我问,因为我正在测试具有1TB RAM的192核心机器上的400GB数据文件,该文件在测试之前预先缓存到页面缓存中(通过删除缓存,然后对文件执行md5sum) .
最初,我有所有192个线程,每个mmap单独mmap文件,假设他们将(基本上)得到(基本上)相同的内存区域(或可能相同的内存区域,但不知何故映射多次).因此,我假设使用两个不同映射到同一文件的两个线程都可以直接访问相同的页面. (让我们在这个例子中忽略NUMA,但显然它在较高的线程数时很重要.)
但是,实际上我发现当每个线程分别对文件进行映射时,线程计数会更高,性能会变得很糟糕.当我们删除它而只是做了一个传递给线程的mmap(这样所有线程只是直接访问相同的内存区域),然后性能得到了显着提高.
这一切都很棒,但我想弄明白为什么.如果事实上mmapping文件只是授予对现有页面缓存的直接访问权限,那么我认为映射它的次数并不重要 – 它应该全部转到完全相同的位置.
但鉴于存在这样的性能成本,在我看来,实际上每个mmap都是独立且冗余填充的(可能是通过从页面缓存中复制,或者可能是从磁盘再次读取).
您能否评论为什么我在同一内存的共享访问与映射同一文件之间看到如此不同的性能?
谢谢,谢谢你的帮助!
解决方法
基本上,每个mmap()都在虚拟内存中创建一个新范围.该范围的每个页面对应一个物理内存页面,该映射存储在分层页面目录中 – 每4KB页面有一个条目.因此,大区域的每个mmap()都会在页面目录中生成大量条目.
我的猜测是它实际上并没有预先定义它们,这就是为什么即使对于一个巨大的文件,mmap()也可以即时调用.但随着时间的推移,它可能必须建立这些条目,因为mmapped范围存在缺陷,这意味着随着时间的推移它被填写.填充页面目录的额外工作可能是使用不同mmaps的线程比共享同一mmap的线程慢的原因.我打赌内核需要在取消映射范围时擦除所有这些条目 – 这就是unmmap()速度太慢的原因.
(还有翻译后备缓冲区,但这是每个CPU,而且这么小我觉得这里不重要.)
无论如何,这听起来像重新映射相同的区域只会增加额外的开销,因为在我看来似乎没有收获.
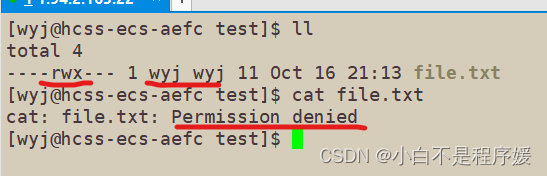 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi... 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin... 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...