我有很多巨大的文本文件,需要以尽可能高的比率进行压缩.只要减压速度相当快,压缩速度可能会很慢.
这些文件中的每一行都包含一个数据集,它们可以按任何顺序存储.
与此类似的问题:
Sorting a file to optimize for compression efficiency
但对我来说压缩速度不是问题.是否有现成的工具将类似的线组合在一起?或者也许只是我可以实现的算法?
单独排序有一些改进,但我怀疑还有更多可能.
每个文件大约有6亿行,每个大约40个字节,总共24GB.用xz压缩到~10GB
解决方法
这是一个相当天真的算法:
>随机选择一个初始行并写入压缩流.
>剩余线路> 0:
>保存压缩流的状态
>对于文本文件中的每个剩余行:
>将该行写入压缩流并记录生成的压缩长度
>回滚到压缩流的已保存状态
>将导致压缩长度最短的行写入压缩流
>释放已保存的状态
这是一个贪婪的算法,并不是全局最优的,但它应该非常好地匹配在一个接一个地跟随时压缩良好的行.这是O(n2),但你说压缩速度不是问题.它的主要优点在于它是经验性的:它不依赖于关于哪个线序将压缩得很好但实际测量它的假设.
如果你使用zlib,它提供了一个复制压缩流状态的函数deflateCopy,虽然它显然非常昂贵.
编辑:如果您在尝试最小化序列中所有行对之间的总编辑距离时输出序列中的所有行来解决此问题,则此问题将减少为旅行商问题,编辑距离为“距离”并且所有行都是您必须访问的节点.因此,您可以查看the various approaches问题,并将其应用于此问题.即使这样,编辑距离方面的最佳TSP解决方案也不一定是压缩最小的文件/
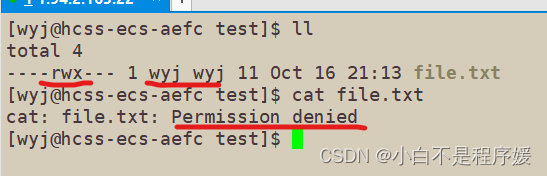 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi... 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...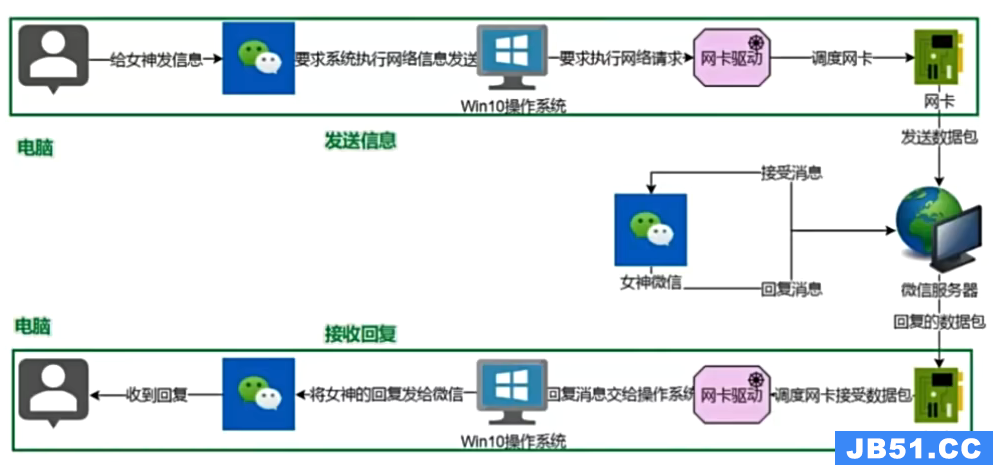 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...