Mycat是什么?
从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了MySQL协议的Server,前端用户可以把它看做是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生(Native)协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分库分表,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。 Mycat发展到目前版本,已经不在是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NOSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在Mycat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅度降低开发难度,提升开发速度,在测试阶段,可以将一表定义为任何一种Mycat支持的存储方式,比如MySQL的MyASM表、内存表、或者MongoDB、LeveIDB以及号称是世界上最快的内存数据库MemSQL上。 试想一下,用户表存放在MemSQL上,大量读频率远超过写频率的数据如订单的快照数据存放于InnoDB中,一些日志数据存放于MongoDB中,而且还能把Oracle的表跟MySQL的表做关联查询,你是否有一种不能呼吸的感觉?而未来,还能通过Mycat自动将一些计算分析后的数据灌入到Hadoop中,并能用Mycat+Storm/Spark Stream引擎做大规模数据分析,看到这里。Mycat原理
Mycat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了。 Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
何为数据切分?
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主 机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding )根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者 Schema )来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:|
|
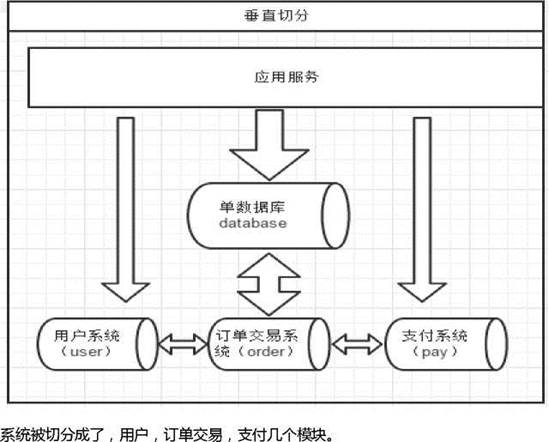
下面来分析下垂直切分的优缺点:
优点:- 拆分后业务清晰,拆分规则明确。
- 系统之间整合或扩展容易。
- 数据维护简单。
- 部分业务表无法join ,只能通过接口方式解决,提高了系统复杂度。
- 受每种业务不同的限制存在单库性能瓶颈,不易扩展跟性能提高。
- 事务处理复杂。由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
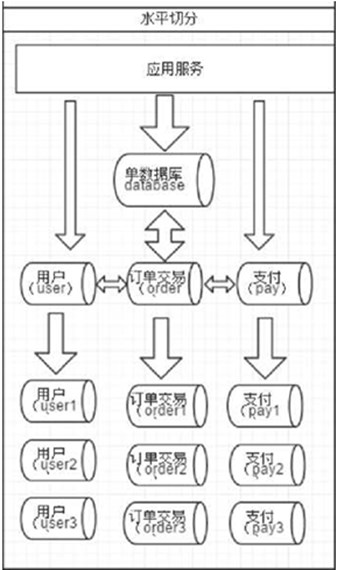
水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中,如图: