Node.js 抓取非 utf-8 的中文网页时会出现乱码问题,比如网易的首页编码是 gb2312,抓取时会出现乱码
request(url,function (err,res,body) { console.log(body) })
安装
同时我们顺带把 user-agent 修改一下,以防网站屏蔽:
function request (url,callback) { var options = { url: url, encoding: null, headers: headers } originRequest(options,callback) }
request(url,body) { var html = iconv.decode(body,'gb2312') console.log(html) })
乱码问题解决
使用 cheerio 解析 HTML
可以简单粗暴的理解为服务器端 jQuery 选择器,有了它,比正则要更加直观许多
安装
输出如下
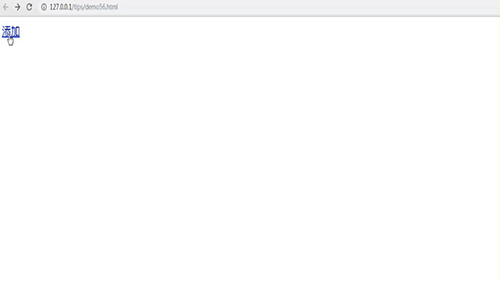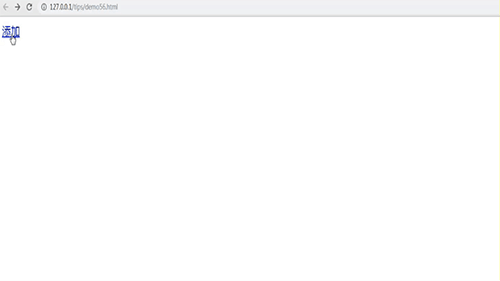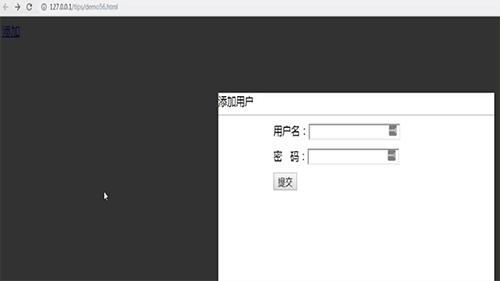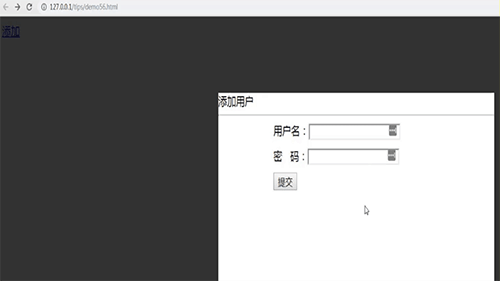 js如何实现弹出form提交表单?(图文+视频)
js如何实现弹出form提交表单?(图文+视频)
 js怎么获取复选框选中的值
js怎么获取复选框选中的值
 js如何实现倒计时跳转页面
js如何实现倒计时跳转页面
 如何用js控制图片放大缩小
如何用js控制图片放大缩小
那么问题来了,$('h1').html() 输出的代码是经过 Unicode 编码的,网易变成了网易,给我们的字符处理带来了一些麻烦
解决 cheerio .html() 「乱码」问题
查阅可知,可以关闭这个转换实体编码的功能相关文章
kindeditor4.x代码高亮功能默认使用的是prettify插件,prett...
这一篇我将介绍如何让kindeditor4.x整合SyntaxHighlighter代...
js如何实现弹出form提交表单?(图文+视频)js怎么获取复选框选中的值js如何实现倒计时跳转页面如何用js控制图片放大缩小