格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据,所以,格式化NameNode前,先关闭掉NameNode和DataNode,然后一定要删除data数据和log日志。最后再进行格式化。
在hadoop-2.9.2/data/tmp/dfs/name/current/VERSION中可查到NameNode标识id

在hadoop-2.9.2/data/tmp/dfs/data/current/VERSION中可查到DataNode标识id
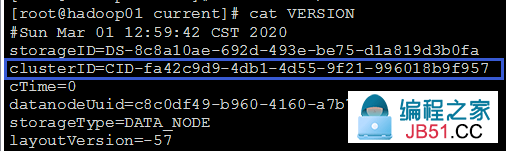
可以看出它们的集群Id是要保持一致的。
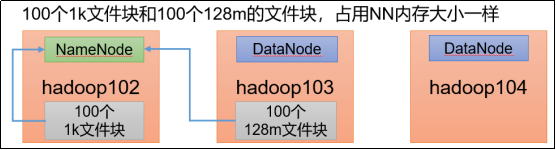 目录一、背景1)小文件是如何产生的?2)文件块大小设置3)H...
目录一、背景1)小文件是如何产生的?2)文件块大小设置3)H...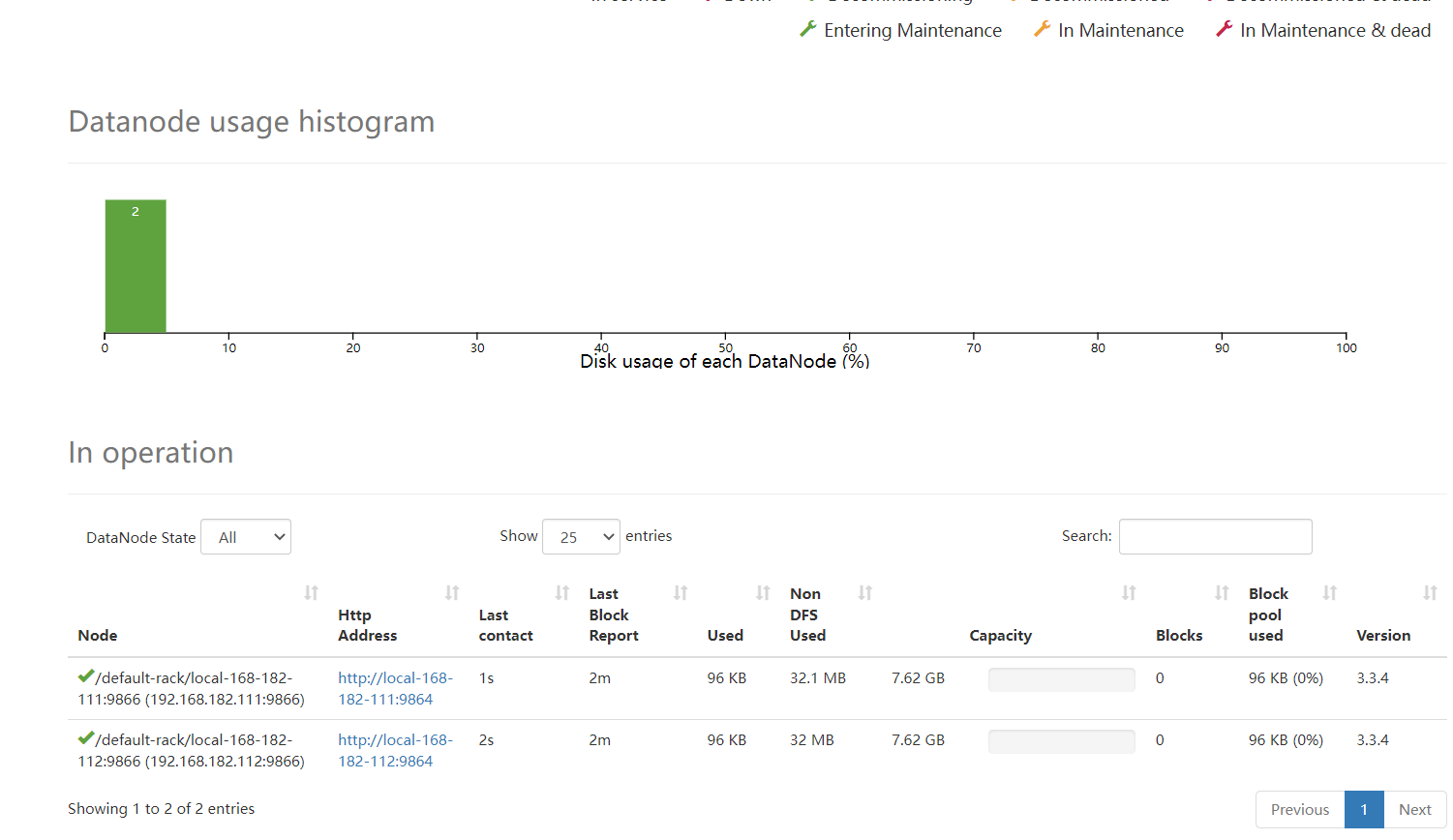 目录一、概述二、HadoopDataNode多目录磁盘配置1)配置hdfs-...
目录一、概述二、HadoopDataNode多目录磁盘配置1)配置hdfs-... 平台搭建(伪分布式)伪分布式搭建在VM中搭建std-master修改...
平台搭建(伪分布式)伪分布式搭建在VM中搭建std-master修改...