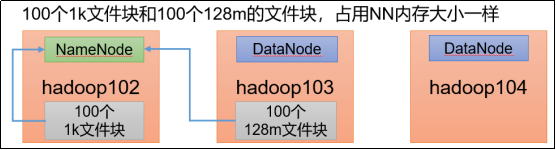
NN1 NN2 DN ZK ZKFC JNN
NODE01 * * *
NODE02 * * * * *
NODE03 * * *
NODE04 * *
1、首先让两个NameNode能互相免密钥,在前一部分中node01已经能免密登陆node02了,所以再让node02免密登陆自己和node01就行
[root@node02 .ssh]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa [root@node02 .ssh]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys [root@node02 .ssh]# scp id_dsa.pub node01:`pwd`/node02.pub [root@node01 .ssh]# cat ~/.ssh/node02.pub >> ~/.ssh/authorized_keys
[root@node01 hadoop]# vi hdfs-site.xml 删除 <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> 添加 <property> <name>dfs.nameservices</name> //主节点服务名称 <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> //namenode ID <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> //namenode地址 <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> //namenode的http服务地址 <value>node01:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node02:50070</value> </property>
<property>
<name>dfs.namenode.shared.edits.dir</name> //JournalNode地址
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> //JournalNode的edits保存路径
<value>/var/ycyz/hadoop/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> //故障转移的代理模式
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> //故障namenode状态隔离
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> //私钥路径
<value>/root/.ssh/id_dsa</value>
</property>
3、修改core-site.xml
[root@node01 hadoop]# vi core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>
4、配置zookeeper,在Hadoop配置文件中设置自动故障转移,并配置zookeeper集群地址
[root@node01 hadoop]# vi hdfs-site.xml
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value>
</property>
[root@node01 hadoop]# vi core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
5、将hdfs-site.xml和core-site.xml分发给其他所有Hadoop节点
[root@node01 hadoop]# scp hdfs-site.xml core-site.xml node02:`pwd`
6、安装zookeeper3.4.6,压缩包解压在其他路径下
[root@node02 software]# tar xf zookeeper-3.4.6.tar.gz -C /opt/ycyz/
7、进入zookeeper的conf目录,拷贝zoo_sample.cfg为zoo.cfg 并配置dataDir,集群节点
[root@node02 conf]# cp zoo_sample.cfg zoo.cfg
[root@node02 conf]# vi zoo.cfg
dataDir=/var/ycyz/zookeeper
server.1=node02:2888:3888 //集群节点对应的id
server.2=node03:2888:3888
server.3=node04:2888:3888
8、将zookeeper安装文件分发到其他zookeeper节点
[root@node02 ycyz]# scp -r zookeeper-3.4.6/ node03:`pwd`
9、每个zookeeper节点都创建dataDir的目录
[root@node02 ycyz]# mkdir -p /var/ycyz/zookeeper
10、告知每个zookeeper节点自己对应的id
[root@node02 ycyz]# echo 1 > /var/ycyz/zookeeper/myid [root@node03 ~]# echo 2 > /var/ycyz/zookeeper/myid [root@node04 ~]# echo 3 > /var/ycyz/zookeeper/myid
11、配置zookeeper环境变量,并分发到其他节点
[root@node02 zookeeper-3.4.6]# vi /etc/profile
export ZOOKEEPER_HOME=/opt/ycyz/zookeeper-3.4.6
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
[root@node02 zookeeper-3.4.6]# scp /etc/profile node03:/etc/
[root@node02 zookeeper-3.4.6]# source /etc/profile
12、启动zookeeper集群
与Hadoop集群只需在一个节点上执行启动命令不同
必须手动在所有zookeeper节点上执行 zkServer.sh start
查看节点状态 zkServer.sh status
13、启动所有JournalNode
hadoop-daemon.sh start journalnode
14、格式化namenode,如果两个namenode均未格式化,则先在其中一个namenode上格式化。
格式化完成后,启动已格式化的namenode,然后将格式化信息同步给未格式化的namenode节点。
[root@node01 ~]# hdfs namenode -format 格式化 [root@node01 ~]# hadoop-daemon.sh start namenode 启动节点 [root@node02 ~]# hdfs namenode -bootstrapStandby 在未格式化节点上同步
15、在namenode上格式化zkfc
[root@node01 ~]# hdfs zkfc -formatZK
16、启动Hadoop集群
[root@node01 ~]# start-dfs.sh