1.存储数据类型
2.HDFS:
存储格式面向行,面向列
分布式文件系统,并不可能只允许单机服务器
解决昂贵服务器的问题
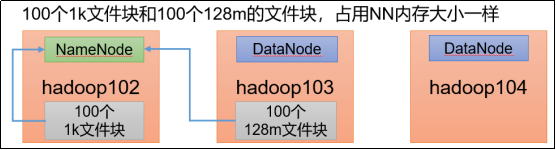
3.Hadoop不适合存储大量小文件
4.数据质量的五个维度:数据一致性(用于度量哪些数据的值在信息含义上是冲突的),数据唯一性(哪些数据是重复的,或数据的哪些属性是重复的),数据时效性(数据随时间的完整变化过程数据),数据准确性(用于度量哪些数据和信息是不正确的,或者数据是超期的),数据完整性(用于度量哪些数据丢失或不可用)
规范性(哪些数据未按统一格式存储),关联性(哪些关联数据缺失或未建立索引)
5.KPI一般指关键绩效指标法,关键指标比如数量(销售量)
6.模型拟合不足是训练误差和验证误差都很大,-> 欠拟合
7.硬盘大小:(原始数据+中间数据+结果数据)*副本数量
8.msp处理任务的工作和作用:
1)读取输入文件,把每一行解析成键值对,每一个键值对调用一次Map函数
2)对传入的键值对,覆盖map函数,实现自己的逻辑,处理键值对输出心得键值对
3)根据键值对键值对精心分区
4)对不同的分区进行数据排序分组,把相同key的value放在一起集合
9.项目请况分析,问题界定,确定项目目标因素,建立项目目标体系,各目标关系确认
10.数据分析重要环节:数据采集,数据建模(处理),数据分析,指标报告
11.功能
Hive:基于hdfs的数据库服务,支持海量数据处理,不支持实时流处理,主要进行批处理
spark:快速通用的hadoop数据计算引擎,支持多种位用
Ambari:建立配置和管理hadoop的工具,可视化界面,简化系统管理和维护
pig:大规模数据分析平台,将类似sql的数据分析请求转换为一系列经过优化处理的MapReduce运算。 批处理,流式
HBASE:列式存储,多用于ELK工作,可以离散存储不是主要功能
12.HDFS元数据采用镜像文件(FSImage)+日志文件(editlogs)备份
FSNameSystem:是NameNode实际记录信息
13.Hadoop MapReduce:批处理计算引擎
HDFS:分布式数据存储
Hadoop Yarn:大数据平台资源调度
Hadoop Hive :数据仓库工具
14.逻辑回归可以解决非线性问题
15.联机分处理:
快速行,可分析性,多维性,信息性
钻取,切片,切块,旋转(转轴)
17.指标十大要素:指标名称。定义,类属,作用计算方法,计量单位,空间规定,时间规定,指标数值及功能含义,基础数据取得方式
18.分类:定性分析,离散变量预测
回归:定量输出,连续变量预测
19.分类:有监督学习,需要有标注结果训练数据 K最近邻
聚类:无监督学习