SELECT语句的组成:
| 子句 | 描述 | 备注 |
|---|---|---|
| SELECT | 显示指定列的内容 | 不可缺少,可以为列名指定别名,列名也可以是表达式 |
| FROM | 指明数据来源 | 不可缺少,可以为表名指定别名 |
| INTO | 将查询结果存储到新表中 | 可缺少,新表中各列的参数与原表相同,用于快速建表 |
| WHERE | 指定条件 | 若缺少此项,则表示全部记录 |
| ORDER BY | 将查询结果排序 | 可缺少,可以指定排列方式为升序(默认)和降序 |
| GROUP BY | 将查询结果分组显示 | 可缺少,分组依据通常是一个列名 |
| LIMIT | 用来限制结果数量 | 可缺少 |
SELECT语句的完整语法:
SELECT【ALL/DISTINCT】目标列表达式 [AS 别名],··· --ALL不去掉重复 DISTINCT去掉重复
FROM 表名或视图名 或者(SELECT语句)AS 表名(属性)
[WHERE] 条件表达式
[GROUP BY] 列名 【HAVING 条件表达式】
[ORDER BY] 列名 【ASC|DESC】 --ASC = ASCENDING(默认为递增递增)DESC = DESCENDING(递减)
[LIMIT子句]其中SELECT和FROM是必须的,其他关键字是可选的。
注意:这几个关键字的执行顺序与SQL语句的书写顺序并不是一致的。
执行顺序:
- FROM:需要从那个数据表检索数据
- WHERE:过滤表中数据的条件
- GROUP BY:如何见上面过滤出的数据分组
- HAVING:对上面已经分组的数据进行过滤的条件
- SELECT:挑选结果集中的哪个列 或 列的计算结果
- ORDER BY:按照什么样的顺序来查看返回的数据
去重选项
去重选项:是指是否对结果中完全相同的记录(所有字段数据都相同)进行去重:
- ALL:不去重 (默认)
- DISTINCT:去重
-
语法:
SELECT 去重选项 字段列表 FROM 表名;
CREATE TABLE student(name VARCHAR(15),gender VARCHAR(15));
INSERT INTO student(name,gender) VALUES("lihua","male");
INSERT INTO student(name,"male");
SELECT * FROM student;
SELECT DISTINCT * FROM student;注意:去重针对的是查询出来的记录,而不是存储在表中的记录。如果说仅仅查询的是某些字段,那么去重针对的是这些字段。
字段别名
字段别名:是指给列名另取一个名字。
- 字段别名只会在当次查询结果中生效。
- 字段别名一般都是简写字段名、辅助了解字段意义(比如我们定义的名字是name,我们希望返回给用户的结果显示成姓名)
-
语法:
SELECT 字段 AS 字段别名 FROM 表名;
CREATE TABLE student(name VARCHAR(15),"male");
SELECT * FROM student;
SELECT name AS "姓名",gender AS "性别" FROM student;数据源
事实上,查询的来源可以不是“表名”,只需是一个二维表即可。那么数据来源可以是一个SELECT结果。
数据源可以为单表数据源 或者 多表数据源
- 单表: SELECT 字段列表 FROM 表名;
-
多表: SELECT 字段列表 FROM 表名1,表名2,…;
注意:多表查询时是将每个表中的X条记录与另一个表Y条记录组成结果,组成的结果的记录条数为X*Y (笛卡尔积)
-
语法:
SELECT 字段列表 FROM (SELECT语句) AS 表别名;这是将一个查询结果作为一个查询的目标二维表,需要将查询结果定义成一个表别名才能作为数据源
SELECT name FROM (SELECT * FROM student) AS d;WHERE子句
WHERE子句:是用于筛选符合条件的结果的。
WHERE几种语法:
-
基于值:
-
=:WHERE 字段 = 值;
查找出对应字段等于对应值的记录。
(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于)例如:WHERE NAME = 'lihua'
-
LIKE:WHERE 字段 LIKE 值;
功能与 = 相似 ,但可以使用模糊匹配来查找结果。-
通配符
%用法:替代一个或多个字符 -
通配符
_用法:仅替代一个字符 -
通配符
[charlist]用法:字符列中的任何单一字符 -
通配符
[^charlist]用法:不在字符列中的任何单一字符例如:WHERE NAME LIKE 'li%'
-
通配符
-
IS:WHERE 字段 IS 值;
判断对应字段是否为空。(IS [NOT] NULL)
-
-
基于值的范围:
-
IN:WHERE 字段 IN 范围;查找出对应字段的值在所指定范围的记录。
例如:WHERE AGE IN (18,19,20)
-
NOT IN:WHERE 字段 IN 范围;
查找出对应字段的值不在所指定范围的记录。例如:WHERE AGE NOT IN (18,20)
-
BETWEEN X AND Y:WHERE 字段 BETWEEN X AND Y;
查找出对应字段的值在闭区间[X,Y]范围的记录。例如:WHERE AGE BETWEEN 18 and 20。
-
-
条件复合:
-
OR:WHERE 条件1 OR 条件2… ;
查找出符合条件1或符合条件2的记录。 -
AND:WHERE 条件1 AND 条件2… ;
查找出符合条件1并且符合条件2的记录。 -
NOT:WHERE NOT 条件1 ;
查找出不符合条件的所有记录。 -
&&的功能与AND相同;
||与OR功能类似;
!与NOT功能类似。
-
OR:WHERE 条件1 OR 条件2… ;
注意:WHERE是从磁盘中获取数据的时候就进行筛选的,所以某些在内存是才有的东西WHERE无法使用。(字段别名什么的是本来不是“磁盘中的数据”(是在内存这中运行时才定义的),所以WHERE无法使用,一般都依靠HAVING来筛选)
SELECT name AS n,gender FROM student WHERE name ="lihua";
-- SELECT name AS n,gender FROM student WHERE n ="lihua"; 报错
SELECT name AS n,gender FROM student HAVING n ="lihua";GROUP BY子句
GROUP BY子句:可以将查询结果依据字段来将结果分组。
-
语法:
SELECT 字段列表 FROM 表名 GROUP BY 字段...;注意:字段可以有多个,实际就是二次分组
SELECT name,gender,count(name) AS "组员" FROM student AS "学生" GROUP BY name;
SELECT name,count(name) AS "组员" FROM student AS "学生" GROUP BY name,gender;实际上,GROUP BY的作用主要是统计(使用情景很多,比如说统计某人的总分数,学生中女性的数量。。),所以一般会配合一些统计函数来使用:
- COUNT(X):统计每组的记录数,X是*时,代表记录数;为字段名时,代表统计字段数据数(除去NULL)
- MAX(X):统计最大值,X是字段名
- MIN(X):统计最小值,X是字段名
- AVG(X):统计平均值,X是字段名
- SUM(X):统计总和,X是字段名
注意:GROUP BY子句后面还可以跟上ASC或DESC,代表分组后是否根据字段排序。
HAVING子句:
HAVING子句:功能与WHERE类似,不过HAVING的条件判断发生在数据在内存中时,所以可以使用在内存中才发生的数据,如“分组”,“字段别名”等。(操作符之类的可以参考WHERE的,增加的只是一些“内存”中的筛选条件)
-
语法:
SELECT 字段列表 FROM 表名 HAVING 条件;【操作符之类的可以参考WHERE的,增加的只是一些“内存”中的筛选条件】
SELECT name AS n,gender FROM student HAVING n ="lihua";
SELECT name,COUNT(*) AS "组员" FROM student AS d GROUP BY name,gender HAVING COUNT(*) >2 ;--这里只显示记录数>2的分组ORDER BY子句:
ORDER BY子句:可以使查询结果按照某个字段来排序。
- ASC:代表排序是递增的(默认)
-
DESC:代表是递减的
注意:也可以指定某个字段的排序方法。
比如第一个字段递增,第二个递减。只需要在每个字段后面加ASC或DESC即可(虽然默认不加是递增,但还是加上更清晰明确)。
-
语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段 [ASC|DESC];注意:字段可以有多个,从左到右,后面的排序基于前面的,(比如:先按NAME排序,再按GENDER排序,后面的GENDER排序是针对前面NAME排序时NAME相同的数据)
SELECT * FROM student ORDER BY name;
SELECT * FROM student ORDER BY name,gender;
SELECT * FROM student ORDER BY name ASC,gender DESC;LIMIT子句
LIMIT子句:是用来限制结果数量的。
与WHERE\HAVING等配合使用时,可以限制匹配出的结果。
但凡是涉及数量的时候都可以使用LIMIT(这里只是强调LIMIT的作用,不要过度理解)
-
语法:
SELECT 字段列表 FROM 表名 LIMIT [OFFSET] COUNT; - OFFSET:是偏移量(常数),OFFSET默认从0开始,可以说是每条记录的索引号
- COUNT:是数量(常数)
SELECT * FROM student LIMIT 2;
SELECT * FROM student LIMIT 3,2;
SELECT * FROM student WHERE name ="lihua" limit 2; --取前2个记录行
SELECT * FROM student WHERE name ="lihua" limit 3,2; --从第3条开始,取2条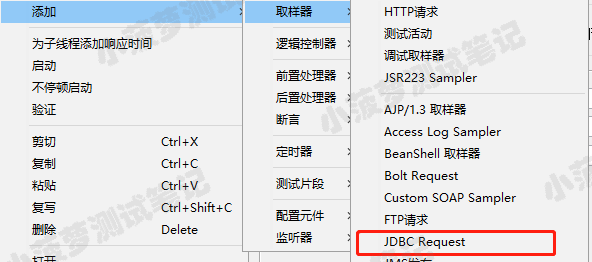 JDBCRequest 使用VariableNamesmysql:数据库连接池对象var...
JDBCRequest 使用VariableNamesmysql:数据库连接池对象var...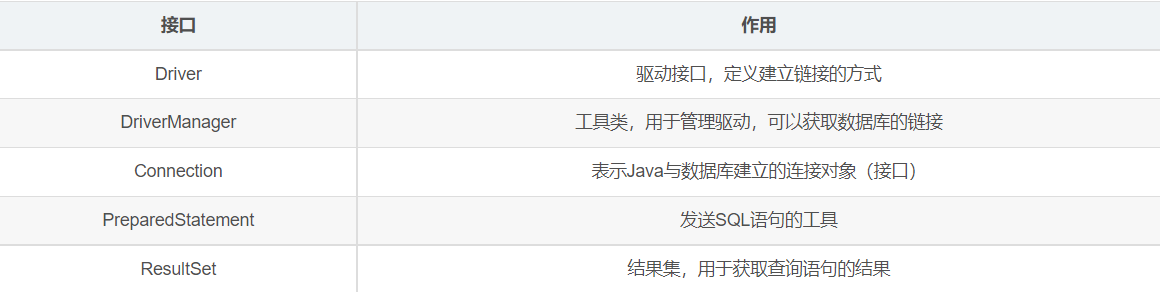 1.JDBCDBC(JavaDataBaseConnectivity):Java数据库连接技术...
1.JDBCDBC(JavaDataBaseConnectivity):Java数据库连接技术... 1.简介Activiti是一个业务流程管理(BPM)框架,它是覆盖了业务...
1.简介Activiti是一个业务流程管理(BPM)框架,它是覆盖了业务...