我尝试在
http://lxr.linux.no/#linux+v2.6.38/arch/x86/lib/string_32.c下对优化的字符串操作进行基准测试,并与常规strcpy进行比较:
#include<stdio.h>
#include<stdlib.h>
char *_strcpy(char *dest,const char *src)
{
int d0,d1,d2;
asm volatile("1:\tlodsb\n\t"
"stosb\n\t"
"testb %%al,%%al\n\t"
"jne 1b"
: "=&S" (d0),"=&D" (d1),"=&a" (d2)
: "0" (src),"1" (dest) : "memory");
return dest;
}
int main(int argc,char **argv){
int times = 1;
if(argc >1)
{
times = atoi(argv[1]);
}
char a[100];
for(; times; times--)
_strcpy(a,"Hello _strcpy!");
return 0;
}
并使用(time ..)显示它比常规strcpy(在x64 linux下)慢约x10
为什么?
解决方法
如果您的字符串是常量,则编译器可能正在内联副本(对于plain strcpy调用),使其成为一系列无条件MOV指令. 因为这是无条件的线性代码,所以它比linux变体更快.
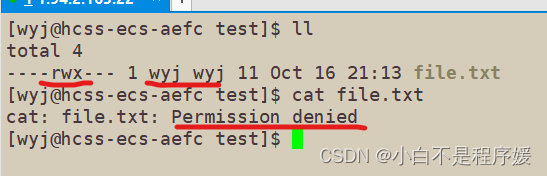 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...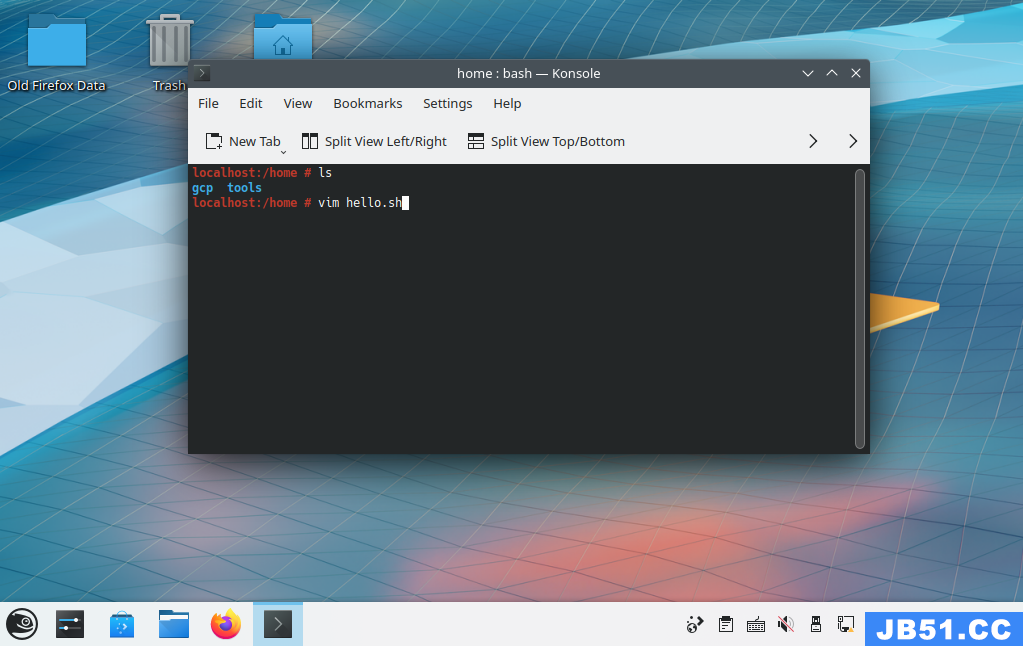 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin... 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...