前言
对于服务端开发的同学对mysql应该不陌生,尽管mysql5.7之后单表可存放的数据量超过千万都不是问题,但是单表的数据量一旦上去之后,带来的一个很明显的问题就是,在应用端,接口响应将会边长;
虽然可以通过索引来解决一部分查询性能问题,但数据量继续增长的话,单表的查询性能始终是一个绕不开的问题;
如何解决mysql查询性能的问题是困扰很多DBA或服务端开发的现状,从源头来看,最根本的还是要减少单表的数据量过大的问题;
于是行业中就出现了“分库分表”的解方案,这里就不再过多展开了,有兴趣的同学可以查阅相关资料;
常用的分库分表的形式,主要是两种:垂直拆分和水平拆分。
分库分表策略简述
一、垂直拆分
1、垂直分库
- 以表为依据,根据业务将原本单库中的多个表拆分到不同库下面去;
2、垂直分库特点
- 每个库的表结构都不一样;
- 每个库的数据也不一样;
- 所有库的并集是全量数据;
3、垂直分表
- 以字段为依据,根据字段属性将一张表中的多个字段拆分到不同表中去;
4、垂直分表特点
- 每个表的结构都不一样;
- 每个表的数据也不一样,一般通过一列(主键/外键)关联;
- 所有表的并集是全量数据;
二、水平拆分
1、水平分库
- 以字段为依据,按照一定策略,将一个库的数据拆分到多个库中;
2、水平分库特点
- 每个库的表结构都一样;
- 每个库的数据都不一样;
- 所有库的并集是全量数据;
3、水平分表
- 以字段为依据,按照一定策略,将一个表的数据拆分到多个表中去;
4、水平分表特点
- 每个表的表结构都一样;
- 每个表数据都不一样;
- 所有表的并集是全量数据;
分库分表常用解决方案
- 基于AOP实现,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处
理。需要自行编码配置实现,只支持java语言,性能较高,支持多种分片策略,通常只需要在配置文件做相关的配置就可以使用,上手成本较低; - MyCat,数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能方面相对shardingJDBC弱一些;
关于shardingJdbc 的用法,可以参考:shardingJdbc使用
mycat简介
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件,客户端可以像连接mysql一样来使用mycat,就像感觉不到mycat的存在;
具体来说,客户端只需要连接MyCat即可,具体底层用到几台数据库,每台数据库服务器里面存储了什么数据,都无需关心,这个交由mycat来处理,实际业务中的分库分表策略,可以根据需要在相关的配置文件配置即可;
如下为mycat的一个原理简图;
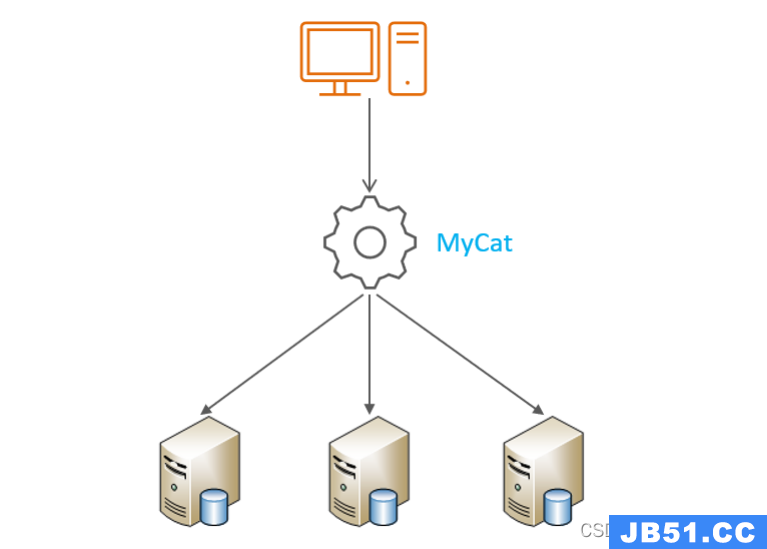
mycat目前已经发展到mycat2了,整体来说,mycat作为一款优秀的数据库代理中间件,还是有诸多的优势的,总结如下:
- 性能可靠稳定(经过众多厂商的生产实践);
- 社区较为活跃;
- 体系比较完善,支持分库分表,可以根据业务需要,定制灵活的配置策略等;
服务规划
下面演示 基于centos7 快速搭建起mycat的使用环境,服务规划如下,3个mysql实例将会使用docker安装,以端口号进行区分
| IP | PORT | 角色 |
|---|---|---|
| 101.34.33.77 | 8066 | mycat访问端口 |
| 101.34.33.77 | 3306 | mysql实例1 |
| 101.34.33.77 | 3307 | mysql实例2 |
| 101.34.33.77 | 3308 | mysql实例3 |
mysql 实例搭建
为了使用方便,使用docker 快速搭建起3个mysql的实例,以不同的端口号做区分,搭建步骤如下:
1、创建目录
mkdir -p /usr/local/docker/mysql/data /usr/local/docker/mysql/logs /usr/local/docker/mysql/conf
2、启动 mysql 实例
docker run -p 3306:3306 --name mysql_1 -v /usr/local/docker/mysql/conf:/etc/mysql/conf.d -v /usr/local/docker/mysql/logs:/logs -v /usr/local/docker/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
关于拉取mysql 的镜像的步骤这里省略了,相信使用过docker的同学应该都会了,按照上面同样的方式,创建目录并且再启动另外2个mysql的实例,效果如下,说明mysql的准备工作完成

启动之后,使用navicat分别连接,并且在3个mysql服务实例下创建名称为 “db01” 的数据库;
到这里,准备工作就初步完成
mycat 搭建过程
一、mycat下载地址
http://dl.mycat.org.cn/
1、选择并下载选择合适的版本
本文使用的是 1.6.7.4的版本

2、上传下载包到指定目录并解压
tar -zxvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz

3、进入解压后的目录,修改配置文件
找到conf目录下的schema.xml文件和server.xml两个文件,接下来,重点对schema.xml文件进行配置说明(最好提前备份下这两个文件)
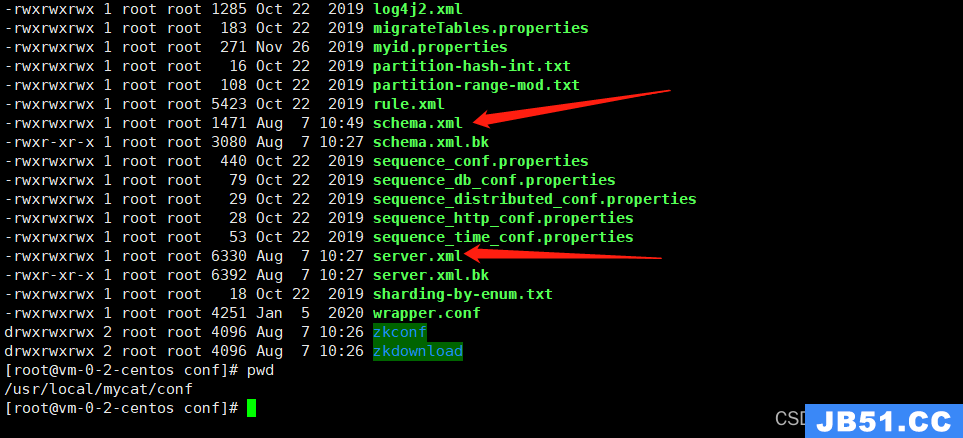
在正式对这两个配置文件进行配置之前,有必要了解下关于schema.xml配置文件中的目录结构;
schema.xml 配置文件说明
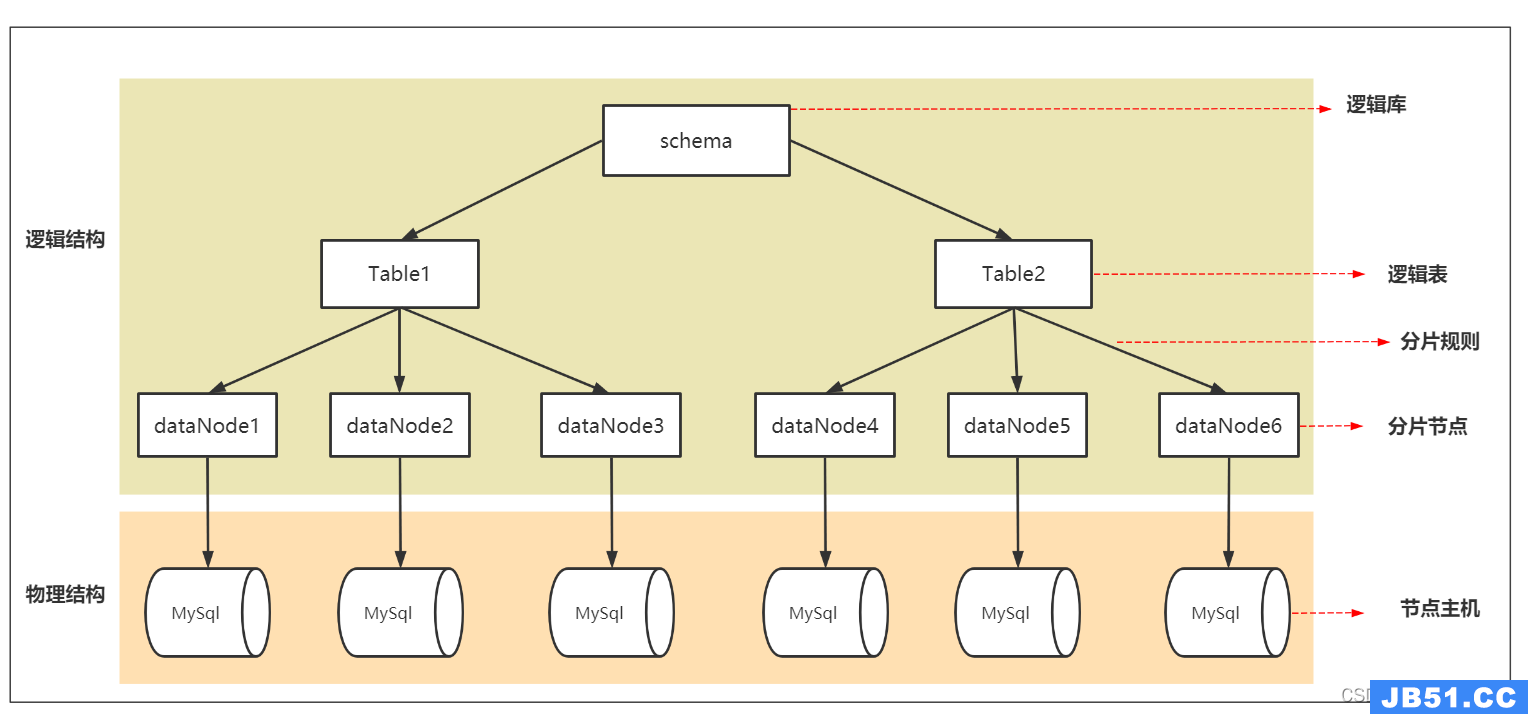
下面这张图是schema.xml配置文件中各个节点映射出的一个架构简图,对照这个图可以更好的理解该文件中各个配置参数的含义;
各个节点配置参数说明:
- Schema:逻辑库(mycat虚拟的库),与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table;
- Table:逻辑表,即对应的是物理数据库中存储的某一张表,与传统数据库不同,这里的表需要声明其所存储的逻辑数据节点DataNode,在此可以指定表的分片规则;
- DataNode:mycat 的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上 ;
- DataSource:定义某个具体的物理库的访问地址,用于捆绑到Datanode上;
分片规则:
前面讲几种分库分表的概念时,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难题,分片规则在conf目录下由rule.xml配置文件统一管理,而在schema.xml文件中只需要指定即可;
以上了解了schema.xml配置文件中核心配置参数的概念后,接下来在结合真实的业务需求进行配置的时候就有了明确的方向,看下面这个需求:
有一个tb_order表,由于数据量膨胀的比较厉害,现在需要对该表进行数据分片,将分成3个数据节点进行存储,每个节点上存储一定量的数据;
5、配置schema.xml和server.xml文件
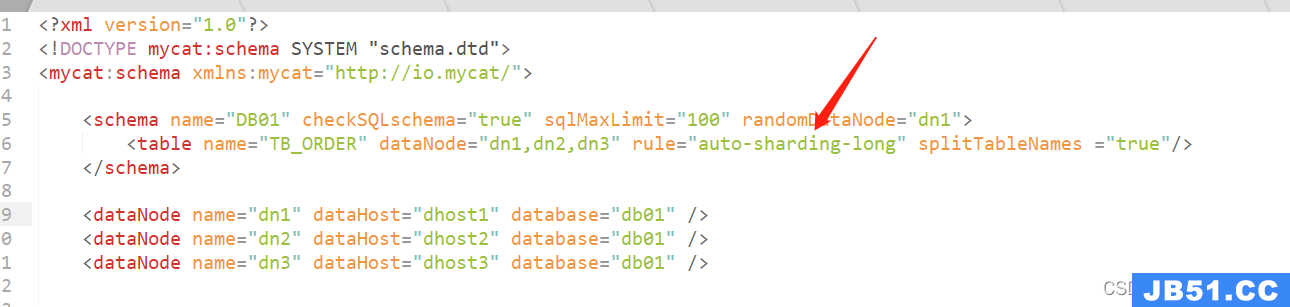
按照上面对schema.xml文件的配置参数的了解,schema.xml 文件最终得到下面的配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="101.34.33.77:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="101.34.33.77:3307" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="101.34.33.77:3308" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
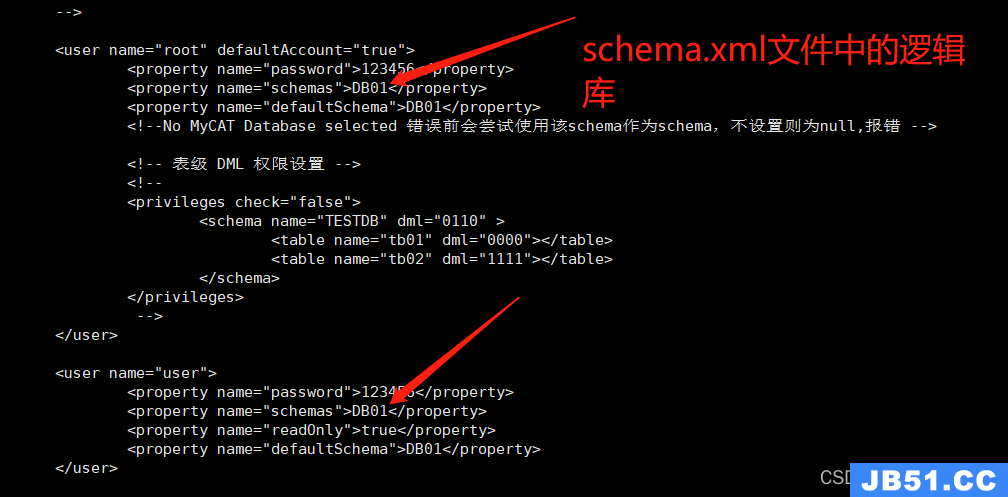
注意,这还没有完,就像我们访问mysql时需要账户和密码,使用了mycay之后,客户端不再直接连接mysql,而是连接mycat,所以还需要在server.xml配置文件中配置连接信息;
将该配置文件拉到最后,在下图的位置填写客户端连接信息,包括连接的账户和密码;
6、启动mycat
进入到bin目录下,使用下面的命令进行启动或停止
bin/mycat start(stop)
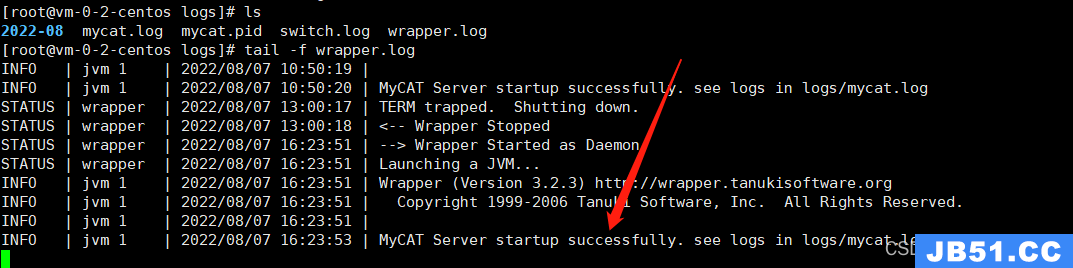
如何确认是否启动成功呢?可以在logs目录下检查下面的这个wrapper.log的l文件,出现下面的提示说明启动成功;
mycat 功能测试与验证
接下来测试下mycat配置是否生效,即是否能够按照预期的数据分片规则进行数据的分片;
1、使用navicat连接mycat
注意这里的端口号是:8066
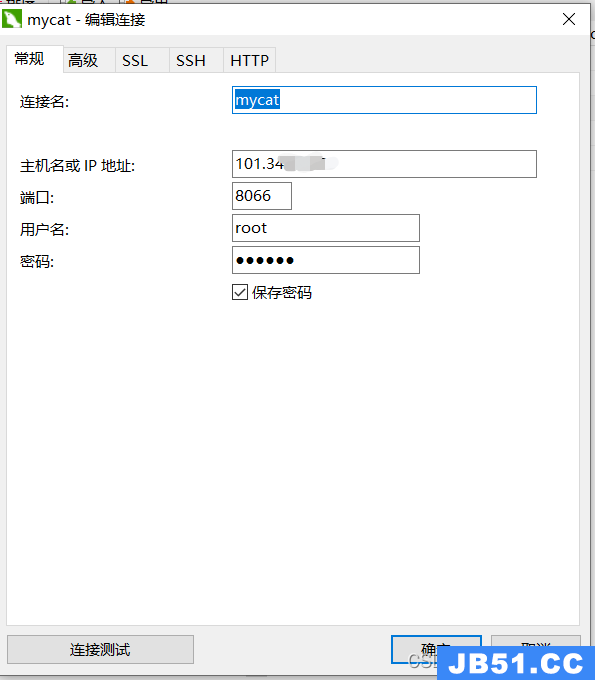
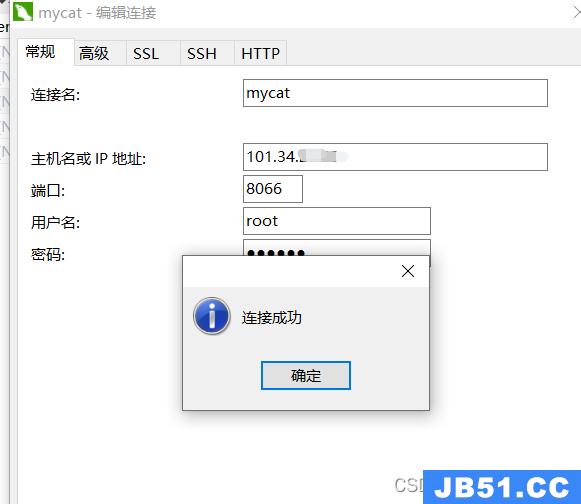
连接上了之后,就可以看到里面给我们创建了一个DB01的逻辑库
2、在DB01下,创建一个表
执行下面的sql进行创建
CREATE TABLE TB_ORDER (
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
)ENGINE=INNODB DEFAULT CHARSET=utf8 ;
创建成功之后,分别去3个数据库实例下,检查同样的表是否在3个db01的数据库下创建成功即可;
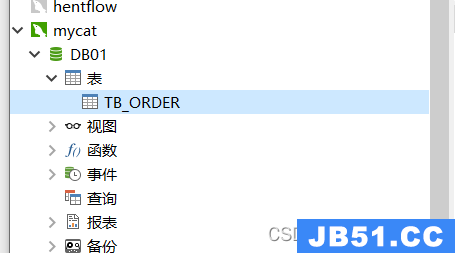
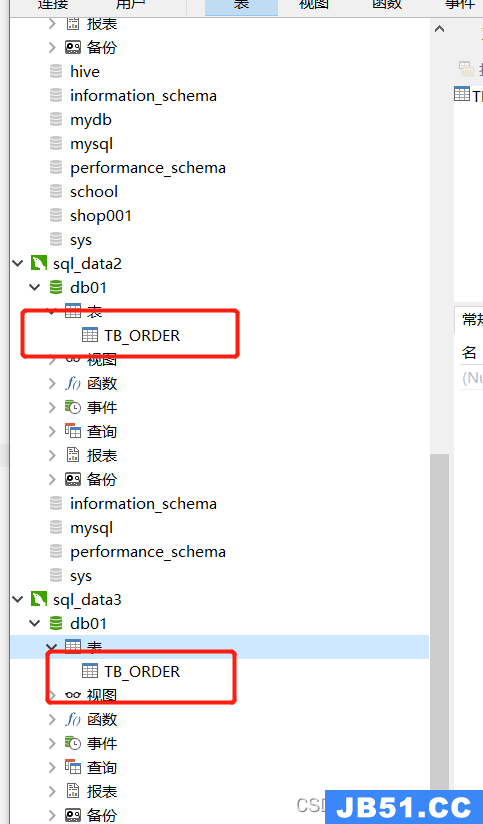
3、通过mycat的表,插入几条数据
INSERT INTO TB_ORDER(id,title) VALUES(1,'order01');
INSERT INTO TB_ORDER(id,title) VALUES(2,'order02');
INSERT INTO TB_ORDER(id,title) VALUES(3,'order03');
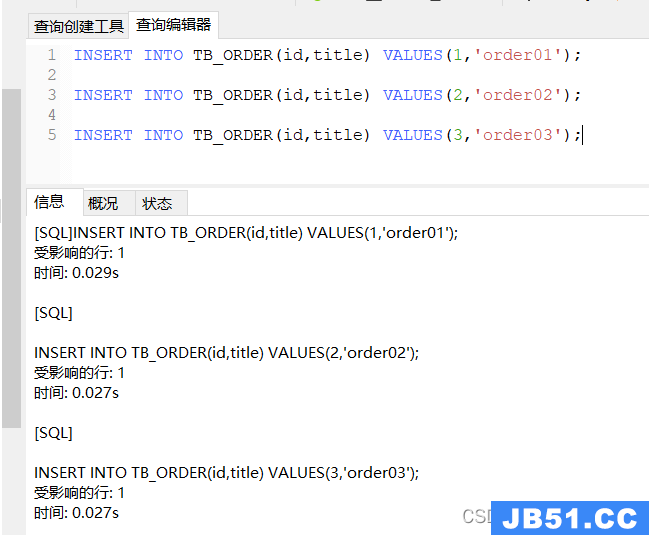
执行成功后,可以去3个库下检查下,最终发现在第一个mysql的实例下的表中插入了数据,另外2个表未保存数据
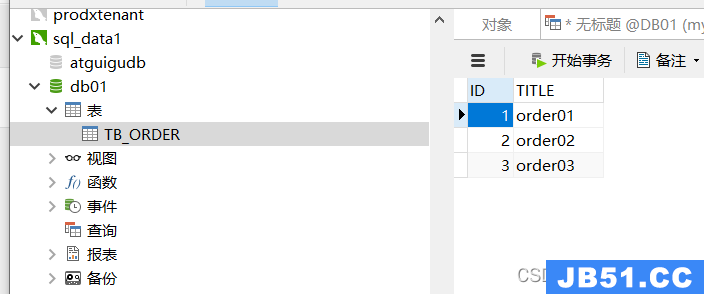
为什么会出现上面的现象呢?还记得在上面的schema.xml文件中的下面这一处的配置吗?这就是mycat提供的配置规则,那就需要深入到 rule.xml配置文件中去深入探究,即在当前这种配置规则下,每个表只是分担了一定数量的数据,至于分片规则,后续将会继续深入探究,敬请关注!
 linux常用进程通信方式包括管道(pipe)、有名管道(FIFO)、...
linux常用进程通信方式包括管道(pipe)、有名管道(FIFO)、... Linux性能观测工具按类别可分为系统级别和进程级别,系统级别...
Linux性能观测工具按类别可分为系统级别和进程级别,系统级别... 本文包含作者工作中常用到的一些命令,用于诊断网络、磁盘占满...
本文包含作者工作中常用到的一些命令,用于诊断网络、磁盘占满... linux的平均负载表示运行态和就绪态及不可中断状态(正在io)的...
linux的平均负载表示运行态和就绪态及不可中断状态(正在io)的... CPU上下文频繁切换会导致系统性能下降,切换分为进程切换、线...
CPU上下文频繁切换会导致系统性能下降,切换分为进程切换、线...