通过自动修剪超过20分钟的文件,数百万个小文件(平均约50 KB)的大容量存储的优秀策略是什么?我需要从Web服务器编写和访问它们.
我目前正在使用ext4,并且在删除期间(在cron中安排)硬盘使用率高达100%,[flush-8:0]显示为创建负载的进程.此负载会干扰服务器上的其他应用程序.如果没有删除,则最大HDD利用率为0-5%.嵌套和非嵌套目录结构的情况相同.最糟糕的是,峰值负载期间的质量去除似乎比插入速率慢,因此需要删除的文件数量越来越大.
我尝试过更改调度程序(截止日期,cfq,noop),但它没有帮助.我也试过设置ionice来删除脚本,但它也没有帮助.
我已经尝试过使用MongoDB 2.4.3的GridFS,它表现很好,但在大量删除旧文件时很糟糕.我已经尝试运行MongoDB关闭日志(nojournal)并且没有写入确认删除和插入(w = 0)并且它没有帮助.只有在没有删除的情况下,它才能快速顺畅地工作.
我还尝试在InnoDB表中的BLOB列中的MySQL 5.5中存储数据,InnoDB引擎设置为使用innodb_buffer_pool = 2GB,innodb_log_file_size = 1GB,innodb_flush_log_on_trx_commit = 2,但性能更差,HDD负载总是在80% – 100%(预计,但我不得不尝试).表仅使用BLOB列,DATETIME列和CHAR(32)latin1_bin UUID,其中包含UUID和DATETIME列的索引,因此没有优化空间,并且所有查询都使用索引.
我已经研究了pdflush设置(在大规模删除过程中创建负载的Linux刷新过程),但更改值对任何事情没有帮助,所以我恢复为默认值.
我运行自动修剪脚本的频率并不重要,每1秒,每1分钟,每5分钟,每30分钟一次,无论哪种方式都严重扰乱服务器.
我试图存储inode值,并在删除时,先按顺序删除旧的文件,然后用它们的inode编号排序,但它没有帮助.
使用CentOS 6. HDD是SSD RAID 1.
对于解决自动修剪性能问题的任务,什么是好的和合理的解决方案?
他们真的需要单独的文件吗?是否真的需要删除旧文件,或者如果它们被覆盖就可以了吗?
如果第二个问题的答案是“否”,请尝试以下方法:
>保留按年龄粗略排序的文件列表.也许按文件大小来缩小它.
>如果要写入新文件,请找到一个旧文件,该文件最好大于您要替换它的文件.而不是吹走旧文件,将其截断()到适当的长度,然后覆盖其内容.确保更新旧文件列表.
>清理偶尔没有明确替换的旧东西.
>对这些文件建立索引可能是有利的.尝试使用一个完整的符号链接到真实文件系统的tmpfs.
通过将文件分块到可管理大小的子目录,您可能会或可能不会在此方案中获得性能优势.
如果你可以在同一个文件中存在多个内容:
>将相似大小的文件保存在一起,将每个文件作为偏移量存储到类似大小的文件数组中.如果每个文件都是32k或64k,请保留一个满32k块的文件和一个满64k块的文件.如果文件具有任意大小,则向上舍入到下一个2的幂.
>您可以通过跟踪每个文件的陈旧程度来执行延迟删除操作.如果您正在尝试编写并且某些东西过时,请覆盖它而不是附加到文件的末尾.
另一个想法是:通过截断()以inode顺序将所有文件截断为长度0然后取消链接()来获得性能优势吗?无知阻止我知道这是否真的有用,但似乎它会将数据归零并且元数据类似地编写在一起.
还有一个想法:XFS的写入排序模型比ext4弱,data = ordered.在XFS上它足够快吗?
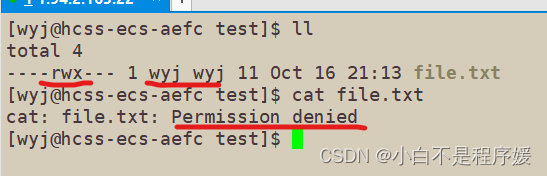 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi... 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...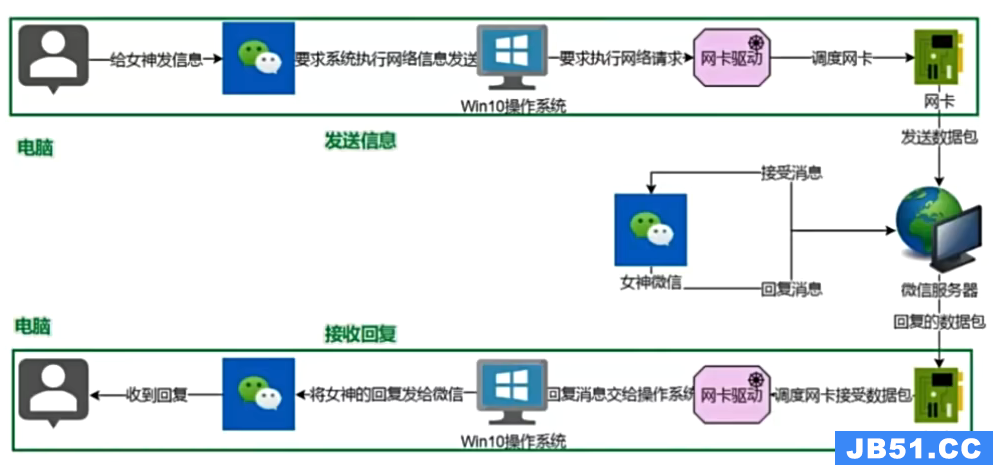 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...