我想知道使用Perl DBI从Oracle数据库中提取任意大数据字段的最节省内存的方法.我知道使用的方法是将数据库句柄上的“LongReadLen”属性设置为足够大的值.但是,我的应用程序需要提取数千条记录,因此这样做是非常低效的内存效率.
doc建议事先进行查询以找到最大的潜在价值,然后进行设置.
$dbh->{LongReadLen} = $dbh->selectrow_array(qq{
SELECT MAX(OCTET_LENGTH(long_column_name))
FROM table WHERE ...
});
$sth = $dbh->prepare(qq{
SELECT long_column_name,... FROM table WHERE ...
});
然而,这仍然是低效的,因为外围数据不代表每个记录.最大值超过MB,但平均记录小于KB.我希望能够在尽可能少浪费未使用的缓冲区的同时提取所有信息(即,不截断).
我考虑过的一种方法是以块的形式提取数据,一次说50条记录,并将LongReadLen设置为该块的最大记录长度.另一个可以但不必依赖于块构思的工作是分叉子进程,检索数据,然后杀死子进程(利用它浪费内存).最棒的是强制释放DBI缓冲区的能力,但我认为这不可行.
有没有人解决类似问题取得任何成功?谢谢您的帮助!
编辑
Perl v5.8.8,DBI v1.52
澄清一下:内存效率低下来自于使用’LongReadLen’和{ora_pers_lob => 1}在准备中.使用此代码:
my $sql = "select myclob from my table where id = 68683";
my $dbh = DBI->connect( "dbi:Oracle:$db",$user,$pass ) or croak $DBI::errstr;
print "before";
readline( *STDIN );
$dbh->{'LongReadLen'} = 2 * 1024 * 1024;
my $sth = $dbh->prepare( $sql,{'ora_pers_lob' => 1} ) or croak $dbh->errstr;
$sth->execute() or croak( 'Cant execute_query '. $dbh->errstr . ' sql: ' . $sql );
my $row = $sth->fetchrow_hashref;
print "after";
readline( *STDIN );
“之前”的驻留内存使用量为18MB,“之后”的使用量为30MB.这在大量查询中是不可接受的.
最佳答案
您的列是否包含大数据LOB(CLOB或BLOB)?如果是这样,您根本不需要使用LongReadLen; DBD :: Oracle提供了LOB流接口.
你想要做的是bind the param作为类型ORA_CLOB或ORA_BLOB,它将获得从查询返回的“LOB定位器”,而不是tex.然后使用ora_lob_read和LOB定位器来获取数据.这是一个对我有用的代码示例:
sub read_lob {
my ( $dbh,$clob ) = @_;
my $BLOCK_SIZE = 16384;
my $out;
my $offset = 1;
while ( my $data = $dbh->ora_lob_read( $clob,$offset,$BLOCK_SIZE ) ) {
$out .= $data;
$offset += $BLOCK_SIZE;
}
return $out;
}
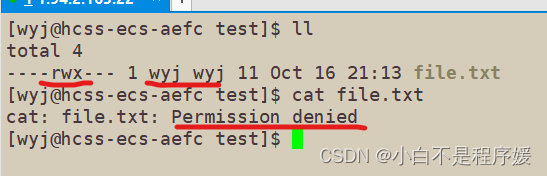 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...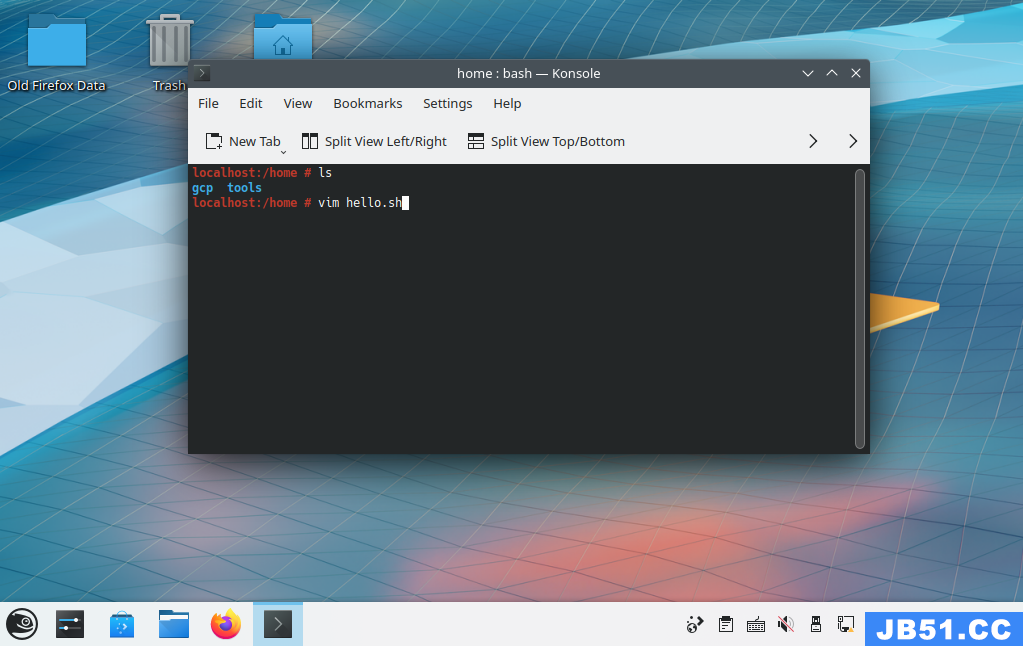 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin... 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...