原文地址:http://www.baeldung.com/java-read-lines-large-file
1. Overview
This tutorial will show how to read all the lines from a large file in Java in an efficient manner.
This article is part of Java – Back to Basic” tutorial here on Baeldung.
2. Reading In Memory
The standard way of reading the lines of the file is in-memory – both Guava and Apache Commons IO provide a quick way to do just that:
Highlighter_513935" class="
SyntaxHighlighter notranslate java">
nes(
The problem with this approach is that all the file lines are kept in memory – which will quickly lead to OutOfMemoryError if the File is large enough.
For example – reading a ~1Gb file:
Highlighter_975495" class="
SyntaxHighlighter notranslate java">
This starts off with a small amount of memory being consumed: (~0 Mb consumed)
IoUnitTest - Total Memory: 128 Mb
IoUnitTest - Free Memory: 116 Mb
However, after the full file has been processed,we have at the end: (~2 Gb consumed)
Highlighter_535011" class="
SyntaxHighlighter notranslate bash">
Which means that about 2.1 Gb of memory are consumed by the process – the reason is simple – the lines of the file are all being stored in memory now.
It should be obvious by this point that keeping in-memory the contents of the file will quickly exhaust the available memory – regardless of how much that actually is.
What’s more, we usually don’t need all of the lines in the file in memory at once – instead,we just need to be able to iterate through each one,do some processing and throw it away. So,this is exactly what we’re going to do – iterate through the lines without holding the in memory.
3. Streaming Through the File
Let’s now look at a solution – we’re going to use a java.util.Scanner to run through the contents of the file and retrieve lines serially,one by one:
This solution will iterate through all the lines in the file – allowing for processing of each line – without keeping references to them – and in conclusion, without keeping them in memory: (~150 Mb consumed)
Highlighter_313153" class="
SyntaxHighlighter notranslate bash">
4. Streaming with Apache Commons IO
The same can be achieved using the Commons IO library as well,by using the customLineIterator provided by the library:
terator it = FileUtils.lineI
terator(theFile,
terator.closeQuietly(it);
Since the entire file is not fully in memory – this will also result in pretty conservative memory consumption numbers: (~150 Mb consumed)
Highlighter_767697" class="
SyntaxHighlighter notranslate bash">
5. Conclusion
This quick article shows how to process lines in a large file without iteratively,without exhausting the available memory – which proves quite useful when working with these large files.
The implementation of all these examples and code snippets can be found in – this is an Eclipse based project,so it should be easy to import and run as it is.
相关文章
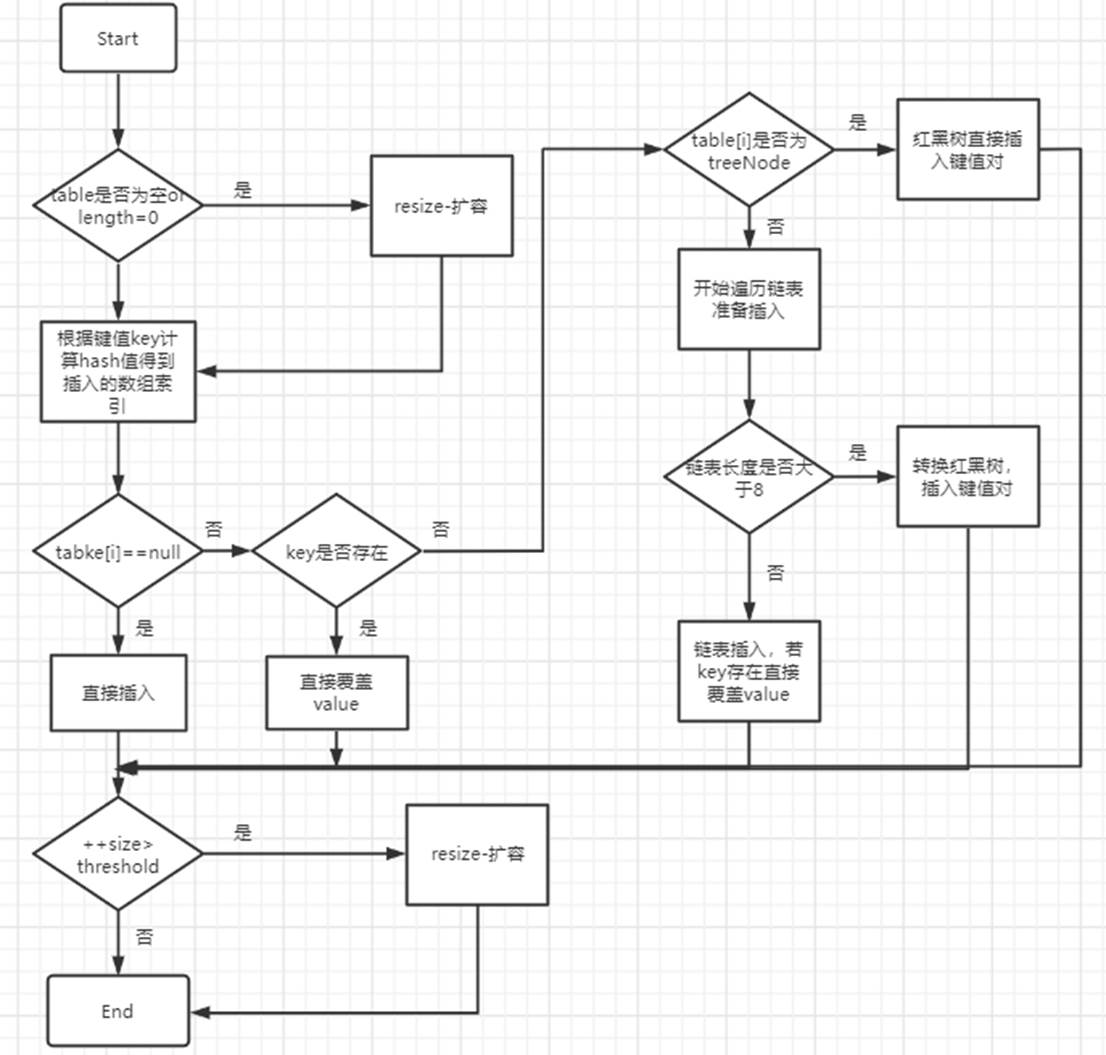
HashMap是Java中最常用的集合类框架,也是Java语言中非常典型...
在EffectiveJava中的第 36条中建议 用 EnumSet 替代位字段,...

介绍 注解是JDK1.5版本开始引入的一个特性,用于对代码进行说...
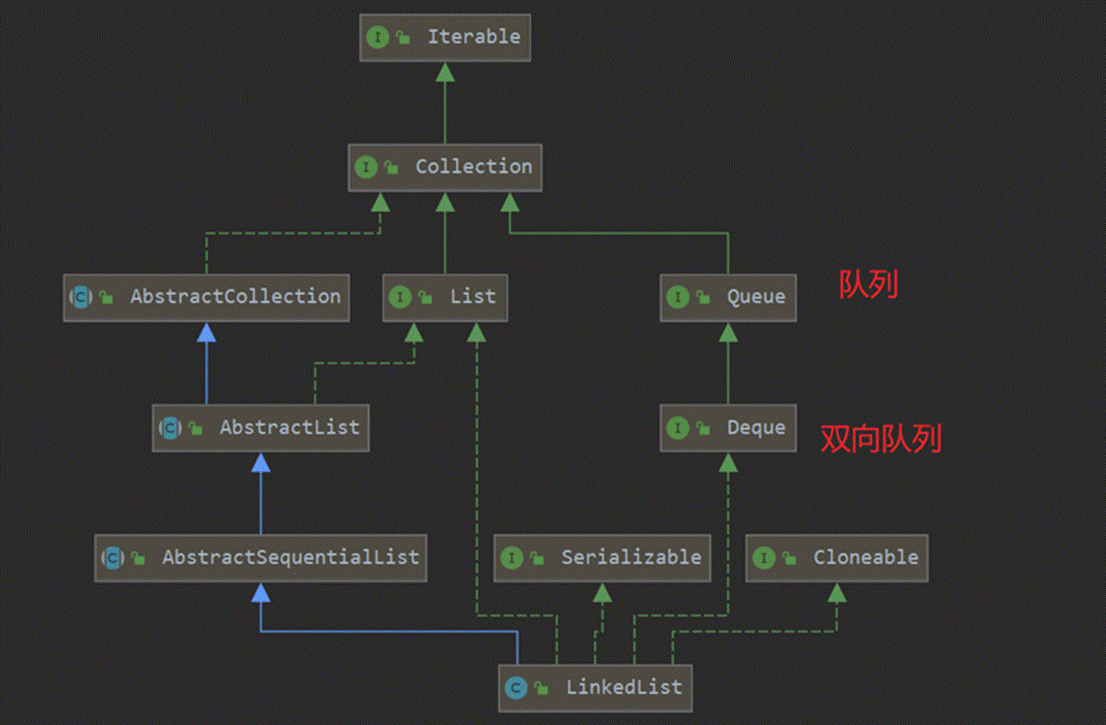
介绍 LinkedList同时实现了List接口和Deque接口,也就是说它...

介绍 TreeSet和TreeMap在Java里有着相同的实现,前者仅仅是对...
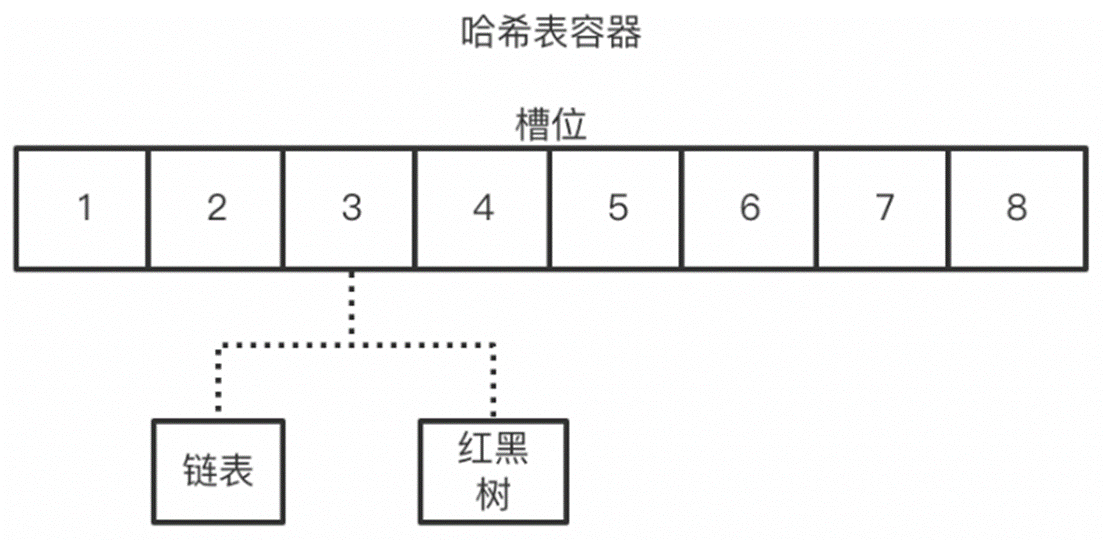
HashMap为什么线程不安全 put的不安全 由于多线程对HashMap进...