到目前为止,没有证据表明任何磁盘存在硬件错误.到目前为止,SMART状态看起来很好.
即使在/etc/mdadm/mdadm.conf中打开了电子邮件通知,我也从未收到过mdadm的电子邮件通知.
此服务器还配置为将所有系统日志消息转发到日志主机,因此我检查了我的日志主机.相关部分是:
May 20 15:38:40 kernel: [ 1.869825] md0: detected capacity change from 0 to 536858624 May 20 15:38:40 kernel: [ 1.870687] md0: unknown partition table May 20 15:38:40 kernel: [ 1.877412] md: bind May 20 15:38:40 kernel: [ 1.878337] md/raid1:md1: not clean -- starting background reconstruction May 20 15:38:40 kernel: [ 1.878376] md/raid1:md1: active with 2 out of 2 mirrors May 20 15:38:40 kernel: [ 1.878418] md1: detected capacity change from 0 to 3000052808704 May 20 15:38:40 kernel: [ 1.878575] md: resync of RAID array md1 [snip] May 20 15:52:33 kernel: Kernel logging (proc) stopped. May 20 15:52:33 rsyslogd: [origin software="rsyslogd" swVersion="5.8.6" x-pid="845" x-info="http://www.rsyslog.com"] exiting on signal 15.
如您所见,系统(正常的系统,而不是救援系统)已经在系统启动期间检测到RAID阵列出现问题.然后,不久之后,某些东西(不是我)停止了系统.
所以我的问题是:
>什么可能导致磁盘突然变得不同步?
>为什么我没有收到电子邮件通知?
>为什么在暂停系统之前错误未正确记录到syslog中?可能是系统尝试登录到syslog,但是在停止syslog守护进程后这样做了吗?如果是这样我该怎么做才能防止这种情况?
>我能做些什么来了解发生了什么?或者,如果我现在无法找到发生的事情,我怎样才能改进日志记录和通知,以便下次我可以做更好的验尸?
我的问题不是适当的备份实践.我已经知道RAID不是备份等.我的问题仅仅是通知和诊断.
解决方法
What could cause the disks to suddenly become out of sync?
它可能是驱动器盘片与内存中数据之间路径中的任何硬件或软件故障.这可能意味着,但不限于:驱动器头,驱动器控制器,电缆上的连接头,电缆本身(内部断线),电缆插入驱动器的端口,主板上的端口或子卡,主板或子卡上的控制器芯片,甚至是软件故障(某处).
真实的故事:我曾经有一个片状的RAID镜像,无缘无故地放下了一个驱动器.驱动器检查完好,盘片很干净(重复SMART传递没有任何结果),一切都运行良好 – 直到它再次剥落.我更换了3美元的SATA线缆,问题立即消失了.故事的道德:如果不检查数据路径中的每个组件,就会出现很多可能出错的情况,并且你不能总是认为“一切都很好”.
Why was I not notified by email?
电子邮件通知仅在以下情况下发生:(a)主动监视阵列,或(b)询问阵列时.
我的建议是:你需要让mdadm主动监视驱动器阵列作为一个过程.这可以用类似于(但不完全像)的东西来完成:
mdadm --monitor --scan --syslog
您需要将上述行调整为特定安装.
Why was the error not properly logged to syslog before halting the system? Could it be that the system tried to log to syslog,but did so after stopping the syslog daemon? If so what can I do to prevent that?
可能存在导致日志记录被丢弃的各种问题.
首先,整个syslog如何工作的问题;虽然多年来已经使其变得强大和可靠,但是在某些边缘情况下数据可能无法进入磁盘.这是一个众所周知的设计问题,并且通过监督式服务管理(又名daemontools及其同类)积极解决.解决方案是完全绕过syslog并将输出写入始终具有打开文件描述符的记录器,因此不会丢弃任何内容,并且记录器会尽快将输出转储到磁盘;虽然它不是100%有效的解决方案,但它确实显着提高了在内核发生混乱或关闭之前将事件写入驱动器的几率.
其次,内核可能会出现彻底的恐慌,或者发生一些会导致机器进入角落的其他事件.即使是有故障的硬件也可能导致问题 – 我见过机器动力学不足的机器会导致Windows 8自发停机.更换PSU会永久性地解决停机问题.显然,内核无法做到的任何事情都可以防范刚刚决定“我已经受够了”的机器并且蹒跚着重新启动了陆地.
What can I do to find out what happened? Or,if there’s no way for me now to find out what happened,how can I improve logging and notifications so that next time I can do a better post-mortem?
有几种方法:
>将日志记录放在单独的分区上.虽然这不能保证您将获得完整的日志,但它确实有助于隔离文件系统问题,例如磁盘完全无法写入,导致重新装入只读的损坏等.它肯定有助于那些具体案例.>查看远程日志记录重要系统信息.同样,这不是一个保证,但如果最后一个数据包可以在重启之前“突破门”,这将有所帮助,并且该数据包具有重新启动发生原因的关键线索.>对于特定的关键服务,请查看使用其他内容替换输出到syslog,例如监督样式的日志记录,其中专用记录器拦截输出并尽快将其写入磁盘.这增加了输出的可靠性,使其成为存储.只需一点点工作,就可以与其他服务管理安排并存.
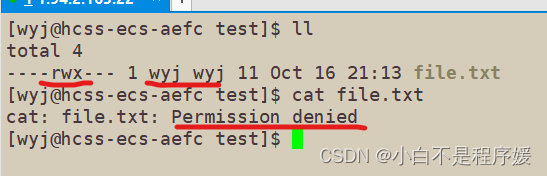 文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限...
文章浏览阅读1.8k次,点赞63次,收藏54次。Linux下的目录权限... 文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi...
文章浏览阅读1.6k次,点赞44次,收藏38次。关于Qt的安装、Wi... 本文介绍了使用shell脚本编写一个 Hello
本文介绍了使用shell脚本编写一个 Hello 文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...
文章浏览阅读1.5k次,点赞37次,收藏43次。【Linux】初识Lin...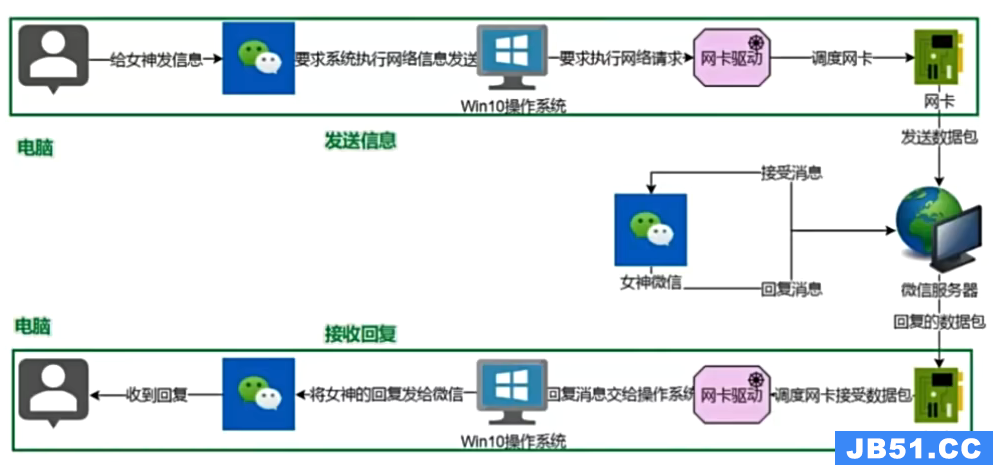 文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,...
文章浏览阅读3k次,点赞34次,收藏156次。Linux超详细笔记,... 文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...
文章浏览阅读6.8k次,点赞109次,收藏114次。【Linux】 Open...