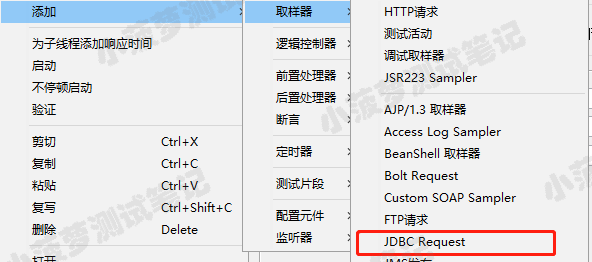
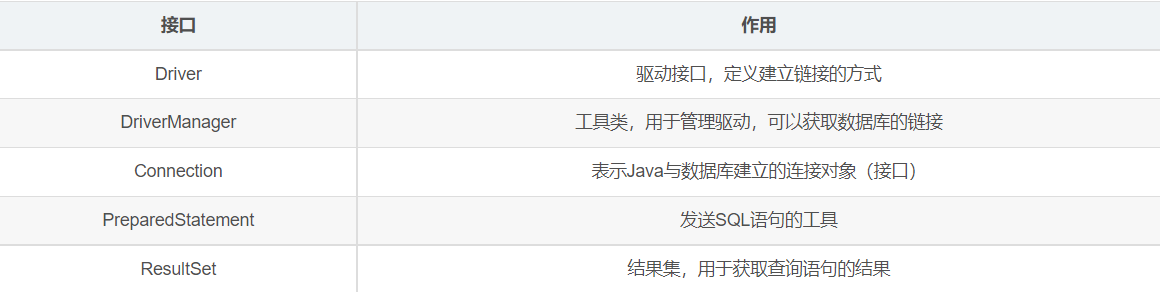
使用JDBC方式读取Kylin结果
一、准备依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>3.0.2</version>
</dependency>
</dependencies>
</project>
import java.sql.*;
public class KylinTest {
public static void main(String[] args) throws sqlException {
//获取连接
Connection connection = DriverManager.getConnection("jdbc:kylin://hadoop102:7070/gmall","ADMIN","KYLIN");
//准备sql
String sql = "select PROVINCE_NAME ,REGION_NAME,ACTIVITY_NAME,ACTIVITY_TYPE ,\n" +
" sum(ORIGINAL_TOTAL_AMOUNT) sum_org,max(BENEFIT_REDUCE_AMOUNT ) max_ben\n" +
"from DWD_FACT_ORDER_INFO t1\n" +
"left join \n" +
"DWD_DIM_BASE_PROVINCE t2 on t1.PROVINCE_ID = t2.ID \n" +
"left join\n" +
"DWD_DIM_ACTIVITY_INFO_VIEW t3 on t1.ACTIVITY_ID = t3.id\n" +
"group by PROVINCE_NAME ,REGION_NAME,ACTIVITY_NAME,ACTIVITY_TYPE ";
//预编译sql
PreparedStatement ps = connection.prepareStatement(sql);
//执行sql
ResultSet resultSet = ps.executeQuery();
//遍历结果(迭代器使用haveNext的方式读取数据)
while (resultSet.next()){
System.out.println(resultSet.getString("PROVINCE_NAME") + " " +
resultSet.getString("REGION_NAME") + " " +
resultSet.getString("ACTIVITY_NAME") + " " +
resultSet.getString("ACTIVITY_TYPE") + " " +
resultSet.getBigDecimal("sum_org") + " " +
resultSet.getBigDecimal("max_ben"));
}
//关闭资源
resultSet.close();
connection.close();
}
}