Day 11
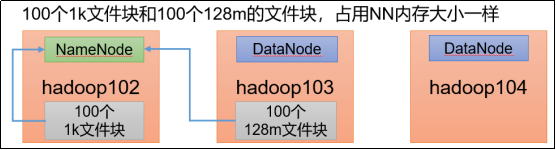
466关于Hadoop HDFS名称节点中的元数据信息,下面说法正确的是() 。
文件是什么:包括目录自身的属性信息,例如文件名,目录名,修改信息等
文件被分成了多少块
467关于Hadoop HDFS1.0的局限性包括( )。
命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。
集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
468以下哪几种数据结构被AutoreleasePoolPage使用()
链表
栈
469下面属于Hadoop生态圈组件的是() 。
MapReduce
Hive
HBase
470 Hadoop的核心组件包括() 。
MapReduce
HDFS
471关于Hadoop HDFS块的概念,下面说法正确的是( )。
为了分摊磁盘读写开销也就是大量数据间分摊磁盘寻址开销
HDFS块比普通的文件块大很多
Hadoop1.x中,默认为64MB,可以调大但不是越大越好
472关于Hadoop HDFS名称节点中的Fslmage中,主要信息包括()
文件的复制等级
文件的访问权限
组成文件的块
473关于Hadoop HDFS的冗余数据存储设计的优点,下面说话正确的是( )。
加快数据传输速度 当多个客户端同时访问一个数据,可以让各个客户端分别从不同的数据块副本读取数据。
容易检查数据错误 数据节点之间通过网络传输,采用多副本方式容易判断数据是否出错。
容易保证数据的一致性
即使某个节点出现故障,也不会造成数据丢失
474 Hadoop HDFS的设计目标包括( ) 。
兼容廉价的硬件设备
支持大数据集
跨平台性
475关于Hadoop HDFS块的设计的优点,下面说法正确的是( )。
简化系统设计
适合数据备份
能够实现冗余备份机制
476关于Hadoop HDFS的文件操作,正确的是() 。
HDFS可以创建文件并写入数据
HDFS可以更改文件名
477逻辑回归是数据挖掘算法中常用的模型算法,以下关于逻辑回归的说法正确的是
逻辑回归对模型中自变量的多重共线性较为敏感。
逻辑回归属于分类算法
478数据离散化的方法有哪些
等距离散法
等频离散法
479以下有关误差的说法中,正确的是( ) 。
评价预测精度是通过测量与分析预测误差进行的
绝对误差是实际观测值与预测值的离差
相对误差反映实际观测值与预测值之间差异的相对程度
平均误差反映实际观测值与预测值之间的平均差异
480以下算法中对缺失值不敏感的是
Logistic回归
SVM算法
Day 12
511 回归平方和 (ESS) 是指()
被解释变量的回归值与平均值的离差平方和
解释变量变动所引起的被解释变量的变差
512 Logistic建模时,如果变量Area=C时, Y取值均为1,无法确定是先出现的是哪个问题
拟完全分离(Quasi-complete separation)
缺失值
513工消除时间序列中的不规则变动和季节变动的方法是()
移动平均法
指数平滑法
时间序列乘法模型
514 c4.5算法是由ROSS Quinlan开发的用于产生决策树的算法,以下描述正确的有
使用gain ratio作为节点分割的依据
可以处理数值型态的字段
可以处理空值的字段
515维归约即摒弃掉不重要的特征,用少数的关键特征来描述数据。常用的维归约处理有
主成分分析
奇异值分解
516时间序列预测方法分为
平滑法预测
ARIMA模型预测
Winter法
517 MapReduce与HBase的关系, 哪些描述是正确的。( )
两者不是强关联关系,没有MapReduce,HBase可以正常运行
MapReduce可以连接HBase
518 Resourcemanger主要作用是什么()?
调度器
应用程序管理器
节点资源管理
519以下对SPARK的描述,正确的是?
高性能内存迭代计算框架
内存计算一站式解决方案
520以下哪些是Spark的常驻进程 () ?
JobHistory
JDBCServer
521 关于HBase的特性,哪些是正确的( ) ?
高可靠性
高性能
面向列
可伸缩
522 HBase读数据时需要读取哪几部分数据()?
HFile
MemStore
523 Loader作业的配置包括以下哪些步骤() ?
FusionInsight HD
FusionInsight Farmer
FusionInsight miner
525 FusioninsightManager的主要功能有以下哪些? ()
安全管理
服务治理
Day 13
556 Yarn 中,“从”节点负责以下哪些工作?
监督container的生命周期管理
监控每个Container的资源使用(内存、cpu等)情况
管理日志和不同应用程序用到的附属服务
557 Spark有哪些特点?
灵
轻
巧
558 与开源sqoop相比,loader具有哪些增强属性?
高性能
安全性
图形化
559 Fusioninsight HD loader 可以将HDFS 数据导出到以下哪些目标端?
SFTP服务器
BD2数据库
FTP服务器
560 FusioninsiahtHD在创建作业时连接器有以下哪些作业?
确定有转换
提供优化参数导出性能
561 Fusioninsight家族包含下列哪些子产品?
Fusioninsight miner
Fusioninsight HD
GAUSSDB 200
562 数据流如何Transformation 之间传输数据数据流可以分为那些类型?
一对多流
Redistributing流
563 Flink的兼容性体现在以下哪些方面?
能够与Hadoop 原有的Mappers和Reducers混合使用
能够使用Hadoop的格式化输入和输出口
能够从本地获取数据
564以下关于Hbase的文件存储模块(Hbase Filestream,简称HFS)描述正确的有?
HFS 是Hbase的独立模块
565 若在消息处理过程中允并部分信息丢失,关闭消息可靠性处理机制的方式有以下哪些?
spout发送消息时,使用不指定消息mesageic
Bolt发送消息时使用Unanchor方式发送
的接口进行发送
566 采用Flume传输数据过程中,为了防止因F1me进程重启而丢失数据,可以使用以下哪种Channel类型? (单选!)
File Channel
567 关于Hbase 存储型的描述正确的是?
同-个key值可以关联多个value
keyvalue 期有时间戳类型等关键信息
568 fusioninstght hd集群包含多种服务,每种服务又有若干个角色组成,下面那些是角色
namenode
hbase
datanode
569 FusinsngtHD平台中,哪些组件支持对列表加密?
namenode
hbase
570 YARN容量调度器的主要特点有哪些
动态更新配置文件
灵活性
多重租赁
Day 14
601以下哪些是Spark 服务的常驻进程?
JobHistory
JDBCServer
602 Hadoop 的HDFS是一种分布式文件系统,适合以下哪种场景的数据存储和管理?
高容错高吐量
流式数据访问
603基于 Hadoop开源大数据平台主要提供了针对数据分布式计算和存储能力,如下属于分布式存储组件的有?
HDFS
HBase
604关于大数据的主要特征理解和描述正确的有?
来源多,格式多
增长速度快处理速度快
存储量大,计算里大
数据的价值密度较低
605 Hadoop通过 ResourceManager对集群资源进行管理,它的主要功能有?
集群资源调度
应用程序管理
集群资源管理
606 以下关于Hadoop的HDFS描述正确的有?
HDFS由NameNode,Datanode ,client组成
HDFS备 NameNode上的元数据是主NameNode同步过去的
HDFS 采用就近的机架节点进行数据的第一副本存储
607 Hadoop系统中YARN支持哪些资源类型的管理?
内存
608以下哪些是Spark可以提供的功能?
分布式内存计算引擎
流处理功能
609从生命周期维度看,数据主要经历那几个阶段?
数据采集
数据存储
数据管理
数据分析
610 YARN客里调度器的主要特点有哪些?
容里保证
灵活比
611执行HBase读数据业务,需要读取哪几部分数据?
HFile
Mem Store
612大数据分析相关技术主要特征包括?
机器学习,全量特征
数据背后事件关联性分析
基于海量数据为基础
基于精确样本为基础
613 Hadoop 的HBase主要特点有哪些?
高可靠性
高性能
面向列
可伸缩
614 Spark可以接收哪些来源的数据?
HDFS
HIVE
HBase
615关于SecondaryNameNode 哪项是正确的? (单选!)
它的目的是帮助NameNode合并编辑日志, 减少NameNode启动时间
Day 15
646 Task 运行不在以下选项中Executor 上的工作单元()
Driver program
Sark master
Cluster manager
647关于spark容错说法错误的有〔)
在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,依赖于其他节点
RDD的容错机制是基于Spark Streaming的容错机制
648 sparkRdd转换算子有()
map
filter
mapPartitions
649下面哪些端口是spark自带服务的端口
8080
404
18080
650于spark中数据倾斜引发原因正确的选项有
key本身分布不均衡
计算方式有误
过多的数据在一个task里面
shuffle并行度不够
651 spark driver的功能是什么
是作业的主进程
负责了作业的调度
负责作业的解析
652 Master的Electedleader事件后不做哪些操作
通知driver
通知worker
注册application
653 SparkContext可以从哪些位置读取数据
本地磁盘
hdfs
内存
构造函数里
class内
object内
main函数内
655 MLIlib包括
分类模型
聚类模型
特征抽取
统计模型
656在网络爬虫的爬行策略中,应用最为基础的是
深度优先遍历策略
广度优先遍历策略
657当前,大数据产业发展的特点是
规模较小
增速很快
658下列关于数据生命周期管理的核心认识中,正确的是
数据从产生到被删除销毁的过程中,具有多个不同的数据存在阶段
在不同的数据存在阶段,数据的价值是不同的
根据数据价值的不同应该对数据采取不同的管理策略
659下列关于基于大数据的营销模式和传统营销模式的说法中,错误的是
传统营销模式比基于大数据的营销模式投入更小
传统营销模式比基于大数据的营销模式针对性更强
传统营销模式比基于大数据的营销模式转化率低
660下列关于脏数据的说法中,正确的是
格式不规范
编码不统一
意义不明确
与实际业务关系不大