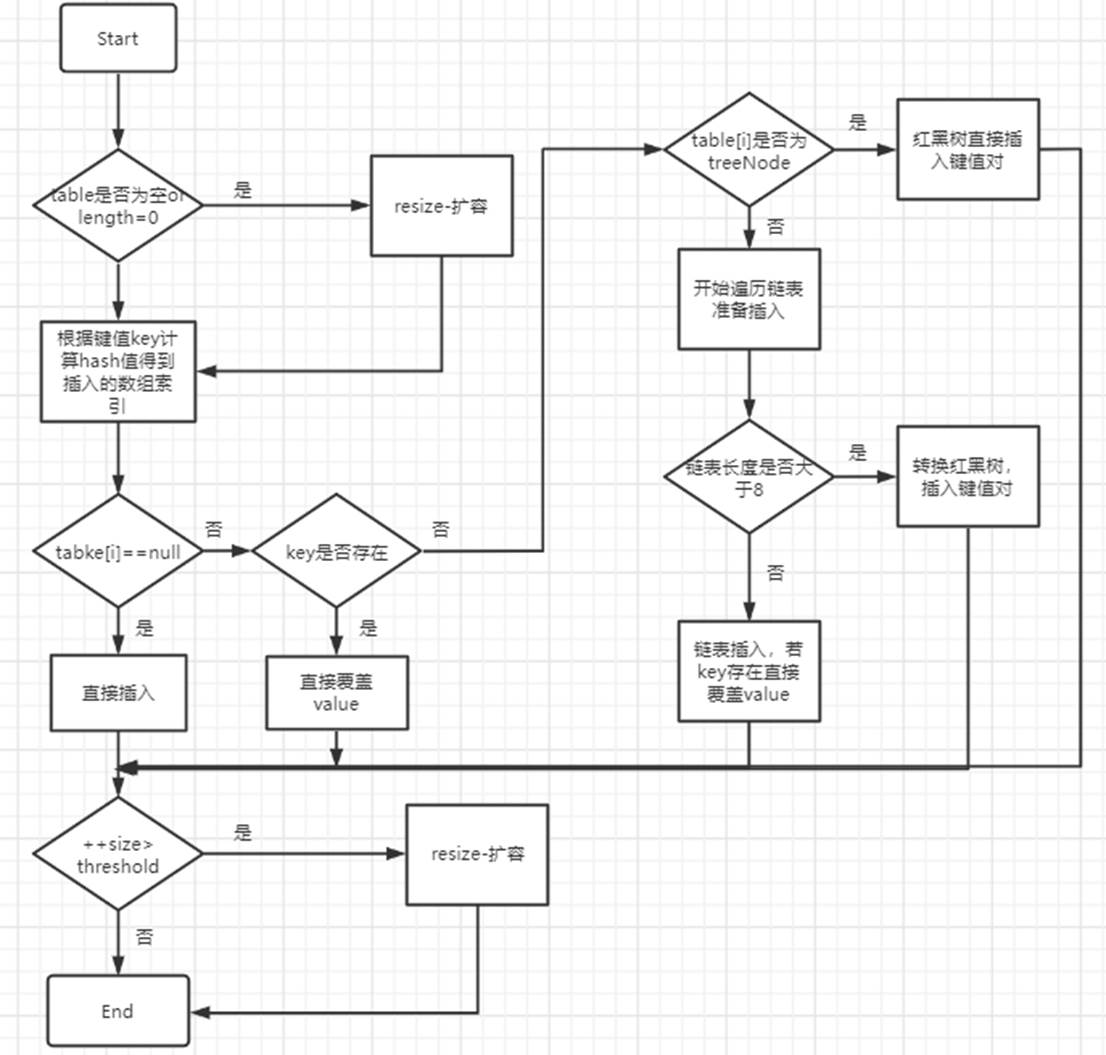
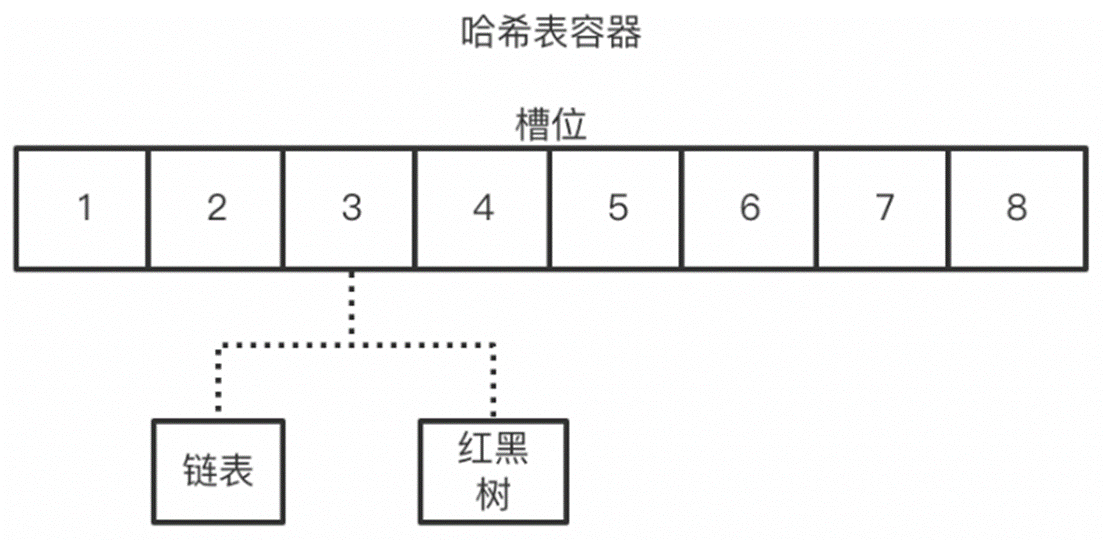
我有一个包含1000个元素的int数组.我需要提取数组中各种子群的大小(有多少是偶数,奇数,大于500等).
我可以使用for循环和一堆if语句来尝试为每个匹配项添加计数变量,例如:
for(int i = 0; i < someArray.length i++) {
if(conditionA) sizeA++;
if(conditionB) sizeB++;
if(conditionC) sizeC++;
...
}
或者我可以做一些更懒惰的事情,例如:
supplier<IntStream> ease = () -> Arrays.stream(someArray); int sizeA = ease.get().filter(conditionA).toArray.length; int sizeB = ease.get().filter(conditionB).toArray.length; int sizeC = ease.get().filter(conditionC).toArray.length; ...
以第二种方式实现这一目标的好处似乎仅限于可读性,但效率是否会受到巨大冲击?它可能更有效率吗?我猜它归结为迭代数组一次,4个条件总是好于每次迭代4次,每次一个条件(假设条件是独立的).我知道这个特殊的例子,第二种方法有很多额外的方法调用,我肯定不会提高效率.