入一列:
alter table goods
add
bigpeices float(9.2) not null default 0.0;
show full columns from msg;
增:
往那张表添,往那几列添加,分别的值是什么就ok了

改:

使用update时后面一定要加where这个习惯,不加有时候会出大问题
删:

只能删除行
查:
wherre

in:在值1、值2...值N,等于值1--N任意一个都行

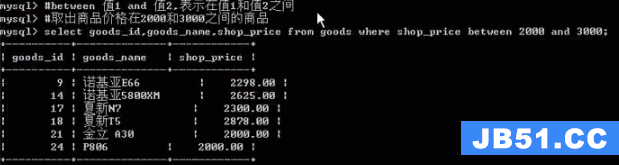
between:值1 and 值2.表示在值1和值2之间
or
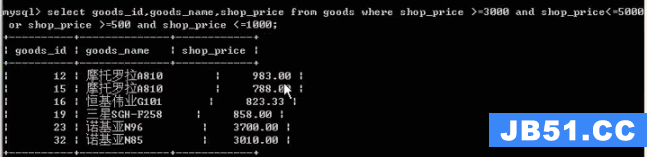
not
![]()
模糊查询:
like:像
%:通配任意字符
取goods_name包含诺基亚的数据
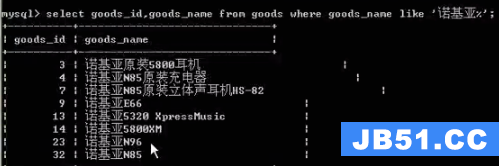
_ : 通配单个字符
取goods_name中诺基亚N**的数据:

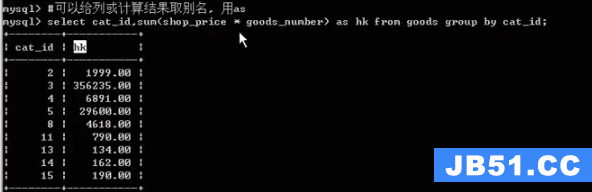
group:一般使用在统计场合,与统计函数一起使用


使用统计函数查询:
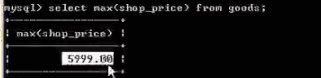
通过cat_id 来分组查询:
![]()
having:having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。
having对查出的结果进行筛选

having跟where合用

having跟group by合用



使用子查询做:

order by:
Order by语句是用来排序的,经常我们会使用到Order by来进行排序,默认是升序排列的asc
可用字段名"desc" 来声明按降序排列
![]()
order by可以按照多字段进行排序

limit:在语句的最后,起到限制条目的作用(经常跟order by配合使用)
limit[offset]N
offset:偏移量
N:取出条目
offset如果不写,则相当于limit 0,3 (limit 3) 从第一条开始取

查询的结果可以在内存中当一个表使:
![]()
子查询:
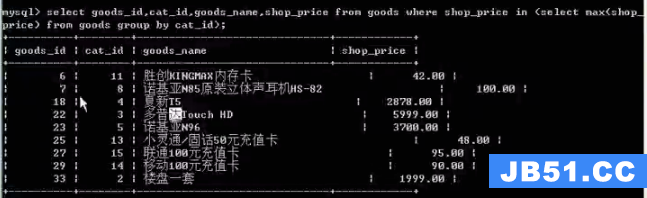
where 子查询
把内层查询的结果,当做外层查询的比较条件
典型题:查询最大商品,最贵商品

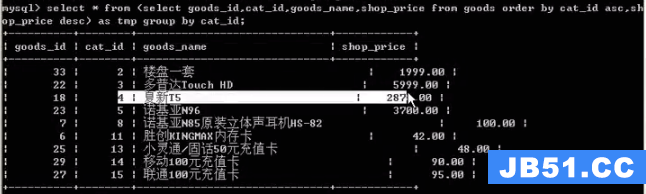
from子查询
把内层的查询结果当做临时表,供外层继续查询,加"as" 临时表名
典型题:查询每个栏目下最新/最贵的商品

exisits子查询
把外层的查询结果拿到内层,看内层的查询是否成立
典型题:查询有商品的栏目


union:联合

作用:把2次或多次查询结果合并起来
用原来的知识:
![]()
用union来做:

要求:两次查询的列数一致
推荐:查询的每一列,相对应的列类型也一样
可以来自于多张表
多次sql语句的取出的列名可以不一致,此时以第一个sql的列名为准
如果不同的语句中取出的行有完全相同的(每个列的值都相同),那么相同的行将会合并(去重复)
如果不去重复可以加all来指定(union all)
如果子句中有order by,limit这些语句需加(),推荐放到所有子句之后,即对最终排序后的结果来排序(如果只有order by来进行排序,必须要放到语句后面要不然合并后会错乱,但是如果order by跟limit合用后,合并后才不会错乱)
在子句中配合limit使用才有意义,如果order by不配合limit 使用,会被语法分析器优化分析时去除,所以对性能影响不大

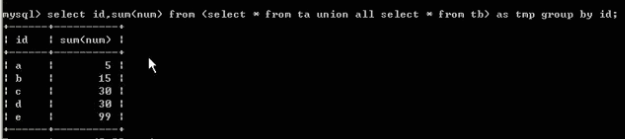
合并两张表,将id一样的值求和
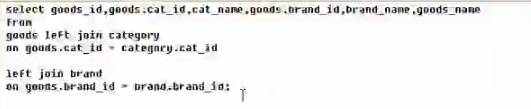
多表连接查询概念与左连接语法:
集合:无序性,唯一性
数据库里面,一张表就是一个集合,一行数据就是集合的一个元素
理论上讲不可能存在完全相同的两个行(从集合的角度出发看),但是表中可以存在完全相同的两行,因为表内部有一个rowid
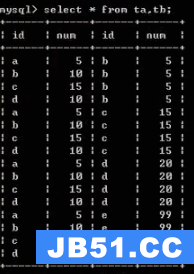
集合相乘就是笛卡尔积,其实就是两个集合的完全组合
两张表相乘(用逗号相隔):
左连接,右连接,内连接

左连接:
select 列1,列2,列N from
tableA left join tableB
on
tableA某一列 =tableB某一列 (此处表连接成一张大表,完全当成普通表看)
既然是形成了一张大表,那么where,group,having,odery by,limit照常写
栗子:

右连接:
select 列1,列N from
tableA right join tableB
on
tableA某一列 =tableB某一列 (此处表连接成一张大表,完全当成普通表看)
既然是形成了一张大表,那么where,group,having,odery by,limit照常写
内连接:inner
select 列1,列N from
tableA innner join tableB
on
tableA某一列 =tableB某一列 (此处表连接成一张大表,完全当成普通表看)
既然是形成了一张大表,那么where,group,having,odery by,limit照常写
左连接,右连接:
左连接:即以左表为基准,到右表找匹配的数据,找不到匹配的用NULL补齐。

如何记忆:(左右连接)
1.左右连接是可以相互转化的
2.可以把右连接转换为左连接来使用(并推荐左连接来代替右连接,兼容性会好一些)
A 站在 B的左边 ---》 B 站在 A的右边
A left join B ---> B right join A 是同样的。
内连接:
查询左右表都有的数据,不要左/右中NULL的那一部分
内连接是左右连接的交集。
能否查出左右连接的并集呢?
目前的mysql是不能的,它不支持外连接,outer join,可以用union来达到目的。

思考:能否查出左右连接的并集?
答:至少目前不能,目前的mysql不支持外链接(outer join),可以用union来达到目的。

第一题:
第二题:

表管理之列的增删改:

创建一张表的语法
create table tableName(
列名 列类型 [列属性] [默认值],-->把这整行看成是 列声明的一条语句
......
);
1.增加列
语法:alter tableName add 列声明
新增加的列默认放到表中的最后一列,如果要让新增的列放到具体位置
可以这样:alter tableName add 列声明 after 已有列名
如果要让新增的列排到最前面,可以这样:
alter tableName add 列声明 first
2.修改列
语法:alter talbeName change 被改变的列 列声明

3.删除列
语法:alter tableName drop 列名
1.where 后面的条件,可以理解为把这个条件带入到每一行是看,哪一行满足就执行哪一行
如果 where 1; 因为1代表真,所以每一行都会被执行到
2.要把列名当成变量名来看,可以进行加减乘除运算

3.可以给列或者运算结果取别名
小结:

创建后表的修改
alter table 语句用于创建后对表的修改,基础用法如下:
添加列
基本形式: alter table 表名 add 列名 列数据类型 [after 插入位置];
示例:
在表的最后追加列 address: alter table students add address char(60);
在名为 age 的列后插入列 birthday: alter table students add birthday date after age;
修改列
基本形式: alter table 表名 change 列名称 列新名称 新数据类型;
示例:
将表 tel 列改名为 telphone: alter table students change tel telphone char(13) default "-";
将 name 列的数据类型改为 char(16): alter table students change name name char(16) not null;
删除列
基本形式: alter table 表名 drop 列名称;
示例:
删除 birthday 列: alter table students drop birthday;
重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表为 workmates: alter table students rename workmates;
删除整张表
基本形式: drop table 表名;
示例: 删除 workmates 表: drop table workmates;
删除整个数据库
基本形式: drop database 数据库名;
示例: 删除 samp_db 数据库: drop database samp_db;
 在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信...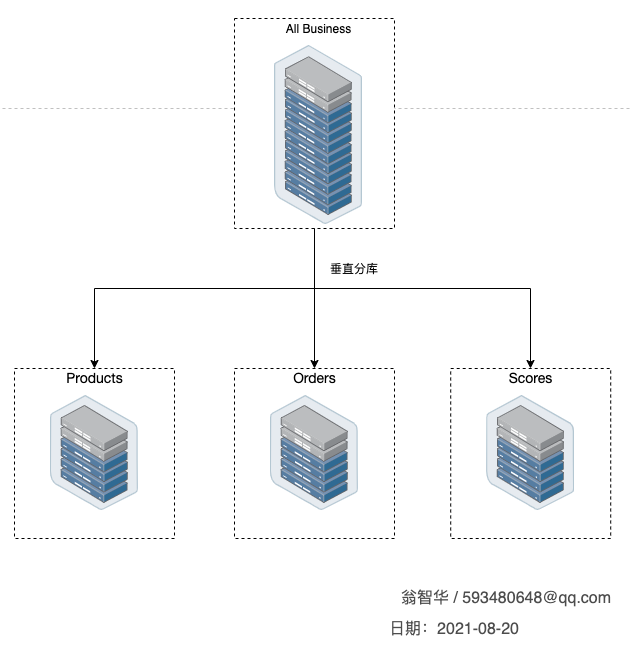 物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时...
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时... navicat查看某个表的所有字段的详细信息 navicat设计表只能一...
navicat查看某个表的所有字段的详细信息 navicat设计表只能一... 文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起...