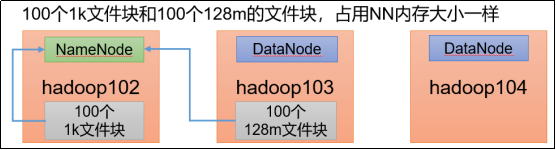
数据去重、多表查询、倒排索引、单元测试等案例编程
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118993512(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 数据去重
相当于实现sql里面的distinct的功能。废话不说多,直接进行代码编程,创建一个demo.distinct的package,然后进行框架的搭建(框架里面包含Mapper、Reducer和执行的主程序三个文件),如下

package demo.distinct;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// k1 v1 k2:job v2:null
public class distinctMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// 数据:7369,SMITH,CLERK,7902,1980/12/17,800,0,20
String data = v1.toString();
//分词
String[] words = data.split(",");
//输出
context.write(new Text(words[2]), NullWritable.get());
}
}
其次就是开发Reduce程序,只需要指定一下数据类型然后写入数据,不需要进行其它的操作
package demo.distinct;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class distinctReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text k3, Iterable<NullWritable> v3,Context context) throws IOException, InterruptedException {
context.write(k3, NullWritable.get());
}
}
接着就是执行的主程序,将原来的程序直接拿过来进行改写(还是修改之前圈出来的三个红框部分,分别对应下面的(1)(2)(3)中的内容)
package demo.distinct;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class distinctMain {
public static void main(String[] args) throws Exception {
// (1)创建任务Job,并且制定任务的入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(distinctMain.class); //指定为当前程序
//(2)指定任务的Map,Map的输出类型
job.setMapperClass(distinctMapper.class);
job.setMapOutputKeyClass(Text.class);//k2
job.setMapOutputValueClass(NullWritable.class);//v2
//(3)指定任务的Reduce,Reduce的输出类型
job.setReducerClass(distinctReducer.class);
job.setoutputKeyClass(Text.class);//k4
job.setoutputValueClass(NullWritable.class);//v4
//(4)指定任务的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setoutputPath(job, new Path(args[1]));
//(5)执行任务
job.waitForCompletion(true); //表示执行的时候打印日志
}
}
程序开发完成后打包为p12.jar,上传到hadoop上运行


2 多表查询
补充一些关于sql中的表连接的知识:
2.1 笛卡尔积
关于笛卡尔积,比如部门号有2条记录,然后员工表有4条记录,如果两表进行笛卡尔积,最后就是2x4=8条记录,如下

2.2 等值连接
查询员工信息,显示:员工号、姓名,薪水,部门名称(下面是sql语句实现)
select e.ename,d.dname
from emp e,dept d
where e.deptno=d.deptno;
在MapReduce中实现,首先要分析一些等值连接的一个过程,理清楚里面每一步的数据类型和步骤,写起来就很方便了。MapReduce:分析等值连接数据处理的流程
- (1)遇到的第一个问题就是如何判断读取的数据是来自员工表还是部门表?(方式很多,比如最简单的获取文件名)
- (2)还有就是Map的输出阶段,k2如何进行设置?(部门表和员工表分开即可,都是以部门号作为k2)
- (3)v3中如何识别哪一个是部门名称,哪一个是员工姓名?(这里就是在v2的时候进行部门表信息的标记,比如部门信息前面加个*号)

编程实现等值连接,创建一个名为demo.equal的package,然后搭建框架,还是三个文件(Mapper程序、Reducer程序和运行主程序)

首先开发Mapper程序,就是先按照之前分析的流程中指定一下数据类型,接着解决上面问题,就是判断是员工表数据还是部门表数据,然后对于部门表中的Text数据进行*号标记,用于区别部门和员工名称
package demo.equaljoin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// k1 v1 k2 部门号 v2
public class EqualJoinMapper extends Mapper<LongWritable, Text, IntWritable, Text> {
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//部门表:10,,ACCOUNTING,NEW YORK
//员工表:7369,SMITH,CLERK,7902,1980/12/17,800,0,20
String data = v1.toString();
//分词
String[] words = data.split(",");
//判断
if(words.length == 3) {
//部门表:部门号和部门名称
context.write(new IntWritable(Integer.parseInt(words[0])), new Text("*"+words[1]));
}else {
//员工表:部门号,员工姓名
context.write(new IntWritable(Integer.parseInt(words[7])), new Text(words[1]));
}
}
}
Reducer程序开发的代码稍微有点复杂,就是需要设置两个空的字符,然后对Mapper输出的数据,进行遍历,然后根据是否有*号进行分类,重新写到部门号和员工姓名字段中
package demo.equaljoin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class EqualJoinReducer extends Reducer<IntWritable, Text, Text, Text> {
@Override
protected void reduce(IntWritable k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
// 定义变量,分别保存部门名称和员工姓名
String dname = "";
String empNameList = "";
for(Text v:v3) {
String str = v.toString();
//判断是否包含*号
int index = str.indexOf("*");
if(index >= 0) {
//是部门名称
dname = str.substring(1);
}else {
//是员工姓名
empNameList = str + ";" + empNameList;
}
}
//输出
context.write(new Text(dname), new Text(empNameList));
}
}
接着就是运行的主程序,还是修改(1)(2)(3)中的内容,其余的保持不变
package demo.equaljoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EqualJoinMain {
public static void main(String[] args) throws Exception {
// (1)创建任务Job,并且制定任务的入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(EqualJoinMain.class); //指定为当前程序
//(2)指定任务的Map,Map的输出类型
job.setMapperClass(EqualJoinMapper.class);
job.setMapOutputKeyClass(IntWritable.class);//k2
job.setMapOutputValueClass(Text.class);//v2
//(3)指定任务的Reduce,Reduce的输出类型
job.setReducerClass(EqualJoinReducer.class);
job.setoutputKeyClass(Text.class);//k4
job.setoutputValueClass(Text.class);//v4
//(4)指定任务的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setoutputPath(job, new Path(args[1]));
//(5)执行任务
job.waitForCompletion(true); //表示执行的时候打印日志
}
}
程序开发完成后,打包为p13.jar文件,上传至hadoop上运行

核实生成文件中的数据信息(左侧为部门表,右侧为员工表,成功实现了)

2.3 自连接
通过表的别名,将同一张表视为多张表,查询员工信息,显示:老板名称、员工姓名(sql语句查询如下)
select b.ename,e.ename
from emp e,emp b
where e.mgr=b.empno;
在MapReduce中实现自连接,首先梳理一下这个过程,理清数据类型和步骤,图示如下

编程实现等值连接,创建一个名为demo.selfjoin的package,然后搭建框架,还是三个文件(Mapper程序、Reducer程序和运行主程序)

首先开发Mapper程序,就是先按照之前分析的流程中指定一下数据类型,对于数据的写入要进行两次,表格同时作为员工表和老板表,这里还有有防错的处理,因为数据中存在一个大boss,他上面是没有老板的,这个数据是空,所以如果遇到这条数据,就把他的老板标记为-1,这样就识别除了大boss
package demo.selfjoin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SelfJoinMapper extends Mapper<LongWritable, Text, IntWritable, Text> {
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// 员工表:7369,SMITH,CLERK,7902,1980/12/17,800,0,20
String data = v1.toString();
//分词
String[] words = data.split(",");
//输出
try {
//作为老板表:员工号 姓名
context.write(new IntWritable(Integer.parseInt(words[0])), new Text("*"+words[1]));
//作为员工表: 老板号 姓名
context.write(new IntWritable(Integer.parseInt(words[3])), new Text(words[1]));
}catch (Exception e) {
// 表示大老板
context.write(new IntWritable(-1), new Text(words[1]));
}
}
}
Reducer程序开发的代码这里比Mapper程序相较简单一点了,对比一下发现和前面的等值连接中的代码几乎一模一样,只是变量之间存在着差异
package demo.selfjoin;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SelfJoinReducer extends Reducer<IntWritable, Text, Text, Text> {
@Override
protected void reduce(IntWritable k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
//定义两个变量:老板姓名 员工姓名
String bossName = "";
String empNameList = "";
for(Text v:v3) {
String str = v.toString();
//判断是否有*号
int index = str.indexOf("*");
if(index >=0) {
//表示老板姓名
bossName = str.substring(1);
}else {
empNameList = str + ";" + empNameList;
}
}
context.write(new Text(bossName), new Text(empNameList));
}
}
运行主程序的代码设计,将(1)(2)(3)中的类名称修改一下即可
package demo.selfjoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SelfJoinMain {
public static void main(String[] args) throws Exception {
// (1)创建任务Job,并且制定任务的入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(SelfJoinMain.class); //指定为当前程序
//(2)指定任务的Map,Map的输出类型
job.setMapperClass(SelfJoinMapper.class);
job.setMapOutputKeyClass(IntWritable.class);//k2
job.setMapOutputValueClass(Text.class);//v2
//(3)指定任务的Reduce,Reduce的输出类型
job.setReducerClass(SelfJoinReducer.class);
job.setoutputKeyClass(Text.class);//k4
job.setoutputValueClass(Text.class);//v4
//(4)指定任务的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setoutputPath(job, new Path(args[1]));
//(5)执行任务
job.waitForCompletion(true); //表示执行的时候打印日志
}
}
程序设计完成后打包生成p14.jar文件,上传hadoop上进行

查看一下输出的文件中是够有什么问题不。直接输出的结果中并不是我们想要的结果,主要是因为,公司的人员架构中大boss上面没有人了,最底层的员工下面也没有人了,所以就造成输出的样式

对代码进行改进,判断如果存在老板和员工才进行输出(在Reducer程序中修改)

重新打包一下生成p15.jar文件,然后上传hadoop上运行

接下来就是见证奇迹的时候了,啦啦啦~(很完美,和想象中的输出一毛一样)

3 倒排索引
之前在介绍WordCount计数的时候就已经介绍过倒排索引的过程,如下

接下来就是用编程的方式自己写代码实现一下倒排索引。准备测试数据,在temp文件夹下创建三个文件,内容分别如下
vi data01.txt
I love Beijing and love Shanghai
vi data02.txt
I love China
vi data03.txt
Beijing is the capital of China
检验创建的数据,核实无误

然后将创建的数据上传到hdfs上,代码指令:
hdfs dfs -put data0*.txt /indexdata
那么就是用MapReduce实现倒排索引,首先要分析一下这个过程的数据类型和步骤,如下
- 一个文件中出现重复的内容,为了提高性能可以引入Combiner
- Combiner的加入不影响结果和处理的逻辑(这里特别注意v2和v3,保证逻辑的统一v2和最后的v2’都应该为Text数据类型)

流程分析完毕后就是创建一个demo.revertedindex的package,然后搭建框架(Mapper程序、Reducer程序和运行主程序,注意这次还有个Combiner程序是继承Reducer)

先开始设计Mapper程序,里面的关键就是获取文件名称,然后在进行字符串的切割求解得到(注意仿照预设定的格式进行获取/存取数据)
package demo.revertedindex;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; /这个包别导错了
import org.apache.hadoop.mapreduce.Mapper;
public class RevertedindexMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// 数据:data01.txt I love Beijing and love Shanghai
//获取输入数据的路径: /indexdata/data01.txt
String path = ((FileSplit)context.getInputSplit()).getPath().toString();
//查询最后一个斜线
int index = path.indexOf("/");
//得到文件名
String fileName = path.substring(index+1);
String data = v1.toString();
//分词
String[] words = data.split(",");
//输出
for(String w:words) {
context.write(new Text(w+":"+fileName), new Text("1"));
}
}
}
接着处理Combiner程序,跟着分析的流程一步步进行就可以了
package demo.revertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class RevertedindexCombiner extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text k21, Iterable<Text> v21, Context context)
throws IOException, InterruptedException {
// 对v21求和,得到某个单词在某个文件中频率
int total = 0;
for(Text v:v21) {
total = total + Integer.parseInt(v.toString());
}
//k21的数据是:love:data01.txt
String data = k21.toString();
int index = data.indexOf(":");
String word = data.substring(0,index);
String fileName = data.substring(index+1);
// love data01.txt:2
context.write(new Text(word), new Text(fileName+":"+total));
}
}
然后就是处理Reducer程序中的内容,对于Combiner传输的数据,进行遍历循坏,依次转化为目标的格式,最后再输出
package demo.revertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class RecertedindexReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
//对combiner的输出结果进行拼加
String str = "";
for(Text v:v3) {
str = "(" + v.toString()+")" + str;
}
context.write(k3, new Text(str));
}
}
最后就是编写运行主程序的代码,把之前的代码拿过来修改一下即可(还需要添加中间的Combiner)
package demo.revertedindex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RevertedindexMain {
public static void main(String[] args) throws Exception {
// (1)创建任务Job,并且制定任务的入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(RevertedindexMain.class); //指定为当前程序
//(2)指定任务的Map,Map的输出类型
job.setMapperClass(RevertedindexMapper.class);
job.setMapOutputKeyClass(Text.class);//k2
job.setMapOutputValueClass(Text.class);//v2
//引入Combiner
job.setCombinerClass(RevertedindexCombiner.class);
//(3)指定任务的Reduce,Reduce的输出类型
job.setReducerClass(RevertedindexReducer.class);
job.setoutputKeyClass(Text.class);//k4
job.setoutputValueClass(Text.class);//v4
//(4)指定任务的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setoutputPath(job, new Path(args[1]));
//(5)执行任务
job.waitForCompletion(true); //表示执行的时候打印日志
}
}
程序全部开发完成后,打包为p16.jar,上传至hadoop上运行(这次是在map阶段有了三步)

核实一下生成的文件中的信息(最后的内容输出格式上貌似和原来设想的很不一样,因此肯定是中间的数据处理出问题了)

接着就是找问题,发现在Mapper程序中有两行代码大意了,习惯性的敲出来了(一个是最后的索引少了last,第二个就是分割的时候这次是空格不是逗号)

修改完毕后重新打包上传运行结果如下(很完美,这次和预期一样,啦啦啦~)

4 单元测试
之前运行MapReduce程序都是程序开发完成之后,通过WinSCP软件将本地的jar包上传至hadoop上,然后再进行操作,但是这种方式并不是很方便,我们希望可以直接就在开发工具中运行测试(可以直接下载hadoop插件,不过这里还有一个MRUNIT框架就可以实现对MapReduce进行测试)
在工程项目中创建一个新的文件夹,命名为mrunit,将提供的资料中的相关jar都放置在该文件夹下,并添加环境,这样MRUNIT环境就配置完成了,接下来就可以直接进行测试

特别注意一下,添加环境的jar包有一个是和别的jar包有冲突,需要进行剔除(mockito-all-1.8.5.jar)

接着就是见证奇迹的时候啦,以之前写过的WordCount程序为例,测试一下能不能直接调试运行,创建一个新的package命名为demo.mrunit,然后将wc中的Mapper和Reducer程序直接拷贝过来,分别进行测试
创建一个新的Java Class命名为MRUnitWordCount,设置好测试的框架,就是Mapper程序,Reducer程序和Job运行程序

首先处理Mapper的测试,注意导入的MapDriver是在org.apache.hadoop.mrunit.mapreduce下
@Test
public void testMapper() throws Exception{
//创建一个WordCountMapper的测试对象
WordCountMapper mapper = new WordCountMapper();
//创建一个Driver进行单元测试
MapDriver<LongWritable,Text, Text, IntWritable> driver = new MapDriver(mapper);
//指定Map输入的数据
driver.withInput(new LongWritable(1),new Text("I love Beijing"));
//指定Map的输出
driver.withOutput(new Text("I"),new IntWritable(1))
.withOutput(new Text("love"),new IntWritable(1))
.withOutput(new Text("Beijing"),new IntWritable(1));
//执行单元测试,对比:我们希望得到的结果和实际运行的结果
driver.runtest();
}
点击鼠标右键进行运行,结果显示为绿色,说明实际输出和我们期望输出一致

不妨将上面的红框的内容进行修改一下,比如love单词的次数修改为2,然后再次运行,查看一下运行结果(左侧的状态条为红色,输出报错中有提醒,最终的love单词出现的次数为1,不是期望的2)

Mappper程序测试成功,接着就是测试一下Reduce程序
@Test
public void testReducer() throws Exception{
WordCountReducer reducer = new WordCountReducer();
ReduceDriver<Text, IntWritable, Text, IntWritable>
driver = new ReduceDriver<Text, IntWritable, Text, IntWritable>(reducer);
//构造Reducer输入 List
ArrayList<IntWritable> value3 = new ArrayList<IntWritable>();
value3.add(new IntWritable(1));
value3.add(new IntWritable(1));
value3.add(new IntWritable(1));
driver.withInput(new Text("Beijing"),value3);
//指定Reducer的输出,是我们希望得到的结果
driver.withOutput(new Text("Beijing"),new IntWritable(3));
driver.runtest();
输出的结果为:(运行状态条为绿色,测试通过)

如果将期望的输出结果调成4,运行的结果如下(证明程序可以来测试啦)

最后就是来测试运行的Job,代码如下
@Test
public void testJob() throws Exception{
//创建对象
WordCountMapper mapper = new WordCountMapper();
WordCountReducer reducer = new WordCountReducer();
//创建Driver
MapReduceDriver<LongWritable,Text, Text, IntWritable,Text, IntWritable>
driver = new MapReduceDriver(mapper,reducer);
//指定Mapper输入的数据
driver.withInput(new LongWritable(1),new Text("I love Beijing"))
.withInput(new LongWritable(2),new Text("I love China"))
.withInput(new LongWritable(3),new Text("Beijing is the capital of China"));
//指定Reducer的输出
driver.withOutput(new Text("I"),new IntWritable(2))
.withOutput(new Text("love"),new IntWritable(2))
.withOutput(new Text("Beijing"),new IntWritable(2))
.withOutput(new Text("China"),new IntWritable(2))
.withOutput(new Text("is"),new IntWritable(1))
.withOutput(new Text("the"),new IntWritable(1))
.withOutput(new Text("capital"),new IntWritable(1))
.withOutput(new Text("of"),new IntWritable(1));
driver.runtest();
}
输出的结果为:(可以发现最终的计数是正常的,但是顺序不对)

因为MapReduce会有一个默认的排序规则,我们调整一下最后的输出的内容,然后再运行,可以发现按照字典的顺序进行输出后,状态条显示绿色,测试正确

至此,关于数据去重、多表查询、倒排索引、单元测试等案例编程就梳理完了。MapReduce的知识点也就全部完结了,下一个博客就是进行之前的内容的回顾,复习一下,查漏补缺。撒花✿✿ヽ(°▽°)ノ✿