1. Hive简介
hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析数据。所以说,hive只用来处理结构化数据,且只提供了sql的方式来进行分析处理。而且一般来说,hive只能对数据进行批处理。(当使用hive 的hbase映射表时,有一定的实时能力;同时,flink社区也在尝试将hive实时化-这里的实时化指小时级别的实时化,达不到分钟级别)。
hive的默认引擎是MR,但是在实际开发过程中,MR的执行效率太低,不能满足开发需求,一般都需要对Hive的引擎进行更换。
常用的Hive引擎包括:MR(默认)、Tez、Spark
Tez是一个Hive的运行引擎,性能优于MR。
使用MR引擎:用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,MR之间不能相互使用数据,MR的运行结束后需要将中间结果持久化写到HDFS,其他的MR程序再将需要的依赖从HDFS中读取出来。因此使用MR引擎执行程序时需要多次磁盘io,所以效率不高。
使用Tez引擎:Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
2、Spark简介
spark是一个通用的处理大规模数据的分析引擎,即 spark 是一个计算引擎,而不是存储引擎,其本身并不负责数据存储。其分析处理数据的方式,可以使用sql,也可以使用java,scala,python甚至R等api;其分析处理数据的模式,既可以是批处理,也可以是流处理;而其分析处理的数据,可以通过插件的形式对接很多数据源,既可以是结构化的数据,也可以是半结构化甚至分结构化的数据,包括关系型数据库RDBMS,各种nosql数据库如hbase,mongodb,es等,也包括文件系统hdfs,对象存储oss,s3 等等
3、两者之间的关系
spark和hive本质上是没有关系的,两者可以互不依赖。但是在企业实际应用中,经常把二者结合起来使用。而业界spark和hive结合使用的方式,主要有以下种:
hive on spark。在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时(一般是提交给hiveserver2服务去执行),底层会经过hive的解析优化编译,最后以spark作业的形式来运行。事实上,hive早期只支持一种底层计算引擎,即mapreduce,后期在spark 因其快速高效占领大量市场后,hive社区才主动拥抱spark,通过改造自身代码,支持了spark作为其底层计算引擎。目前hive支持了三种底层计算引擎,即mr,tez和spark.用户可以通过set hive.execution.engine=mr/tez/spark来指定具体使用哪个底层计算引擎。
spark on hive。spark本身只负责数据计算处理,并不负责数据存储。其计算处理的数据源,可以以插件的形式支持很多种数据源,这其中自然也包括hive。当我们使用spark来处理分析存储在hive中的数据时,这种模式就称为为 spark on hive。这种模式下,用户可以使用spark的 java/scala/pyhon/r 等api,也可以使用spark语法规范的sql ,甚至也可以使用hive 语法规范的hql 。而之所以也能使用hql,是因为 spark 在推广面世之初,就主动拥抱了hive,通过改造自身代码提供了原生对hql包括hive udf的支持(其实从技术细节来将,这里把hql语句解析为抽象语法书ast,使用的是hive的语法解析器,但后续进一步的优化和代码生成,使用的都是spark sql 的catalyst),这也是市场推广策略的一种吧。
spark + spark hive catalog。这是spark和hive结合的一种新形势,随着数据湖相关技术的进一步发展,这种模式现在在市场上受到了越来越多用户的青睐。其本质是,数据以orc/parquet/delta lake等格式存储在分布式文件系统如hdfs或对象存储系统如s3中,然后通过使用spark计算引擎提供的scala/java/python等api或spark 语法规范的sql来进行处理。由于在处理分析时针对的对象是table,而table的底层对应的才是hdfs/s3上的文件/对象,所以我们需要维护这种table到文件/对象的映射关系,而spark自身就提供了 spark hive catalog来维护这种table到文件/对象的映射关系。
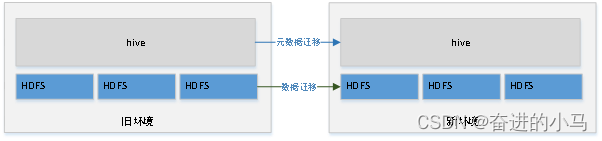 文章浏览阅读565次。hive和hbase数据迁移_hive转hbase
文章浏览阅读565次。hive和hbase数据迁移_hive转hbase 文章浏览阅读707次。基于单机版安装HBase,前置条件为Hadoop...
文章浏览阅读707次。基于单机版安装HBase,前置条件为Hadoop... 文章浏览阅读1k次,点赞16次,收藏21次。整理和梳理日常hbas...
文章浏览阅读1k次,点赞16次,收藏21次。整理和梳理日常hbas...