安全模式是Namenode的一种状态(Namenode主要有active/standby/safemode三种模式)。
2. 哪些情况下,Namenode会进入安全模式 ?
a. Namenode发现集群中的block丢失率达到一定比例时(默认0.01%),Namenode就会进入安全模式,在安全模式下,客户端不能对任何数据进行操作,只能查看元数据信息
b. 在hdfs集群正常冷启动时,Namenode也会在safemode状态下维持相当长的一段时间,此时你不需要去理会,等待它自动退出安全模式即可
3. 为什么,在HDFS集群冷启动时,Namenode会在安全模式下维持相当长的一段时间 ?
Namenode的内存元数据中,包含文件路径、副本数、blockid,及每一个block所在Datanode的信息,而fsimage中,不包含block所在的Datanode信息。那么,当Namenode冷启动时,此时内存中的元数据只能从fsimage中加载而来,从而就没有block所在的Datanode信息 ——> 就会导致Namenode认为所有的block都已经丢失 ——> 进入安全模式 ——> 所在的Datanode信息启动后,会定期向Namenode汇报自身所持有的block信息 ——> 随着Datanode陆续启动,从而陆续汇报block信息,Namenode就会将内存元数据中的block所在Datanode信息补全更新 ——> 找到了所有block的位置,从而自动退出安全模式
4. 如何退出安全模式 ?
1)找到问题所在,进行修复(比如修复宕机的所在Datanode信息补全更新)
2)可以手动强行退出安全模式:hdfs namenode --safemode leave 【不推荐,毕竟没有真正解决问题】
5. Namenode服务器的磁盘故障导致namenode宕机,如何挽救集群及数据 ?
1)HA机制:高可用hadoop2.0
2)配置hdfs-site.xml指定然后重启Namenode运行时数据存放多个磁盘位置
3)然后重启Namenode和SecondaryNamenode的工作目录存储结构完全相同,当然后重启Namenode故障退出需要重新恢复时,可以从SecondaryNamenode的工作目录存储结构完全相同,当的工作目录中的namesecondary文件夹及其中文件拷贝到然后重启Namenode所在节点工作目录中(但只能恢复大部分数据SecondaryNamenode最后一次合并之后的更新操作的元数据将会丢失),将namesecondary重命名为name然后重启Namenode
6. Namenode是否可以有多个?Namenode跟集群数据存储能力有关系吗?
1)非HA的模式下Namenode只能有一个,HA模式下可以有两个(一主active一备standby),HDFS联邦机制可以有多个Namenode
2)关系不大,存储数据由Datanode完成。但是药尽量避免存储大量小文件,因为会耗费Namenode内存
7. fsimage是否存放了block所在服务器信息 ?
1)在edits中保存着每个文件的操作详细信息
2)在fsimage中保存着文件的名字、id、分块、大小等信息,但是不保存Datanode 的IP
3)在hdfs启动时处于安全模式,Datanode 向Namenode汇报自己的IP和持有的block信息
安全模式结束,文件块和Datanode 的IP关联上
|
验证过程: 1) 启动Namenode,离开safemode,cat某个文件,看log,没有显示文件关联的Datanode 2) 启动Datanode,cat文件,内容显示 3) 停止Datanode ,cat文件,看log,看不到文件,但显示了文件块关联的Datanode |
8. Datanode动态上下线?
在实际生产环境中,在hdfs-site.xml文件中还会配置如下两个参数:
dfs.hosts:白名单;dfs.hosts.exclude:黑名单
|
<property> <name>dfs.hosts</name> #完整的文件路径:列出了允许连入NameNode的datanode清单(IP或者机器名) <value>$HADOOP_HOME/conf/hdfs_include</value> </property> <property> <name>dfs.hosts.exclude</name> #文件完整路径:列出了禁止连入NameNode的datanode清单(IP或者机器名) <value>$HADOOP_HOME/conf/hdfs_exclude</value> </property> |
1) 上线datanode
a) 保证上线的datanode的ip配置在白名单并且不出现在黑名单中
b) 配置成功上线的datanode后,通过命令hadoop-daemon.sh datanode start启动
c) 刷新节点状态:/bin/hadoop dfsadmin -refreshNodes(这个命令可以动态刷新dfs.hosts和dfs.hosts.exclude配置,无需重启NameNode)
d) 手动进行数据均衡:start-balance.sh
2) 下线datanode
a) 保证下线的datanode的ip配置在黑名单并且不出现在白名单中
b) 关闭下线的节点
c) 刷新节点状态:/bin/hadoop dfsadmin -refreshNodes
d) 机器下线完毕后,将它们从hdfs_exclude文件中移除
9. 关于Datanode的几个问题 ?
1)Datanode在什么情况下不会备份?
在强制关闭或者非正常断电时不会备份
2)3个Datanode中有一个Datanode出现错误会怎样?
这个Datanode的数据会在其他的Datanode上重新做备份
10. HDFS HA机制下的脑裂现象以及避免方法 ?
当standby Namenode的ZKFailoverController收到active Namenode端故障通知时,不会立即将自己的状态切换为active,因为此时active Namenode可能处于“假死”状态,如果即刻切换为active状态,有可能造成脑裂现象。
为了防止脑裂,建议写个脚本确保发出故障通知的active Namenode一定被kill掉,具体可以按照以下几个步骤完成kill操作:
1.执行杀掉active Namenode的shell脚本,等待ssh kill返回命令
2.如果响应成功,就把原standby Namenode的状态切换为active;如果响应失败或者超时(可以配置一个超时时间)
3.只要shell脚本的调用返回值为true,则切换自己端的Namenode状态为active
笔者强调:Namenode主备切换、健康状态监控等需要通过ZKFailoverController等组件实现,但最终会借助于zookeeper集群
11. HDFS为什么不适合存储小文件 ?
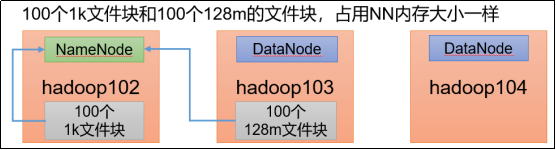
一般一个block对应的元数据大小为150byte左右,大量小文件会使内存中的元数据变大导致占用大量Namenode内存、寻址时间长
12. 大量小文件的处理方式?
1)打成HAR files
命令:hadoop archive -archiveName xxx.har -p /src /dest
查看内容:hadoop fs -lsr har:///dest/xxx.har
该命令底层实际上是运行了一个MapReduce任务来将小文件打包成HAR。但是通过HAR来读取一个文件并不会比直接从HDFS中读取文件高效,因为对每一个HAR文件的访问都需要进行index文件和文件本身数据的读取。并且虽然HAR文件可以被用来作为MapReduce任务的input,但是并不能将HAR文件中打包的文件当作一个HDFS文件处理
2)编写MR程序,将小文件序列化到一个Sequence File中
将小文件以文件名作为key,以文件内容作为value,编写一个程序将它们序列化到HDFS上的一个Sequence File中,然后来处理这个Sequence File。相对打成HAR文件,具有两个优势:
(1)Sequence File是可拆分的,因此MapReduce可以将它们分成块并独立地对每个块进行操作
(2)它们同时支持压缩,不像HAR。在大多数情况下,块压缩是最好的选择,因为它将压缩几个记录为一个块,而不是一个记录压缩一个块
笔者强调hdfs小文件问题要结合具体的处理引擎以及业务情况等,比如离线处理下、流式处理下小文件问题如何解决,之后笔者会开单篇详述
13. 查看HDFS集群工作状态命令 ?
hdfs dfsadmin -report:快速定位各个节点情况,如每个节点的硬盘使用情况
关注微信公众号:大数据学习与分享,获取更对技术干货
 目录一、背景1)小文件是如何产生的?2)文件块大小设置3)H...
目录一、背景1)小文件是如何产生的?2)文件块大小设置3)H...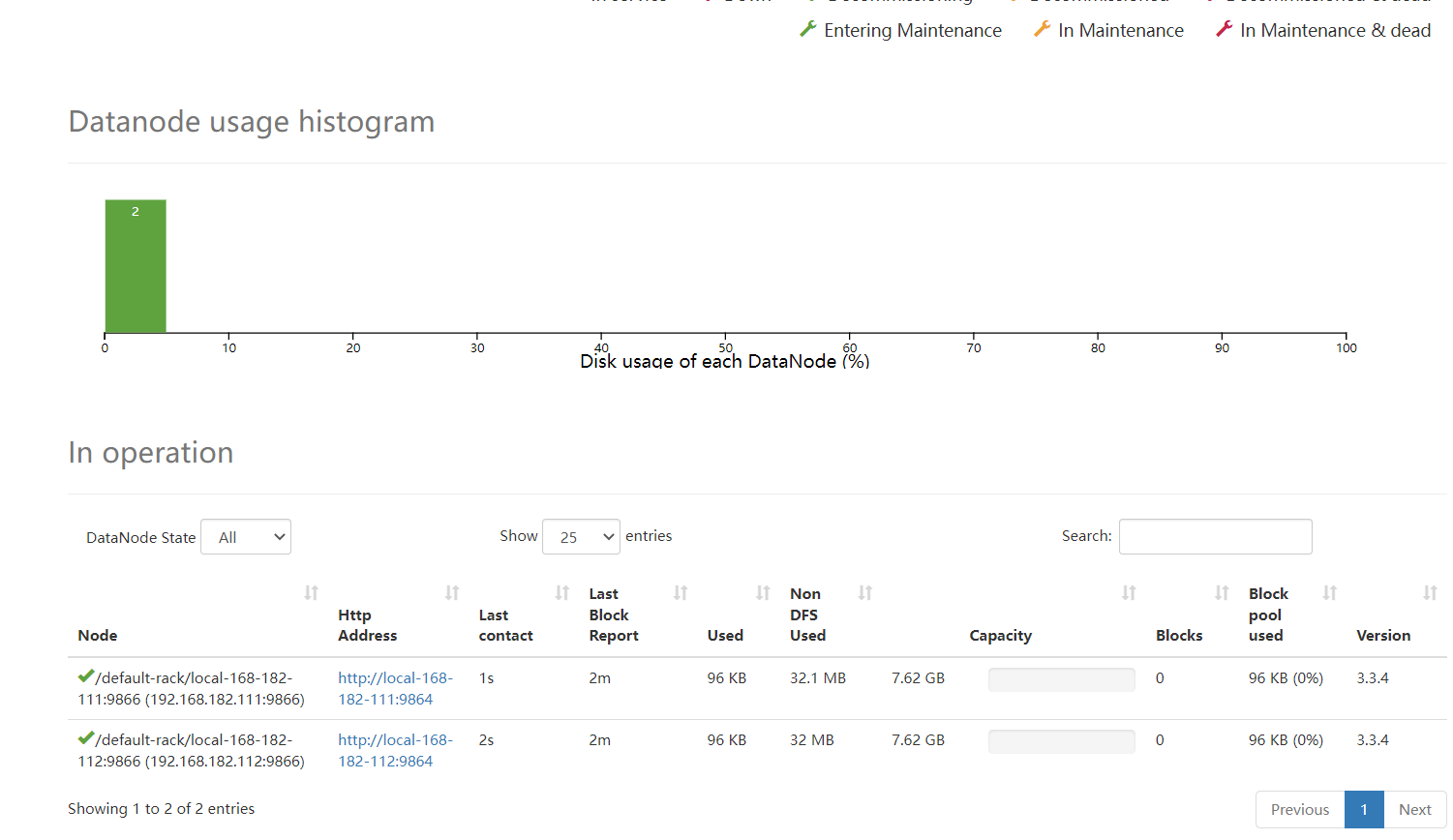 目录一、概述二、HadoopDataNode多目录磁盘配置1)配置hdfs-...
目录一、概述二、HadoopDataNode多目录磁盘配置1)配置hdfs-... 平台搭建(伪分布式)伪分布式搭建在VM中搭建std-master修改...
平台搭建(伪分布式)伪分布式搭建在VM中搭建std-master修改...