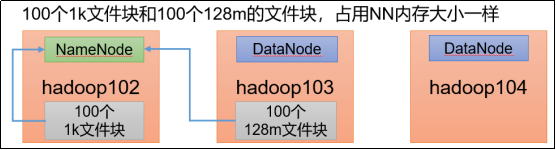
四、Hadoop安装
将软件包hadoop和jdk传入
1.配置网络信息、主机名以及主机名与IP地址的映射关系(在所有节点上执行)
vi /etc/sysconfig/network-scripts/ifcfg-网卡名
TYPE=Ethernet
NAME=网卡名
DEVICE=网卡名
BOOTPROTO=static
ONBOOT=yes
IPADDR=你自己的IP
NETMASK=255.255.255.0
GATEWAY=你自己的网关
DNS1=114.114.114.114
# 保存以上配置后执行以下命令
ifdown 网卡名;ifup 网卡名
hostnamectl set-hostname 主机名.example.com
bash
hostname
vi /etc/hosts
10.10.10.128 master master.example.com
10.10.10.129 slave1 slave1.example.com
10.10.10.130 slave2 slave2.example.com
# 保存以上配置后执行以下命令
ping master
ping slave1
ping slave2
2.关闭防火墙与SELinux(在所有节点上执行)
systemctl disable --Now firewalld
setenforce 0
vi /etc/selinux/config
SELINUX=disabled
3.安装hadoop(在master节点上执行)
tar xf jdk-8u152-linux-x64.tar.gz -C /usr/local/src/
tar xf hadoop-2.7.1.tar.gz -C /usr/local/src/
cd /usr/local/src/
mv jdk1.8.0_152 jdk
mv hadoop-2.7.1 hadoop
vi /etc/profile.d/hadoop.sh
export JAVA_HOME=/usr/local/src/jdk
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 保存以上配置后执行以下命令
source /etc/profile.d/hadoop.sh
echo $PATH
vi /usr/local/src/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk
4.配置hdfs-site.xml文件参数(在master上执行)
vi /usr/local/src/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
# 保存以上配置后执行以下命令
mkdir -p /usr/local/src/hadoop/dfs/{name,data}
5.配置core-site.xml文件参数(在master上执行)
vi /usr/local/src/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
# 保存以上配置后执行以下命令
mkdir -p /usr/local/src/hadoop/tmp
6.配置mapred-site.xml文件参数(在master上执行)
cd /usr/local/src/hadoop/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi /usr/local/src/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
7.配置yarn-site.xml文件参数(在master上执行)
vi /usr/local/src/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>arn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
8.hadoop的其它相关配置
# 在master上执行以下命令
vi /usr/local/src/hadoop/etc/hadoop/masters
10.10.10.128
# 保存后执行以下命令
vi /usr/local/src/hadoop/etc/hadoop/slaves
10.10.10.129
10.10.10.130
# 保存后执行以下命令
useradd hadoop
echo 'hadoop' | passwd --stdin hadoop
chown -R hadoop.hadoop /usr/local/src
ll /usr/local/src/
# 配置master能够免密登录所有slave节点
ssh-keygen -t rsa
ssh-copy-id root@slave1
ssh-copy-id root@slave2
# 同步/usr/local/src/目录下所有文件至所有slave节点
scp -r /usr/local/src/* root@slave1:/usr/local/src/
scp -r /usr/local/src/* root@slave2:/usr/local/src/
scp /etc/profile.d/hadoop.sh root@slave1:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@slave2:/etc/profile.d/
# 在所有slave节点上执行以下命令
useradd hadoop
echo 'hadoop' | passwd --stdin hadoop
chown -R hadoop.hadoop /usr/local/src
ll /usr/local/src/
source /etc/profile.d/hadoop.sh
echo $PATH
五、Hadoop集群运行
#master上操作
su - hadoop
cd /usr/local/src/hadoop/
./bin/hdfs namenode -format
hadoop-daemon.sh start namenode
hadoop-daemon.sh start secondarynamenode
jps
#看到NameNode和SecondayNameNode
#slave1上操作
su - hadoop
hadoop-daemon.sh start datanode
jps
#slave2上操作
su - hadoop
hadoop-daemon.sh start datanode
jps
#看到Datanode
#master上操作
su - hadoop
hdfs dfsadmin -report
ssh-keygen -t rsa
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id master
stop-dfs.sh
start-dfs.sh
start-yarn.sh
jps
#master上看到ResourceManager,slave上看到NodeManager
hdfs dfs -mkdir /input
hdfs dfs -ls /
mkdir ~/input
vi ~/input/data.txt
Hello World
Hello Hadoop
Hello Huasan
hdfs dfs -put ~/input/data.txt /input
hdfs dfs -cat /input/data.txt
hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
#执行完看到map为100%,reduce为100%,还要看到successfully
六、Hive组建
一、检查进程是否运行
在所有节点执行:
su - hadoop
jps
#要在master上看到NameNode、Secondarynamenode、ResourceManager三个进程,要在slave1、slave2上看到Datanode、Nodemanager进程
若进程没运行输入以下命令:
start-all.sh
二、卸载MariaDB数据库
[root@master ~]# rpm -qa | grep mariadb
mariadb-libs-5.5.52-2.el7.x86_64
[root@master ~]# rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64
三、部署MysqL
master主机部署
#安装unzip
yum -y install unzip
#进入software路径
cd software/
#解压MysqL压缩包
unzip MysqL-5.7.18.zip
#进入MysqL路径
cd MysqL-5.7.18
#安装MysqL
yum -y install *.rpm
#配置数据库配置
vi /etc/my.cnf
default-storage-engine=innodb
innodb_file_per_table
collation-server=utf8_general_ci
init-connect='SET NAMES utf8'
character-set-server=utf8
#设置开机自启
systemctl enable --Now MysqLd
#查看默认密码
cat /var/log/MysqLd.log|grep password
#初始化
MysqL_secure_installation
输入/var/log/MysqLd.log密码
y
Password123!
Password123!
y
y
n
y
y
#进入数据库
MysqL -uroot -p'Password123!'
#添加 root用户本地访问授权
MysqL> grant all on *.* to 'root'@'localhost' identified by 'Password123!';
#添加root用户远程访问授权
MysqL> grant all on *.* to 'root'@'%' identified by 'Password123!';
#查询root用户授权情况
MysqL> flush privileges;
#退出
MysqL> quit
四、测试MysqL
slave1上部署
#安装Mariadb
yum -y install mariadb
#测试
MysqL -uroot -p'Password123!' -h10.10.10.128
五、安装hive组件
master主机部署/usr/local/src/
#解压Apache压缩包到
tar xf software/apache-hive-2.0.0-bin.tar.gz -C /usr/local/src/
#进入/usr/local/src
cd /usr/local/src/
#移动并更名为hive
mv apache-hive-2.0.0-bin/ hive
#设置归属用户和用户组
chown -R hadoop.hadoop /usr/local/src/
#配置hive.sh文件
vi /etc/profile.d/hive.sh
export HIVE_HOME=/usr/local/src/hive
export PATH=${HIVE_HOME}/bin:$PATH
#执行
source /etc/profile.d/hive.sh
#查看是否成功
echo $PATH
#切换hadoop用户
su - hadoop
#进入/usr/local/src/hive/conf/
cd /usr/local/src/hive/conf/
#复制
cp hive-default.xml.template hive-site.xml
#配置配置文件
vi hive-site.xml
#配置数据库连接
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:MysqL://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
#配置root密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Password123!</value>
<description>password to use against metastore database</description>
</property>
#配置元数据存储版本一致,若默认false,不修改
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one fr
om Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema
after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with
one from in Hive jars.
</description>
</property>
#配置驱动
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.MysqL.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
#配置数据库用户名为root
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
#替换
<name>hive.querylog.location</name>
<value>/usr/local/src/hive/tmp</value>
<description>Location of Hive run time structured log file</description>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/src/hive/tmp</value>
<description>Local scratch space for Hive jobs</description>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/src/hive/tmp/resources</value>
<description>Temporary local directory for added resources in the remote file s
ystem.</description>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/src/hive/tmp/operation_logs</value>
<description>Top level directory where operation logs are stored if logging fun
ctionality is enabled</description>
#创建文件夹
mkdir -p /usr/local/src/hive/tmp/{resources,operation_logs}
#复制
cp software/mysql-connector-java-5.1.46.jar /usr/local/src/hive/lib/
#停掉进程,用jps命令确认没有进程
stop-all.sh
#启动
start-all.sh
schematool -initSchema -dbType MysqL
#看到schemaTool completed表示初始化成功
MysqL -uroot -p'Password123!' -e 'show databases;'
hive
hive>
七、Zookeeper安装
一、配置时间同步
#打开配置文件
[root@master ~]# vi /etc/chrony.conf
pool time1.aliyun.com iburst
二、部署zookeeper
master配置
#解压包
[root@master conf]# tar xf zookeeper-3.4.8.tar.gz -C /usr/local/src/
#进入目录
[root@master ~]# cd /usr/local/src/
#移动目录为zookeeper
[root@master src]# mv zookeeper-3.4.8/ zookeeper
#进入下载目录
[root@master src]# cd /usr/local/src/zookeeper/
#创建文件夹
[root@master zookeeper]# mkdir data logs
#写入
[root@master zookeeper]# echo '1' > /usr/local/src/zookeeper/data/myid
#进入配置文件
[root@master zookeeper]# cd /usr/local/src/zookeeper/conf
#复制
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
#修改 dataDir参数内容如下:
dataDir=/usr/local/src/zookeeper/data
#在zoo.cfg文件末尾追加以下参数配置,表示三个 ZooKeeper节点的访问端口号
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
[root@master conf]# vi /etc/profile.d/zookeeper.sh
# 在文件末尾追加
export ZOOKEEPER_HOME=/usr/local/src/zookeeper #ZooKeeper安装目录
export PATH=${ZOOKEEPER_HOME}/bin:$PATH #ZooKeeper可执行程序目录
#提权
[root@master conf]# chown -R hadoop.hadoop /usr/local/src/
#传输
[root@master conf]# scp -r /usr/local/src/zookeeper/ slave1:/usr/local/src/
[root@master conf]# scp -r /usr/local/src/zookeeper/ slave2:/usr/local/src/
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave1:/etc/profile.d/
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave2:/etc/profile.d/
slave配置
#提权
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave1 ~]# ll /usr/local/src/
#提权
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave2 ~]# ll /usr/local/src/
#写入
[root@slave1 ~]# echo '2' > /usr/local/src/zookeeper/data/myid
[root@slave2 ~]# echo '3' > /usr/local/src/zookeeper/data/myid
三、启动zookeeper
#切换用户
[root@master ~]# su - hadoop
Last login: Fri Apr 22 15:04:50 CST 2022 on pts/1
#启动zookeeper
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#查看进程
[hadoop@master ~]$ jps
2612 ResourceManager
3286 Jps
2235 NameNode
2444 SecondaryNameNode
3260 QuorumPeerMain
#查看运行状态
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
#切换用户
[root@slave1 ~]# su - hadoop
Last login: Fri Apr 22 15:04:19 CST 2022 on pts/1
#启动zookeeper
[hadoop@slave1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#查看进程
[hadoop@slave1 ~]$ jps
1841 Datanode
2324 Jps
2300 QuorumPeerMain
1967 NodeManager
#查看运行状态
[hadoop@slave1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
#切换用户
[root@slave2 ~]# su - hadoop
Last login: Fri Apr 22 15:04:37 CST 2022 on pts/1
#启动zookeeper
[hadoop@slave2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#查看进程
[hadoop@slave2 ~]$ jps
2258 QuorumPeerMain
1945 NodeManager
1819 Datanode
2284 Jps
#查看运行状态
[hadoop@slave2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
八、HBase安装
一、配置时间同步
master
#安装chrony
yum -y install chrony
#配置配置文件
vi /etc/chrony.conf
pool time1.aliyun.com iburst
#设置开机自启动
systemctl enable --Now chronyd
#查看运行状态
systemctl status chronyd
二、部署HBase
master配置
#解压包
tar xf software/hbase-1.2.1-bin.tar.gz -C /usr/local/src/
#进入目录
cd /usr/local/src/
#移动为hbase
mv hbase-1.2.1 hbase
#修改配置文件
vi /etc/profile.d/hbase.sh
export HBASE_HOME=/usr/local/src/hbase export PATH=${HBASE_HOME}/bin:$PATH
#启用
source /etc/profile.d/hbase.sh
echo $PATH
vi hbase-env.sh
export JAVA_HOME=/usr/local/src/jdk
export HBASE_MANAGES_ZK=true
export HBASE_CLAsspATH=/usr/local/src/hadoop/etc/hadoop/
vi hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value> # 使用 9000端口
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value> # 使用 master节点 60010端口
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> # 使用 master节点 2181端口
<description>Property from ZooKeeper's config zoo.cfg. The port at which the clients will connect.</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value> # ZooKeeper超时时间
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value> # ZooKeeper管理节点
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/src/hbase/tmp</value> # HBase临时文件路径
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value> # 使用分布式 HBase
</property>
mkdir -p /usr/local/src/hbase/tmp
vi regionservers
10.10.10.129
10.10.10.130
scp -r /usr/local/src/hbase/ slave1:/usr/local/src/
scp -r /usr/local/src/hbase/ slave2:/usr/local/src/
scp /etc/profile.d/hbase.sh slave1:/etc/profile.d/
scp /etc/profile.d/hbase.sh slave2:/etc/profile.d/
chown -R hadoop.hadoop /usr/local/src/
ll /usr/local/src/ su - hadoop
slave1配置
chown -R hadoop.hadoop /usr/local/src/
ll /usr/local/src/
su - hadoop
slave2配置
chown -R hadoop.hadoop /usr/local/src/
ll /usr/local/src/
su - hadoop
三、启动HBase
start-all.sh
start-hbase.sh
C:\windows\system32\drivers\etc\hosts
10.10.10.128 master

四、HBase语法
步骤一:进入 HBase 命令行
[hadoop@master ~]$ hbase shell
步骤二:建立表 scores,两个列簇:grade 和 course
hbase(main):001:0> create 'scores','grade','course'
0 row(s) in 1.4480 seconds
=> Hbase::Table - scores
步骤三:查看数据库状态
hbase (main) :001 :0> status
1 active master, 0 backup masters, 2 servers, 0 dead, 1.0000 average load
步骤四:查看数据库版本
hbase (main) :002:0> version
1.2.1,r8d8a7107dc4ccbf36a92f64675dc60392f85c015,Wed Mar 30 11:19:21 CDT 2016
步骤五:查看表
hbase(main):008:0> list
TABLE
scores
1 row(s) in 0.0100 seconds
=>["scores"]
步骤六:插入记录 1:jie,grade: 143cloud
hbase(main):003:0> put 'scores','jie','grade:','146cloud'
0 row(s) in 0.2250 seconds
步骤七:插入记录 2:jie,course:math,86
hbase(main):004:0> put 'scores','jie','course:math','86'
0 row(s) in 0.0190 seconds
步骤八:插入记录 3:jie,course:cloud,92
hbase(main):005:0> put 'scores','jie','course:cloud','92'
0 row(s) in 0.0170 seconds
步骤九:插入记录 4:shi,grade:133soft
hbase(main):006:0> put 'scores','shi','grade:','133soft'
0 row(s) in 0.0070 seconds
步骤十:插入记录 5:shi,grade:math,87
hbase(main):007:0> put 'scores','shi','course:math','87'
0 row(s) in 0.0060 seconds
步骤十一:插入记录 6:shi,grade:cloud,96
hbase(main):008:0> put 'scores','shi','course:cloud','96'
0 row(s) in 0.0070 seconds
步骤十二:读取 jie 的记录
hbase(main):009:0> get 'scores','jie'
COLUMN CELL
course:cloud timestamp=1460479208148, value=92
course:math timestamp=1460479163325,value=86
grade: timestamp=1460479064086,value=146cloud
3 row(s) in 0.0800 seconds
步骤十三:读取 jie 的班级
hbase(main):012:0> get 'scores','jie','grade'
COLUMN CELL
grade: timestamp=1460479064086,value=146cloud
1 row( s) in 0.0150 seconds
步骤十四:查看整个表记录
hbase(main):013:0> scan 'scores'
ROW COLUMN+CELL
jie column=course:cloud, timestamp=1460479208148,value=92
jie column-course:math, timestamp=1460479163325, value=86
jie column=grade:,timestamp=1460479064086,value=146cloud
shi column=course:cloud, timestamp=1460479342925,value=96
shi column=course:math, timestamp=1460479312963,value=87
shi column=grade:,timestamp=1460479257429, value=133soft
2 row(s) in 0.0570 seconds
步骤十五:按例查看表记录
hbase(main):014:0> scan 'scores',{COLUMNS=>'course'}
ROW COLUMN+CELL
jie column=course:cloud, timestamp=1460479208148, value=92
jie column=course:math, timestamp=1460479163325, value=86
shi column=course:cloud, timestamp=1460479342925, value=96
shi column=course:math, times tamp=1460479312963, value=87
2 row(s) in 0. 0230 seconds
步骤十六:删除指定记录
hbase(main):015:0> delete 'scores','shi','grade'
0 row(s) in 0.0390 seconds
步骤十七:删除后,执行scan命令
hbase(main):016:0> scan 'scores'
ROW COLUMN+CELL
jie column=course:cloud, timestamp=1460479208148, value=92
jie column=course:math, timestamp=1460479163325, value=86
jie column=grade:, timestamp=1460479064086, value=146cloud
shi column=course:cloud, timestamp=1460479342925, value=96
shi column=course:math, timestamp=1460479312963, value=87
row( s) in 0. 0350 seconds
步骤十八:增加新的列簇
hbase(main):017:0> alter 'scores',NAME=>'age'
Updating all regions with the new schema...
0/ 1 regions updated.
1/ 1 regions updated.
Done.
0 row(s) in 3.0060 seconds
步骤十九:查看表结构
hbase(main):018:0> describe 'scores'
Table scores is ENABLED
scores
COLUMN FAMIL IES DESCRIPTION
{NAME => age',BL O0MFILTER =>ROW',VERSIONS => '1' ,IN_ MEMORY
=> 'false', KEEP DELETED_ CELLS =>FAL SE',DATA BLOCK ENCODING =>
NONETTL => ' FOREVER', COMPRESSION=>NONE',MIN VERSIONS => '0' ,
BLOCKCACHE => ' true BLOCKSIZE =>65536',REPLICATION_ ScopE =>
'0'}
{NAME =>course,BLOOMFILTER => ' ROW', VERSIONS =>IN MEMORY =>
false', KEEPDELETED CELLS =>FALSE', DATA BLOCK ENCODING =>
1 NONE',TTL =>FOREVER',COMPRESSION =>NONE',MIN VERSIONS => '0'
BLOCKCACHE => 'true' ,BLOCKSIZE =>65536',REPLICATION ScopE
=>0'}{NAME => grade BLOOMFILTER => 'ROW' ,VERSIONS =>IN_ MEMORY =>
' false', KEEPDELETED CELLS =>FALSE',DATA BLOCK ENCODING =>1 NONE
'TTL =>FOREVER',COMPRESSION =>NONE',MIN VERSIONS => '0'
BLOCKCACHE => 'true' ,BLOCKSIZE => '65536 ,REPLICATION ScopE
=> '0'}
3 row(s) in 0.0400 seconds
步骤二十:删除列簇
hbase(main):020:0> alter 'scores',NAME=>'age',METHOD=>'delete'
Updating all regions with the new schema…
1/ 1 regions updated.
Done.
0 row(s)in 2.1600seconds
步骤二十一:删除表
hbase(main):021:0> disable 'scores'
0 row(s)in 2.2930seconds
hbase(main):022:0> drop 'scores'
0 row(s)in 1.2530seconds
hbase( main) :023:0> list
TABLE
0 row(s)in 0.0150 seconds
==>[]
步骤二十二:退出
hbase(main):024:0> quit
[hadoop@master ~]$
步骤二十三:关闭 HBase
#在 master节点关闭 HBase
[hadoop@master ~]$ stop-hbase.sh
#在所有节点关闭 ZooKeeper
[hadoop@master ~]$ zkServer.sh stop
[hadoop@slave1 ~]$ zkServer.sh stop
[hadoop@slave2 ~]$ zkServer.sh stop
#在 master节点关闭 Hadoop
[hadoop@master ~]$ stop-all.sh
九、Sqoop组件
一、传Sqoop软件包并解压改名
下载地址:https://mirror-hk.koddos.net/apache/sqoop/
win+R cmd
[root@master ~]# tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# mv ./sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
二、配置Sqoop
创建Sqoop的配置文件sqoop-env.sh
[root@master ~]# cd /usr/local/src/sqoop/conf/
[root@master conf]# cp sqoop-env-template.sh sqoop-env.sh
修改sqoop-env.sh
[root@master conf]# vi sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/src/hadoop
export HADOOP_MAPRED_HOME=/usr/local/src/hadoop
export HBASE_HOME=/usr/local/src/hbase
export HIVE_HOME=/usr/local/src/hive
配置环境变量
[root@master conf]# vi /etc/profile.d/sqoop.sh
export SQOOP_HOME=/usr/local/src/sqoop
export PATH=${SQOOP_HOME}/bin:$PATH
连接数据库
[root@master conf]# source /etc/profile.d/sqoop.sh
[root@master conf]# cp /root/software/mysql-connector-java-5.1.46.jar /usr/local/src/sqoop/lib/
三、启动sqoop
启动所有进程
[root@master ~]# su - hadoop
Last login: Fri Apr 22 15:05:13 CST 2022 on pts/1
[hadoop@master ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.out
10.10.10.130: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave2.out
10.10.10.129: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-resourcemanager-master.out
10.10.10.130: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave2.out
10.10.10.129: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave1.out
[hadoop@master ~]$ jps
2305 ResourceManager
2565 Jps
1926 NameNode
2136 SecondaryNameNode
测试Sqoop连接MysqL
[hadoop@master ~]$ sqoop list-databases --connect jdbc:MysqL://127.0.0.1:3306 --username root -P
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/04/29 15:16:26 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
22/04/29 15:16:34 INFO manager.MysqLManager: Preparing to use a MysqL streaming resultset.
Fri Apr 29 15:16:34 CST 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MysqL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
information_schema
MysqL
performance_schema
sys
连接hive
[hadoop@master ~]$ cp /usr/local/src/hive/lib/hive-common-2.0.0.jar /usr/local/src/sqoop/lib/
四、Sqoop模板命令
创建MysqL数据库和数据表
[hadoop@master ~]$ MysqL -uroot -p'Password123!'
MysqL: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MysqL monitor. Commands end with ; or \g.
Your MysqL connection id is 7
Server version: 5.7.18 MysqL Community Server (GPL)
copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered Trademark of Oracle Corporation and/or its
affiliates. Other names may be Trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MysqL> create database sample;
Query OK, 1 row affected (0.00 sec)
MysqL> use sample
Database changed
MysqL> create table student(number char(9) primary key,name varchar(10));
Query OK, 0 rows affected (0.01 sec)
MysqL> insert student values('01','zhangsan'),('02','lisi'),('03','wangwu');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
MysqL> select * from student;
+--------+----------+
| number | name |
+--------+----------+
| 01 | zhangsan |
| 02 | lisi |
| 03 | wangwu |
+--------+----------+
3 rows in set (0.00 sec)
MysqL> quit
Bye
创建hive数据库和数据表
[hadoop@master ~]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/hive-jdbc-2.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/src/hive/lib/hive-common-2.0.0.jar!/hive-log4j2.properties
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> use sample;
OK
Time taken: 0.477 seconds
hive> show tables;
OK
student
Time taken: 0.152 seconds, Fetched: 1 row(s)
hive> select * from student;
OK
01|zhangsan NULL
02|lisi NULL
03|wangwu NULL
Time taken: 0.773 seconds, Fetched: 3 row(s)
hive> quit;
在hive中创建sample数据库和student数据表
[hadoop@master ~]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/hive-jdbc-2.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/src/hive/lib/hive-common-2.0.0.jar!/hive-log4j2.properties
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> create database sample;
OK
Time taken: 0.694 seconds
hive> use sample;
OK
Time taken: 0.013 seconds
hive> create table student(number STRING,name STRING);
OK
Time taken: 0.23 seconds
hive> exit;
从MysqL导出数据,导入hive
[hadoop@master ~]$ sqoop import --connect jdbc:MysqL://master:3306/sample --username root --password Password123! --table student --fields-terminated-by '|' --delete-target-dir --num-mappers 1 --hive-import --hive-database sample --hive-table student
从hive导出数据,导入MysqL
[hadoop@master ~]$ MysqL -uroot -pPassword123! -e 'delete from sample.student;'
[hadoop@master ~]$ sqoop export --connect "jdbc:MysqL://master:3306/sample?useUnicode=true&characterEncoding=utf-8" --username root --password Password123! --table student --input-fields-terminated-by '|' --export-dir /user/hive/warehouse/sample.db/student/*
五、Sqoop组件应用
列出MysqL所有数据库
[hadoop@master ~]$ sqoop list-databases --connect jdbc:MysqL://master:3306 --username root --password Password123!
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/04/29 16:44:07 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
22/04/29 16:44:07 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
22/04/29 16:44:07 INFO manager.MysqLManager: Preparing to use a MysqL streaming resultset.
Fri Apr 29 16:44:07 CST 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MysqL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
information_schema
hive
MysqL
performance_schema
sample
sys
连接MysqL并列出sample数据库中的表
[hadoop@master ~]$ sqoop list-tables --connect jdbc:MysqL://master:3306/sample --username root --password Password123!
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/04/29 16:44:44 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
22/04/29 16:44:44 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
22/04/29 16:44:44 INFO manager.MysqLManager: Preparing to use a MysqL streaming resultset.
Fri Apr 29 16:44:44 CST 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MysqL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
student
将关系型数据的表结构复制到hive
[hadoop@master ~]$ sqoop create-hive-table -connect jdbc:MysqL://localhost:3306/sample -table student -username root -password Password123! -hive-table test
从关系型数据库导入文件到hive
[hadoop@master ~]$ sqoop import --connect jdbc:MysqL://master:3306/sample --username root --password Password123! --table student --delete-target-dir --num-mappers 1 --hive-import --hive-database default --hive-table test
将hive中的表数据导入到MysqL中
[hadoop@master ~]$ sqoop export -connect jdbc:MysqL://master:3306/sample -username root -password Password123! -table student --input-fields-terminated-by '\001' -export-dir /user/hibe/warehouse/test
从数据库导出表的数据到HDFS上文件
[hadoop@master ~]$ sqoop import -connect jdbc:MysqL://master:3306/sample -username root -password Password123! -table student --num-mappers 1 -target-dir /user/test
从数据库增量导入表数据到HDFS
[hadoop@master ~]$ MysqL -uroot -pPassword123!
MysqL: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MysqL monitor. Commands end with ; or \g.
Your MysqL connection id is 103
Server version: 5.7.18 MysqL Community Server (GPL)
copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered Trademark of Oracle Corporation and/or its
affiliates. Other names may be Trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MysqL> use sample;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MysqL> insert into student values('04','sss');
Query OK, 1 row affected (0.01 sec)
MysqL> insert into student values('05','ss2');
Query OK, 1 row affected (0.00 sec)
MysqL> insert into student values('06','ss3');
Query OK, 1 row affected (0.01 sec)
MysqL> alter table student modify column number int;
Query OK, 3 rows affected (0.04 sec)
Records: 3 Duplicates: 0 Warnings: 0
MysqL> exit;
Bye
[hadoop@master ~]$ sqoop import -connect jdbc:MysqL://master:3306/sample -username root -password Password123! -table student --num-mappers 1 -target-dir /user/test -check-column number -incremental append -last-value 0
[hadoop@master ~]$ hdfs dfs -cat /user/test/part-m-00001
十、flume组件
一、下载并传入包
下载地址:https://archive.apache.org/dist/flume/1.6.0/
二、部署flume组件
#解压包
[root@master ~]# tar xf apache-flume-1.6.0-bin.tar.gz -C /usr/local/src/
#进入目录
[root@master ~]# cd /usr/local/src/
#修改名字为flume
[root@master src]# mv apache-flume-1.6.0-bin/ flume
#权限
[root@master src]# chown -R hadoop.hadoop /usr/local/src/
#创建环境变量
[root@master src]# vi /etc/profile.d/flume.sh
export FLUME_HOME=/usr/local/src/flume
export PATH=${FLUME_HOME}/bin:$PATH
查看是否有路径
[root@master src]# su - hadoop
Last login: Fri Apr 29 16:36:50 CST 2022 on pts/1
[hadoop@master ~]$ echo $PATH
/home/hadoop/.local/bin:/home/hadoop/bin:/usr/local/src/zookeeper/bin:/usr/local/src/sqoop/bin:/usr/local/src/hive/bin:/usr/local/src/hbase/bin:/usr/local/src/jdk/bin:/usr/local/src/hadoop/bin:/usr/local/src/hadoop/sbin:/usr/local/src/flume/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin
#有看到flume的安装路径则表示没问题
三、配置flume
#修改配置文件
[hadoop@master ~]$ vi /usr/local/src/hbase/conf/hbase-env.sh
#export HBASE_CLAsspATH=/usr/local/src/hadoop/etc/hadoop/ 注释这一行
#进入目录
[hadoop@master ~]$ cd /usr/local/src/flume/conf/
#复制并改名为flume-env.sh
[hadoop@master conf]$ cp flume-env.sh.template flume-env.sh
#修改配置文件
[hadoop@master conf]$ vi flume-env.sh
export JAVA_HOME=/usr/local/src/jdk
#启动所有组件
[hadoop@master conf]$ start-all.sh
#查看版本
[hadoop@master conf]$ flume-ng version
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f
四、使用flume发送接受信息
#进入目录
[hadoop@master conf]$ cd /usr/local/src/flume/
#写入数据
[hadoop@master flume]$ vi /usr/local/src/flume/simple-hdfs-flume.conf
#a1是agent名,r1,k1,c1是a1的三个组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#设置r1源文件的类型、路径和文件头属性
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/usr/local/src/hadoop/logs/
a1.sources.r1.fileHeader=true
#设置k1目标存储器属性
a1.sinks.k1.type=hdfs #目标存储器类型hdfs
a1.sinks.k1.hdfs.path=hdfs://master:9000/tmp/flume #目标存储位置
a1.sinks.k1.hdfs.rollsize=1048760 #临时文件达1048760 bytes时,滚动形成目标文件
a1.sinks.k1.hdfs.rollCount=0 #表示不根据events数量1来滚动形成目标文件
a1.sinks.k1.hdfs.rollInterval=900 #间隔900秒将临时文件滚动形成目标文件
a1.sinks.k1.hdfs.useLocalTimeStamp=true #使用本地时间戳
#设置c1暂存容器属性
a1.channels.c1.type=file #使用文件作为暂存容器
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#使用c1作为源和目标数据的传输通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#运行
[hadoop@master flume]$ flume-ng agent --conf-file simple-hdfs-flume.conf --name a1
查看flume传输到hdfs的文件
[hadoop@master flume]$ hdfs dfs -ls /tmp/flume
十三、大数据平台监控
一、监控大数据平台
查看Linux系统信息
[root@master ~]# uname -a
Linux master 4.18.0-373.el8.x86_64 #1 SMP Tue Mar 22 15:11:47 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
查看硬盘信息
查看分区
[root@master ~]# fdisk -l
disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
disklabel type: dos
disk identifier: 0x3f653cbf
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
/dev/sda2 2099200 41943039 39843840 19G 8e Linux LVM
disk /dev/mapper/cs-root: 17 GiB, 18249416704 bytes, 35643392 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
disk /dev/mapper/cs-swap: 2 GiB, 2147483648 bytes, 4194304 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
查看所有交换分区
[root@master ~]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 2097148 0 -2
查看文件系统占比
[root@master ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 370M 0 370M 0% /dev
tmpfs 389M 0 389M 0% /dev/shm
tmpfs 389M 11M 379M 3% /run
tmpfs 389M 0 389M 0% /sys/fs/cgroup
/dev/mapper/cs-root 17G 5.3G 12G 32% /
/dev/sda1 1014M 210M 805M 21% /boot
tmpfs 78M 0 78M 0% /run/user/0
查看网络IP
[root@master ~]# ifconfig
ens33: flags=4163<UP,broADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.10.10.128 netmask 255.255.255.0 broadcast 10.10.10.255
inet6 fe80::20c:29ff:fe4f:1938 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4f:19:38 txqueuelen 1000 (Ethernet)
RX packets 326 bytes 29201 (28.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 216 bytes 24513 (23.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 8 bytes 720 (720.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 720 (720.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
查看所有监听端口
[root@master ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 958/sshd
tcp6 0 0 :::3306 :::* LISTEN 1247/MysqLd
tcp6 0 0 :::22 :::* LISTEN 958/sshd
查看所有已建立的连接
[hadoop@master ~]$ netstat -antp
(No info Could be read for "-p": geteuid()=1000 but you should be root.)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 52 10.10.10.128:22 10.10.10.1:7076 ESTABLISHED -
tcp6 0 0 :::3306 :::* LISTEN -
tcp6 0 0 :::22 :::* LISTEN -
实时显示进程状态
[root@master ~]# top
top - 17:07:10 up 10 min, 1 user, load average: 0.00, 0.03, 0.04
Tasks: 169 total, 1 running, 168 sleeping, 0 stopped, 0 zombie
%cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.1 s
MiB Mem : 777.4 total, 116.6 free, 401.0 used, 259.7 buff
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 245.6 avai
PID USER PR NI VIRT RES SHR S %cpu %MEM
313 root 0 -20 0 0 0 I 0.3 0.0
960 root 20 0 497104 29348 15336 S 0.3 3.7
1620 root 20 0 153500 5356 4092 S 0.3 0.7
1 root 20 0 174916 13432 8460 S 0.0 1.7
2 root 20 0 0 0 0 S 0.0 0.0
3 root 0 -20 0 0 0 I 0.0 0.0
4 root 0 -20 0 0 0 I 0.0 0.0
6 root 0 -20 0 0 0 I 0.0 0.0
8 root 20 0 0 0 0 I 0.0 0.0
查看cpu信息
[root@master ~]# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 165
model name : Intel(R) Core(TM) i3-10100 cpu @ 3.60GHz
stepping : 3
microcode : 0xcc
cpu MHz : 3600.005
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dNowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xsaves arat md_clear flush_l1d arch_capabilities
bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs itlb_multihit
bogomips : 7200.01
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 165
model name : Intel(R) Core(TM) i3-10100 cpu @ 3.60GHz
stepping : 3
microcode : 0xcc
cpu MHz : 3600.005
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 1
cpu cores : 4
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dNowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xsaves arat md_clear flush_l1d arch_capabilities
bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs itlb_multihit
bogomips : 7200.01
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 165
model name : Intel(R) Core(TM) i3-10100 cpu @ 3.60GHz
stepping : 3
microcode : 0xcc
cpu MHz : 3600.005
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 2
cpu cores : 4
apicid : 2
initial apicid : 2
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dNowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xsaves arat md_clear flush_l1d arch_capabilities
bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs itlb_multihit
bogomips : 7200.01
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 165
model name : Intel(R) Core(TM) i3-10100 cpu @ 3.60GHz
stepping : 3
microcode : 0xcc
cpu MHz : 3600.005
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 3
cpu cores : 4
apicid : 3
initial apicid : 3
fpu : yes
fpu_exception : yes
cpuid level : 22
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dNowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xsaves arat md_clear flush_l1d arch_capabilities
bugs : spectre_v1 spectre_v2 spec_store_bypass swapgs itlb_multihit
bogomips : 7200.01
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
查看内存信息
[root@master ~]# cat /proc/meminfo
MemTotal: 796056 kB
MemFree: 120252 kB
MemAvailable: 252360 kB
Buffers: 4204 kB
Cached: 227492 kB
SwapCached: 0 kB
Active: 83512 kB
Inactive: 407888 kB
Active(anon): 1764 kB
Inactive(anon): 268576 kB
Active(file): 81748 kB
Inactive(file): 139312 kB
Unevictable: 0 kB
mlocked: 0 kB
SwapTotal: 2097148 kB
SwapFree: 2097148 kB
Dirty: 0 kB
Writeback: 0 kB
AnonPages: 259716 kB
Mapped: 95376 kB
Shmem: 10636 kB
KReclaimable: 34272 kB
Slab: 83828 kB
SReclaimable: 34272 kB
SUnreclaim: 49556 kB
KernelStack: 5456 kB
PageTables: 7168 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 2495176 kB
Committed_AS: 864108 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
Percpu: 76288 kB
HardwareCorrupted: 0 kB
AnonHugePages: 190464 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
FileHugePages: 0 kB
FilePmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 124800 kB
DirectMap2M: 923648 kB
DirectMap1G: 0 kB
查看Hadoop状态
#切换Hadoop用户
[root@master ~]# su - hadoop
Last login: Fri May 13 17:05:40 CST 2022 on pts/0
#切换Hadoop安装目录
[hadoop@master ~]$ cd /usr/local/src/hadoop/
#启动Hadoop
[hadoop@master hadoop]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.out
10.10.10.129: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave1.out
10.10.10.130: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: secondarynamenode running as process 1989. Stop it first.
starting yarn daemons
starting resourcemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-resourcemanager-master.out
10.10.10.130: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave2.out
10.10.10.129: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave1.out
#关闭Hadoop
[hadoop@master hadoop]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
10.10.10.129: stopping datanode
10.10.10.130: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: no secondarynamenode to stop
stopping yarn daemons
stopping resourcemanager
10.10.10.129: stopping nodemanager
10.10.10.130: stopping nodemanager
no proxyserver to stop
二、监控大数据平台资源状态
查看YARN状态
#切换Hadoop安装目录
[hadoop@master ~]$ cd /usr/local/src/hadoop/
#启动Zookeeper
[hadoop@master hadoop]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#启动Hadoop
[hadoop@master hadoop]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.out
10.10.10.130: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave2.out
10.10.10.129: starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-resourcemanager-master.out
10.10.10.129: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave1.out
10.10.10.130: starting nodemanager, logging to /usr/local/src/hadoop/logs/yarn-hadoop-nodemanager-slave2.out
#JPS查看有NodeManager和ResourceManager进程则表示YARN成功
[hadoop@master hadoop]$ jps
3539 ResourceManager
2984 QuorumPeerMain
3161 NameNode
3371 SecondaryNameNode
3803 Jps
查看HDFS状态
#切换Hadoop安装目录
[hadoop@master ~]$ cd /usr/local/src/hadoop/
#查看HDFS目录
[hadoop@master hadoop]$ ./bin/hdfs dfs -ls /
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2022-04-15 17:30 /hbase
drwxr-xr-x - hadoop supergroup 0 2022-04-15 14:53 /input
drwxr-xr-x - hadoop supergroup 0 2022-04-15 14:53 /output
drwx------ - hadoop supergroup 0 2022-05-06 17:31 /tmp
drwxr-xr-x - hadoop supergroup 0 2022-04-29 17:06 /user
#查看HDFS报告
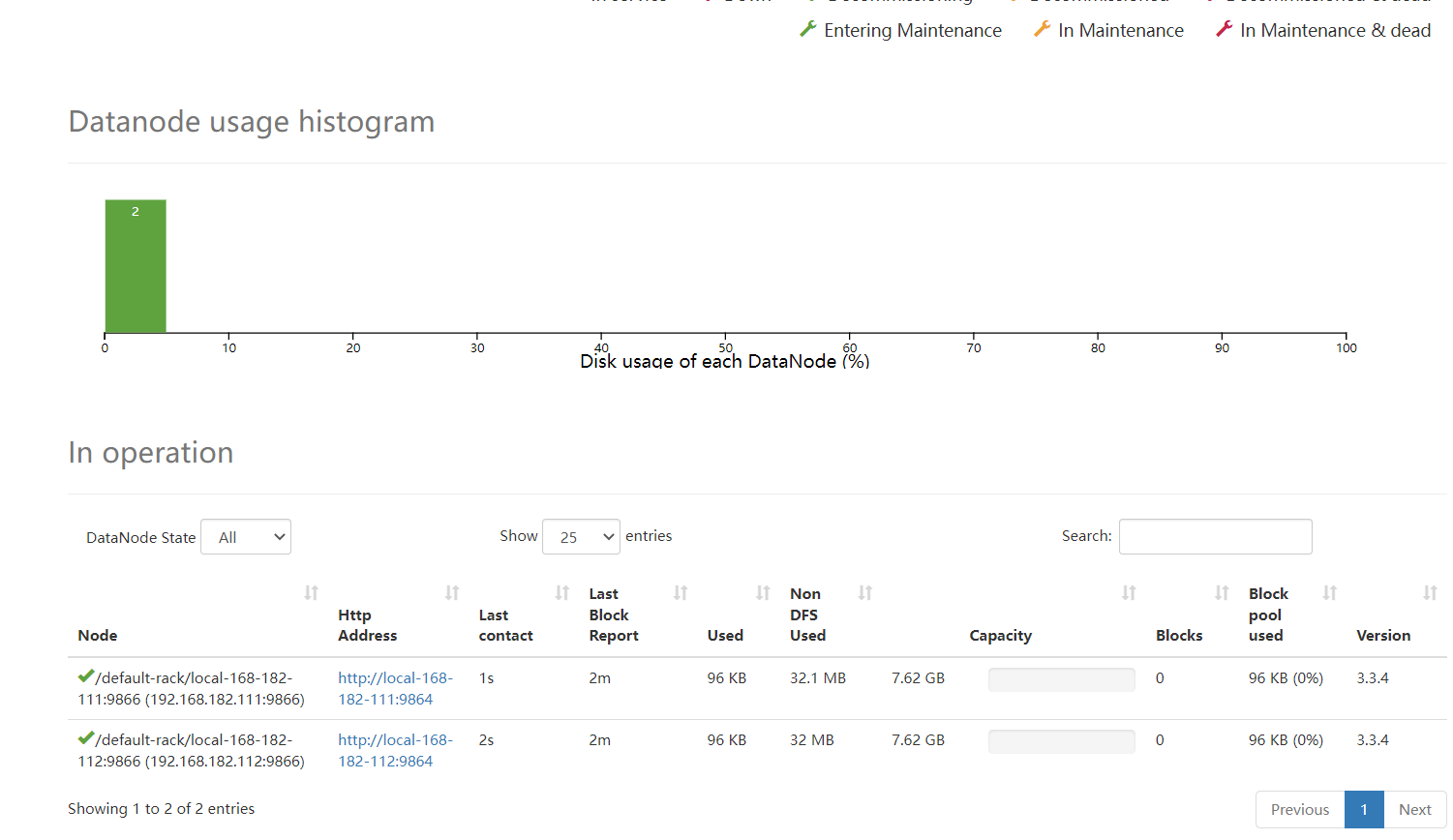
[hadoop@master hadoop]$ bin/hdfs dfsadmin -report
Configured Capacity: 36477861888 (33.97 GB)
Present Capacity: 30300819456 (28.22 GB)
DFS Remaining: 30297894912 (28.22 GB)
DFS Used: 2924544 (2.79 MB)
DFS Used%: 0.01%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 10.10.10.129:50010 (slave1)
Hostname: slave1
Decommission Status : normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 1462272 (1.39 MB)
Non DFS Used: 3130793984 (2.92 GB)
DFS Remaining: 15106674688 (14.07 GB)
DFS Used%: 0.01%
DFS Remaining%: 82.83%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri May 13 17:23:05 CST 2022
Name: 10.10.10.130:50010 (slave2)
Hostname: slave2
Decommission Status : normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 1462272 (1.39 MB)
Non DFS Used: 3046248448 (2.84 GB)
DFS Remaining: 15191220224 (14.15 GB)
DFS Used%: 0.01%
DFS Remaining%: 83.29%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri May 13 17:23:05 CST 2022
#查看HDFS空间情况
[hadoop@master hadoop]$ hdfs dfs -df /
Filesystem Size Used Available Use%
hdfs://master:9000 36477861888 2924544 30297894912 0%
查看HBase状态
启动HBase
#进入HBase安装目录
[hadoop@master ~]$ cd /usr/local/src/hbase/
#查看版本
[hadoop@master hbase]$ hbase version
HBase 1.2.1
Source code repository git://asf-dev/home/busbey/projects/hbase revision=8d8a7107dc4ccbf36a92f64675dc60392f85c015
Compiled by busbey on Wed Mar 30 11:19:21 CDT 2016
From source with checksum f4bb4a14bb4e0b72b46f729dae98a772
#结果显示 HBase1.2.1,说明 HBase 正在运行,版本号为 1.2.1。
#如果没有启动,则执行命令 start-hbase.sh 启动 HBase。
[hadoop@master hbase]$ start-hbase.sh
slave1: starting zookeeper, logging to /usr/local/src/hbase/logs/hbase-hadoop-zookeeper-slave1.out
slave2: starting zookeeper, logging to /usr/local/src/hbase/logs/hbase-hadoop-zookeeper-slave2.out
master: starting zookeeper, logging to /usr/local/src/hbase/logs/hbase-hadoop-zookeeper-master.out
starting master, logging to /usr/local/src/hbase/logs/hbase-hadoop-master-master.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
10.10.10.129: starting regionserver, logging to /usr/local/src/hbase/logs/hbase-hadoop-regionserver-slave1.out
10.10.10.130: starting regionserver, logging to /usr/local/src/hbase/logs/hbase-hadoop-regionserver-slave2.out
10.10.10.130: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
10.10.10.130: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
10.10.10.129: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
10.10.10.129: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
[hadoop@master hbase]$ hbase version
HBase 1.2.1
Source code repository git://asf-dev/home/busbey/projects/hbase revision=8d8a7107dc4ccbf36a92f64675dc60392f85c015
Compiled by busbey on Wed Mar 30 11:19:21 CDT 2016
From source with checksum f4bb4a14bb4e0b72b46f729dae98a772
查看HBase版本信息
#进入HBase交互界面
[hadoop@master hbase]$ hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.1, r8d8a7107dc4ccbf36a92f64675dc60392f85c015, Wed Mar 30 11:19:21 CDT 2016
hbase(main):001:0>
#查看版本
hbase(main):001:0> version
1.2.1, r8d8a7107dc4ccbf36a92f64675dc60392f85c015, Wed Mar 30 11:19:21 CDT 2016
查询HBase状态
hbase(main):002:0> status
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
查看Hive状态
启动Hive
[hadoop@master ~]$ cd /usr/local/src/hive/
[hadoop@master hive]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/hive-jdbc-2.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/src/hive/lib/hive-common-2.0.0.jar!/hive-log4j2.properties
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
Hive操作基本命令
查看数据库
hive> show databases;
OK
default
sample
Time taken: 0.628 seconds, Fetched: 2 row(s)
查看default数据库所有表
hive> use default;
OK
Time taken: 0.025 seconds
hive> show tables;
OK
test
Time taken: 0.05 seconds, Fetched: 1 row(s)
创建表stu,表的id为整数型,name为字符型
hive> create table stu(id int,name string);
OK
Time taken: 0.382 seconds
为表stu插入一条信息,id号为001,name为张三
hive> insert into stu values(1001,"zhangsan");
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20220517143507_8a20256e-ac94-49f9-8c4c-93a86d341936
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1652768861914_0001, Tracking URL = http://master:8088/proxy/application_1652768861914_0001/
Kill Command = /usr/local/src/hadoop/bin/hadoop job -kill job_1652768861914_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-05-17 14:35:44,996 Stage-1 map = 0%, reduce = 0%
2022-05-17 14:35:50,379 Stage-1 map = 100%, reduce = 0%, Cumulative cpu 2.58 sec
MapReduce Total cumulative cpu time: 2 seconds 580 msec
Ended Job = job_1652768861914_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://master:9000/user/hive/warehouse/stu/.hive-staging_hive_2022-05-17_14-35-35_416_5475258551476738478-1/-ext-10000
Loading data to table default.stu
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative cpu: 2.58 sec HDFS Read: 4138 HDFS Write: 81 SUCCESS
Total MapReduce cpu Time Spent: 2 seconds 580 msec
OK
Time taken: 17.501 seconds
插入数据后查看表的信息
hive> show tables;
OK
stu
test
values__tmp__table__1
Time taken: 0.035 seconds, Fetched: 3 row(s)
查看表stu结构
hive> desc stu;
OK
id int
name string
Time taken: 0.044 seconds, Fetched: 2 row(s)
查看表stu的内容
hive> select * from stu;
OK
1001 zhangsan
Time taken: 0.119 seconds, Fetched: 1 row(s)
查看文件系统和历史命令
查看本地文件系统
hive> ! ls /usr/local/src;
flume
hadoop
hbase
hive
jdk
sqoop
zookeeper
查看HDFS文件系统
hive> dfs -ls /;
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2022-05-13 17:29 /hbase
drwxr-xr-x - hadoop supergroup 0 2022-04-15 14:53 /input
drwxr-xr-x - hadoop supergroup 0 2022-04-15 14:53 /output
drwx------ - hadoop supergroup 0 2022-05-06 17:31 /tmp
drwxr-xr-x - hadoop supergroup 0 2022-04-29 17:06 /user
查看Hive输入的所有历史命令
[hadoop@master hive]$ cd /home/hadoop/
[hadoop@master ~]$ cat .hivehistory
quit
exit
create database sample;
use sample;
create table student(number STRING,name STRING);
exit;
use sample;
show tables;
select * from student;
quit;
clear
exit;
show databases;
use default;
show tables;
create table stu(id int,name string);
insert into stu values (1001,"zhangsan")
use default;
show tables;
insert into stu values(1001,"zhangsan");
show tables;
desc stu;
select * from stu;
! ls /usr/local/src;
dfs -ls /;
三、监控大数据平台服务状态
查看ZooKeeper状态
查看ZooKeeper状态
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
#Mode: follower表示ZooKeeper的跟随者
查看运行进程
[hadoop@master ~]$ jps
1968 NameNode
2179 SecondaryNameNode
3654 QuorumPeerMain
3752 Jps
2350 ResourceManager
#QuorumPeerMain已启动
连接ZooKeeper服务
[hadoop@master ~]$ zkCli.sh
Connecting to localhost:2181
2022-05-17 14:44:43,564 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.8--1, built on 02/06/2016 03:18 GMT
2022-05-17 14:44:43,566 [myid:] - INFO [main:Environment@100] - Client environment:host.name=master
2022-05-17 14:44:43,566 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_152
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/local/src/jdk/jre
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/src/zookeeper/bin/../build/classes:/usr/local/src/zookeeper/bin/../build/lib/*.jar:/usr/local/src/zookeeper/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/local/src/zookeeper/bin/../lib/slf4j-api-1.6.1.jar:/usr/local/src/zookeeper/bin/../lib/netty-3.7.0.Final.jar:/usr/local/src/zookeeper/bin/../lib/log4j-1.2.16.jar:/usr/local/src/zookeeper/bin/../lib/jline-0.9.94.jar:/usr/local/src/zookeeper/bin/../zookeeper-3.4.8.jar:/usr/local/src/zookeeper/bin/../src/java/lib/*.jar:/usr/local/src/zookeeper/bin/../conf:
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2022-05-17 14:44:43,568 [myid:] - INFO [main:Environment@100] - Client environment:os.version=4.18.0-373.el8.x86_64
2022-05-17 14:44:43,569 [myid:] - INFO [main:Environment@100] - Client environment:user.name=hadoop
2022-05-17 14:44:43,569 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/hadoop
2022-05-17 14:44:43,569 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/hadoop
2022-05-17 14:44:43,570 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@69d0a921
Welcome to ZooKeeper!
2022-05-17 14:44:43,592 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1032] - opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unkNown error)
jline support is enabled
2022-05-17 14:44:43,634 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@876] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2022-05-17 14:44:43,646 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x180d0c0ef7f0000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
使用Watch监听/hbase目录
[zk: localhost:2181(CONNECTED) 0] get /hbase 1
cZxid = 0x400000002
ctime = Fri May 13 17:30:40 CST 2022
mZxid = 0x400000002
mtime = Fri May 13 17:30:40 CST 2022
pZxid = 0x500000004
cversion = 19
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 13
[zk: localhost:2181(CONNECTED) 1] set /hbase value-ipdate
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/hbase
cZxid = 0x400000002
ctime = Fri May 13 17:30:40 CST 2022
mZxid = 0x500000009
mtime = Tue May 17 14:47:48 CST 2022
pZxid = 0x500000004
cversion = 19
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 12
numChildren = 13
[zk: localhost:2181(CONNECTED) 2] get /hbase
value-ipdate
cZxid = 0x400000002
ctime = Fri May 13 17:30:40 CST 2022
mZxid = 0x500000009
mtime = Tue May 17 14:47:48 CST 2022
pZxid = 0x500000004
cversion = 19
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 12
numChildren = 13
[zk: localhost:2181(CONNECTED) 3] quit
Quitting...
2022-05-17 14:46:43,808 [myid:] - INFO [main:ZooKeeper@684] - Session: 0x180d0c0ef7f0001 closed
2022-05-17 14:46:43,809 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@519] - EventThread shut down for session: 0x180d0c0ef7f0001
查看Sqoop状态
查询Sqoop版本号
[hadoop@master ~]$ cd /usr/local/src/sqoop/
[hadoop@master sqoop]$ ./bin/sqoop-version
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/05/17 14:47:38 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
测试Sqoop连接数据库
[hadoop@master ~]$ cd /usr/local/src/sqoop/
[hadoop@master sqoop]$ bin/sqoop list-databases --connect jdbc:MysqL://master:3306/ --username root --password Password123!
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/05/17 14:50:51 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
22/05/17 14:50:51 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
22/05/17 14:50:51 INFO manager.MysqLManager: Preparing to use a MysqL streaming resultset.
Tue May 17 14:50:51 CST 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MysqL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
information_schema
hive
MysqL
performance_schema
sample
sys
查看Sqoop 帮助,代表Sqoop启动成功
[hadoop@master sqoop]$ sqoop help
Warning: /usr/local/src/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/src/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
22/05/17 14:51:41 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table deFinition into Hive
eval Evaluate a sql statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version display version information
See 'sqoop help COMMAND' for information on a specific command.
| 序号 | 命令 | 功能 |
|---|---|---|
| 1 | import | 将数据导入到集群 |
| 2 | export | 讲集群数据导出 |
| 3 | codegen | 生成与数据库记录交互的代码 |
| 4 | create-hive-table | 创建Hive表 |
| 5 | eval | 查看sql执行结果 |
| 6 | import-all-tables | 导入某个数据库下所有表到HDFS中 |
| 7 | job | 生成一个job |
| 8 | list-databases | 列出所有数据库名 |
| 9 | list-tables | 列出某个数据库下所有的表 |
| 10 | merge | 将HDFS中不同目录下数据合在一起,并存放在指定的目录中 |
| 11 | metastore | 记录Sqoop job的元数据信息,如果不启动Metasrore实例,则默认的元数据存储目录为:~/.sqoop |
| 12 | help | 打印Sqoop帮助信息 |
| 13 | version | 打印Sqoop版本信息 |
查看Flume状态
检查Flume安装是否成功
[hadoop@master sqoop]$ cd /usr/local/src/flume/
[hadoop@master flume]$ flume-ng version
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f
添加example.conf到/usr/local/src/flume
[hadoop@master flume]$ vi /usr/local/src/flume/example.conf
#a1是agent名,r1,k1,c1是a1的三个组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#设置r1源文件的类型、路径和文件头属性
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/usr/local/src/hadoop/logs/
a1.sources.r1.fileHeader=true
#设置k1目标存储器属性
a1.sinks.k1.type=hdfs #目标存储器类型hdfs
a1.sinks.k1.hdfs.path=hdfs://master:9000/tmp/flume #目标存储位置
a1.sinks.k1.hdfs.rollsize=1048760 #临时文件达1048760 bytes时,滚动形成目标文件
a1.sinks.k1.hdfs.rollCount=0 #表示不根据events数量1来滚动形成目标文件
a1.sinks.k1.hdfs.rollInterval=900 #间隔900秒将临时文件滚动形成目标文件
a1.sinks.k1.hdfs.useLocalTimeStamp=true #使用本地时间戳
#设置c1暂存容器属性
a1.channels.c1.type=file #使用文件作为暂存容器
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#使用c1作为源和目标数据的传输通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动Flume Agent a1日志控制台
[hadoop@master flume]$ /usr/local/src/flume/bin/flume-ng agent --conf ./conf/ --conf-file ./example.conf --name a1 -Dflume.root.logger=INFO,console
查看结果
[hadoop@master flume]$ hdfs dfs -lsr /flume
-rw-r--r--2 hadoop supergroup 1300 2022-05-17
:43 /tmp/flume/FlumeData.1651819407082
-rw-r--r--2 hadoop supergroup 2748 2022-05-17
:43 /tmp/flume/FlumeData.1651819407083
-rw-r--r--2 hadoop supergroup 2163 2022-05-17
:43 /tmp/flume/FlumeData.1651819407084