认识Mongo数据库
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
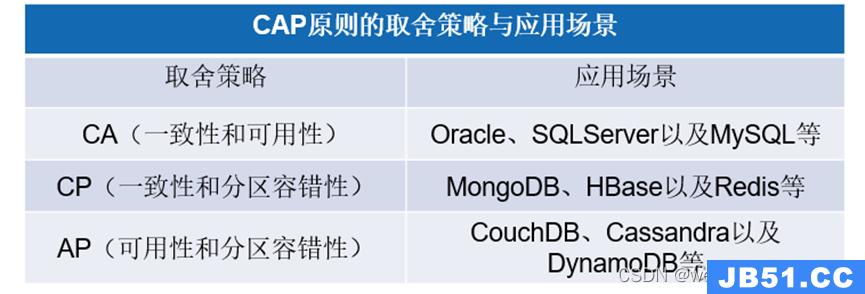
分布式系统
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
什么是Nosql?
Nosql,指的是非关系型的数据库。Nosql有时也称作Not Only sql的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
Nosql用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
为什么使用Nosql ?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那sql数据库已经不适合这些应用了, Nosql 数据库的发展却能很好的处理这些大的数据。
主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=“Sameer”,Address=“8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runcommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
Mongo历史
- 2007年10月,MongoDB由10gen团队所发展。2009年2月首度推出。
- 2012年05月23日,MongoDB2.1 开发分支发布了! 该版本采用全新架构,包含诸多增强。
- 2012年06月06日,MongoDB 2.0.6 发布,分布式文档数据库。
- 2013年04月23日,MongoDB 2.4.3 发布,此版本包括了一些性能优化,功能增强以及bug修复。
- 2013年08月20日,MongoDB 2.4.6 发布。
- 2013年11月01日,MongoDB 2.4.8 发布。
安装
点击去官网下载对应版本mongo下载,linux版本下载完成解压即可!
Linux下命令安装:sudo yum install libcurl openssl
Mongo的使用
Mongo的默认端口是
27017Mongo兼容MysqL的语句。
创建数据库:
# 如果数据库不存在,则创建数据库,否则切换到指定数据库。
use DATABASE_NAME;
查看数据库:
show dbs;
# 示例
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
>
db.dropDatabase();
创建集合:
# name为表名
db.createCollection(name)
查看集合:
如果要查看已有集合,可以使用 show collections;或 show tables;命令:
删除集合:
# COLLECTION_NAME为集合名
db.COLLECTION_NAME.drop()
插入文档:
# 文档的数据结构和 JSON 基本一样。
# 所有存储在集合中的数据都是BSON格式。
# BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
db.COLLECTION_NAME.insert(document)
db.COLLECTION_NAME.save(document)
修改文档:
# 旧数据 新数据
db.code.update({name:"admin"},{$set:{name:"ichpan"}})
移除文档:
# COLLECTION_NAME为集合名
db.COLLECTION_NAME.remove({'title':'MongoDB 教程'})
查询数据:
# find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 sql 的 AND 条件。
# 以易读的方式来读取数据 .pretty()
# 除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
# 查询集合中的所有数据
db.COLLECTION_NAME.find().pretty()
# 根据查询集查询 query为BSON格式
db.COLLECTION_NAME.find(query).pretty()
备注:mongo中也可以使用逻辑运算符查询数据。
MongoDB 条件操作符:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
创建索引:
# Key值为你要创建的索引字段,1为指定按升序创建索引,按降序来创建索引指定为-1
db.COLLECTION_NAME.createIndex(keys, options)
# 创建一个过期索引 设置expireAfterSeconds
# datetime: 创建索引所在的字段 为date形式
# expireAfterSeconds:为过期时间 表示300秒后删除数据
db.code.createIndex({"datetime":1},{expireAfterSeconds:300});
createIndex() 接收可选参数,参数如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | **3.0+版本已废弃。**在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
在项目中使用mongo
将mongo封装成类,使用的时候调用即可。
import pymongo
import pytz # 时区
class MongoDB:
def __init__(self):
self.client = pymongo.MongoClient(host="127.0.0.1", port=27017, tz_aware=True,
tzinfo=pytz.timezone("Asia/Shanghai"))
self.db = self.client.mytornado
self.table = self.db.code
def insert_one(self, data):
return self.table.insert_one(data)
def find_one(self, data):
return self.table.find_one(data)
def find_many(self, data):
return self.table.find_many(data)
def remove(self, data):
return self.table.remove(data)
def update(self, old_data, new_data):
return self.table.update(new_data)
小结
mongo使用广泛,成本是低于Redis的,很多公司都是用的是Mongo数据库,我们今天了解了它的历史,基本使用,更多高阶的操作还是得慢慢去看官方文档,感谢观看。