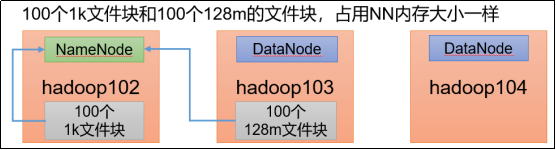
我们来实现一下复杂的案例
求出两两之间的好友:
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
/*
第一阶段的map函数主要完成以下任务
1.遍历原始文件中每行<所有朋友>信息
2.遍历“朋友”集合,以每个“朋友”为键,原来的“人”为值 即输出<朋友,人>
*/
/*
第一阶段的reduce函数主要完成以下任务
1.对所有传过来的<朋友,list(人)>进行拼接,输出<朋友,拥有这名朋友的所有人>
*/
/*
第二阶段的map函数主要完成以下任务
1.将上一阶段reduce输出的<朋友,拥有这名朋友的所有人>信息中的 “拥有这名朋友的所有人”进行排序 ,以防出现B-C C-B这样的重复
2.将 “拥有这名朋友的所有人”进行两两配对,并将配对后的字符串当做键,“朋友”当做值输出,即输出<人-人,共同朋友>
*/
/*
第二阶段的reduce函数主要完成以下任务
1.<人-人,list(共同朋友)> 中的“共同好友”进行拼接 最后输出<人-人,两人的所有共同好友>
*/
第一阶段的程序
Mapper端
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FriendMapper1 extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] people_friend = value.toString().split(":");
String people = people_friend[0];
String[] friends = people_friend[1].split(",");
for (String friend:friends){
context.write(new Text(friend),new Text(people));
}
}
}
Reduce端
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FriendReducer1 extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String sum = new String();
for (Text value:values){
sum += value.toString() + ",";
}
String s = sum.substring(0,sum.length()-1);
context.write(key,new Text(s));
}
}
Driver端
package hadoop.MapReduce.friend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendDriver1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FriendDriver1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setoutputKeyClass(Text.class);
job.setoutputValueClass(Text.class);
job.setMapperClass(FriendMapper1.class);
job.setReducerClass(FriendReducer1.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\friend.txt"));
FileOutputFormat.setoutputPath(job,new Path("D:\\a\\b6"));
job.waitForCompletion(true);
}
}
第二阶段的程序
Mapper端
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
public class FriendMapper2 extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] people_friend = value.toString().split("\t");
String people = people_friend[0];
String[] friends = people_friend[1].split(",");
Arrays.sort(friends);
for (int i = 0;i < friends.length-1;i++) {
for (int j = i + 1; j < friends.length; j++) {
context.write(new Text(friends[i]+"-"+friends[j]+":"), new Text(people));
}
}
}
}
Reduce端
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class FriendReducer2 extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String sum = new String();
Set<String> set = new HashSet<String>();
for (Text value:values){
if (!set.contains(value.toString()))
set.add(value.toString());
}
for (String value:set){
sum += value.toString()+",";
}
String s = sum.substring(0,sum.length()-1);
context.write(key,new Text(s));
}
}
Driver
package hadoop.MapReduce.friend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendDriver2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FriendDriver2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setoutputKeyClass(Text.class);
job.setoutputValueClass(Text.class);
job.setMapperClass(FriendMapper2.class);
job.setReducerClass(FriendReducer2.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\b6\\part-r-00000"));
FileOutputFormat.setoutputPath(job,new Path("D:\\a\\b7"));
job.waitForCompletion(true);
}
}
实现效果
第一阶段

第二阶段