使用SqlBulkCopy提高导入数据的性能
向SQL Server中导入大量数量可以用bulk insert,但是必须要求插入的文件在数据库机器上或者一个数据库可以访问的共享文件夹中(我不知道怎么设置共享文件夹,以使得SQL Server能访问到)
SqlBulkCopy 是.net中的一个类,提供了导入大量数据的功能。
基本用法如下:
using (SqlBulkCopy bc = new SqlBulkCopy(sqlConn,SqlBulkCopyOptions.TableLock | .UseInternalTransaction,null)) { bc.BulkCopyTimeout = 10 * 60; bc.BatchSize = 10000; bc.DestinationTableName = "dbo.Destination"; bc.WriteToServer(reader); //reader 是一个继承自IDataReader的类的实例 }
自己可以写代码来实现继承自IDataReader的类。有n多成员要实现。。。
比如FieldCount, Read(), GetValue(int i), Close()等
下面是一个读文件的例子:
//返回记录的列数
public int FieldCount
{
get { return 3; }
}
//读记录,此方法会被自动调用
public bool Read()
{
if (_Reader == )
_Reader = StreamReader(_FilePath);
string line = _Reader.ReadLine();
(line != )
{
_CurrentQueryItem = GetRawData(line);
_Count++;
while (_CurrentQueryItem == )//如果读出的是不满足条件的记录,则读下一条记录
{
Read();
}
return true;
}
return false;
}
//返回一条记录中第i 列(项)的值,此方法会被自动调用
//SqlBulkCopy内部应该有一个循环,从0到FieldCount -1 ,再调用GetValue(int i)这个方法。我猜的。。。
public object GetValue(int i)
{
)
return null;
switch (i)
{
//如果数据库中表的第一列是自增字段,则会忽略第一列,也就是说此方法被调用时,i只会从1开始,所以不需要case 0的情况。估计.net内部去取目的表的schema,自动判断哪些列是需要从外部导入的。有空再研究这个问题
case 0:
_CurrentQueryItem.Item1;
1:
_CurrentQueryItem.Item2;
2:
_CurrentQueryItem.Item3;
default:
throw new IndexOutOfRangeException();
}
}
//释放资源
public void Close()
{
Dispose();
}
Dispose()
{
(_Reader != )
_Reader.Close();
}
有一些其他属性其方法需要自己实现,当然有的不实现也没关系。似乎重要的就以上几个方法了。
对照SqlDataRead,自己可以猜想出会用到哪些方法。
经过实验,一个文件如果一行一行插入到数据库里,需要大约2分钟,如果用SqlBulkCopy 10秒左右就完成了。而且可以自己实现类来指定处理什么数据,也不用把文件放在数据库机器上了。不错。
忘说了,SqlBulkCopy里用到的connction对象只能是SqlConnection。SqlBulkCopy.WriteToServer (DataRow]) 和SqlBulkCopy.WriteToServer (DataTable) 都是可以的。
 本篇内容主要讲解“sqlalchemy的常用数据类型怎么使用”,感...
本篇内容主要讲解“sqlalchemy的常用数据类型怎么使用”,感... 今天小编给大家分享一下sqlServer实现分页查询的方式有哪些的...
今天小编给大家分享一下sqlServer实现分页查询的方式有哪些的... 这篇文章主要介绍“sqlmap之osshell怎么使用”,在日常操作中...
这篇文章主要介绍“sqlmap之osshell怎么使用”,在日常操作中...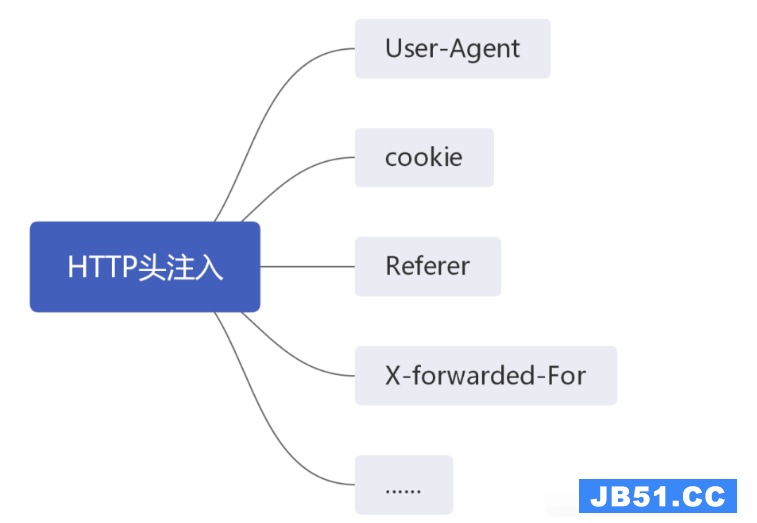 本篇内容介绍了“SQL注入的知识点有哪些”的有关知识,在实际...
本篇内容介绍了“SQL注入的知识点有哪些”的有关知识,在实际... 1. mssql权限sa权限:数据库操作,文件管理,命令执行,注册...
1. mssql权限sa权限:数据库操作,文件管理,命令执行,注册... sql执行计划如何查看?在SPL庞大的数据中我们不知道如何查看...
sql执行计划如何查看?在SPL庞大的数据中我们不知道如何查看...