1.hadoop中的InputSplit是什么?
如果分配一个Mapper给块1,在这种情况下,Mapper不能处理第二条记录,因为块1中没有完整第二条记录。因为HDFS不知道文件块中的内容,它不知道记录会什么时候可能溢出到另一个块(because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record might spill over into another block)。InputSplit这是解决这种跨越块边界的那些记录问题,Hadoop使用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。
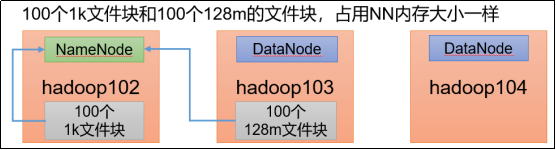
2.1个129m的数据,占用几个block,几个inputSplit?
2个block,1个inputSplit
3.列举出hadoop中定义的最常用的InputFormats。默认的是哪个
TextInputFormat
作为默认的文件输入格式,用于读取纯文本文件,文件被分为一系列以LF或者CR结束的行,key是每一行的位置偏移量,是LongWritable类型的,value是每一行的内容,为Text类型。
NLineInputFormat
可以将文件以行为单位进行split,比如文件的每一行对应一个map。得到的key是每一行的位置偏移量(LongWritable类型),value是每一行的内容,Text类型
CombineTextInputFormat
CombineTextInputFormat的作用是把许多文件合并作为一个 map 的输入 .
keyvalueTextInputFormat
同样用于读取文件,如果行被分隔符(缺省是tab)分割为两部分,第一部分为key,剩下的部分为value;如果没有分隔符,整行作为 key,value为空。
SequenceFileInputFormat
用于读取sequence file。 sequence file是Hadoop用于存储数据自定义格式的binary文件。它有两个子类:SequenceFileAsBinaryInputFormat,将 key和value以BytesWritable的类型读出;SequenceFileAsTextInputFormat,将key和value以Text类型读出。
SequenceFileInputFilter
根据filter从sequence文件中取得部分满足条件的数据,通过 setFilterClass指定Filter,内置了三种 Filter,RegexFilter取key值满足指定的正则表达式的记录;PercentFilter通过指定参数f,取记录行数%f0的记录;MD5Filter通过指定参数f,取MD5(key)%f0的记录。
4.自定义序列化类的开发步骤
1)实现Writable接口
2)重写write和readFields方法,注意字段顺序一定要一样
3)必须要带有一个默认无参的构造方法
4)toString(可选)
5)如果你的自定义类要是实现排序,那么需要实现Comparable
5.mapreduce在提交任务时是如何划分切片的?以及这样做的好处?
按照hdfs上的blcok来划分;当一个文件占据了多个block块,并且这个文件的总大小 < blocksize * 1.1 时,会进入一个分片。这样会大大减少maptask的数量,节省资源。
6.什么是序列化?什么是反序列化?在mapreduce的开发过程中如何实现序列化?为什么hadoop要弄一套自己的序列化机制?
1.序列化是指把结构化对象转化为字节流。
2.反序列化是序列化的逆过程。把字节流转为结构化对象。
3.自定义的类实现Writable接口即可。
4.虽然序列化使得对象转变为二进制,可以大大节约空间,但是Java 的序列化是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息,不便于高效传输;所以,hadoop 自己开发了一套序列化机制,精简,高效,需要哪个属性就传输哪个属性值,大大的减少网络传输的开销。
7.自定义mr FileOutputFormat类的思路。
1.自定义文件输出类要继承FileOutputFormat类,通过getRecordWriter方法的TaskAttemptContext job参数获取配置类
2.通过FileSystem.get(configuration)获取文件系统对象
3.自定义RecordWriter类。
4.通过fs.create(文件路径)获取输出流对象
5.在write方法中 写输出业务逻辑
6.close中关闭流
8.mr的Join操作的思路
自定义一个writable,包含要输出的字段和flag区分字段
map中根据文件名判断当前行数据所属的数据,并设置对应的flag值
在reduce中根据根据关联字段进行join处理
9.mr的Combine操作需要注意什么?
不能影响业务 类似reduce在map端做一个聚合,减少reduce的输入
10.如何获取一个线程安全的ArrayList()
Collections.synchronizedList()
11.ArrayList中的快速移除方法的原理。
System.arraycopy(elementData, index+1, elementData, index,numMoved);
后面的元素是通过拷贝来实现的
12.mr中有那些方法可以向外输出数据,区别什么?会输出到reduce吗
map方法和cleanup方法都可以输出数据
区别是map方法是每个分片的内容进行操作,通常要执行多次。cleanup只执行一次。适合做一些一次性工作,如果没有定义reduce会直接输出。
13.ArrayList的最大长度。
Integer.MAX_VALU
14.ArrayList底层是什么类型的数组?
object
15.MR分区默认逻辑是(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,前面为什么要&?
因为key.hashCode()太大,可能会溢出变成负数,和整数的上限值Integer.MAX_VALUE进行与运算,然后再对reduce任务个数取余,这样就可以让key均匀分布在reduce上。
16.new ArrayList() 的size
通过无参构造器创建的ArrayList对象的size是0
17.ArrayList的默认容量,和扩容策略。
ArrayList的默认容量是10
扩容策略:当元素大于已有容量长度时,会根据扩充为当前容量的1.5倍
18.ArrayList的优缺点。
优点:适合做查询操作。
缺点:不适合做中间/首位插入和中间/首位删除。
注:尾部插入和删除与LinkedArrayList从效率上相差无几