lua的coroutine 跟thread 的概念比较相似,但是也不完全相同。一个multi-thread的程序,可以同时有多个thread 在运行,但是一个multi-coroutines的程序,同一时间只能有一个coroutine 在运行,而且当前正在运行的coroutine 只有在被显式地要求挂起时,才会挂起。Lua的coroutine 是一个强大的概念,尽管它的几个主要应用都比较复杂。
1. Coroutine 基础
Lua将coroutine相关的所有函数封装在表coroutine 中。create 函数,创建一个coroutine ,以该coroutine 将要运行的函数作为参数,返回类型为thread 。

coroutine 有4个不同的状态:suspended,running,dead,normal。当新create 一个coroutine的时候,它的状态为suspended ,意味着在create 完成后,该coroutine 并没有立即运行。我们可以用函数status 来查看该coroutine 的状态:

函数coroutine.resume (恢复)运行该coroutine,将其状态从suspended变为running:

在该示例中,该coroutine运行,简单地输出一个“hi”就结束了,该coroutine变为dead状态:

到目前为止,coroutine看起来好像也就这么回事,类似函数调用,但是更复杂的函数调用。但是,coroutine的真正强大之处在于它的yield 函数,它可以将正在运行的coroutine 挂起,并可以在适当的时候再重新被唤醒,然后继续运行。下面,我们先看一个简单的示例:

我们一步一步来讲,该coroutine每打印一行,都会被挂起,看起来是不是在运行yield 函数的时候被挂起了呢?当我们用resume 唤醒该coroutine时,该coroutine继续运行,打印出下一行。直到最后没有东西打印出来的时候,该coroutine退出循环,变为dead状态(注意最后那里的状态变化)。如果对一个dead状态的coroutine进行resume 操作,那么resume会返回false+err_msg,如上面最后两行所示。
注意,resume 是运行在protected mode下。当coroutine内部发生错误时,Lua会将错误信息返回给resume 调用。
当一个coroutine A在resume另一个coroutine B时,A的状态没有变为suspended,我们不能去resume它;但是它也不是running状态,因为当前正在running的是B。这时A的状态其实就是normal 状态了。
Lua的一个很有用的功能,resume-yield对,可以用来交换数据。下面是4个小示例:
1)main函数中没有yield,调用resume时,多余的参数,都被传递给main函数作为参数,下面的示例,1 2 3分别就是a b c的值了:

2)main函数中有yield,所有被传递给yield的参数,都被返回。因此resume的返回值,除了标志正确运行的true外,还有传递给yield的参数值:

3)yield也会把多余的参数返回给对应的resume,如下:

为啥第一个resume没有任何输出呢?我的答案是,yield没有返回,print就根本还没运行。
4)当一个coroutine结束的时候,main函数的所有返回值都被返回给resume:

我们在同一个coroutine中,很少会将上面介绍的这些功能全都用上,但是所有这些功能都是很useful的。
目前为止,我们已经了解了Lua中coroutine的一些知识了。下面我们需要明确几个概念。Lua提供的是asymmetric coroutine,意思是说,它需要一个函数(yield)来挂起一个coroutine,但需要另一个函数(resume)来唤醒这个被挂起的coroutine。对应的,一些语言提供了symmetric coroutine,用来切换当前coroutine的函数只有一个。
有人想把Lua的coroutine称为semi-coroutine,但是这个词已经被用作别的意义了,用来表示一个被限制了一些功能来实现出来的coroutine,这样的coroutine,只有在一个coroutine的调用堆栈中,没有剩余任何挂起的调用时,才会被挂起,换句话说,就是只有main可以挂起。Python中的generator好像就是这样一个类似的semi-coroutine。
跟asymmetric coroutine和symmetric coroutine的区别不同,coroutine和generator(Python中的)的不同在于,generator并么有coroutine的功能强大,一些用coroutine可实现的有趣的功能,用generator是实现不了的。Lua提供了一个功能完整的coroutine,如果有人喜欢symmetric coroutine,可以自己简单的进行一下封装。
couroutine的一个典型的例子就是producer-consumer问题。我们来假设有这样两个函数,一个不停的produce一些值出来(例如从一个file中不停地读),另一个不断地consume这些值(例如,写入到另一个file中)。这两个函数的样子应该如下:
这两个函数都不停的在执行,那么问题来了,怎么来匹配send和recv呢?究竟谁先谁后呢?
coroutine提供了解决上面问题的一个比较理想的工具resume-yield。我们还是不说废话,先看看代码再来说说我自己的理解:
copy






 1.github代码实践源代码是lua脚本语言,下载th之后运行thmai...
1.github代码实践源代码是lua脚本语言,下载th之后运行thmai... 此文为搬运帖,原帖地址https://www.cnblogs.com/zwywilliam/...
此文为搬运帖,原帖地址https://www.cnblogs.com/zwywilliam/... Rime输入法通过定义lua文件,可以实现获取当前时间日期的功能...
Rime输入法通过定义lua文件,可以实现获取当前时间日期的功能...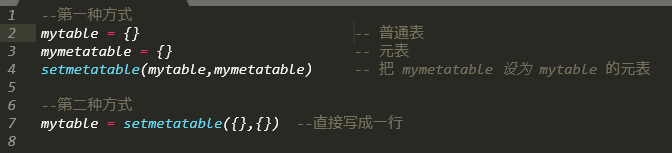 在Lua中的table(表),就像c#中的HashMap(哈希表),key和...
在Lua中的table(表),就像c#中的HashMap(哈希表),key和...