问题描述
- 报错1
hive> show databases;
OK
Failed with exception java.io.IOException:java.lang.RuntimeException: Error in configuring object
Time taken: 0.474 seconds
- 解决方案
# 进入hadoop日志目录
cd /usr/local/software/hadoop-2.9.2/logs
# 查看
cat yarn-root-nodemanager-slave1.log
# 报错详情
2023-12-26 17:58:44,951 WARN org.mortbay.log: Failed to read file: /usr/local/software/hadoop-2.9.2/share/hadoop/common/hadoop-lzo-0.4.20.jar
java.util.zip.ZipException: zip file is empty
at java.util.zip.ZipFile.open(Native Method)
at java.util.zip.ZipFile.<init>(ZipFile.java:225)
at java.util.zip.ZipFile.<init>(ZipFile.java:155)
at java.util.jar.JarFile.<init>(JarFile.java:166)
at java.util.jar.JarFile.<init>(JarFile.java:130)
at org.mortbay.jetty.webapp.TagLibConfiguration.configureWebApp(TagLibConfiguration.java:174)
at org.mortbay.jetty.webapp.WebAppContext.startContext(WebAppContext.java:1279)
at org.mortbay.jetty.handler.ContextHandler.doStart(ContextHandler.java:518)
at org.mortbay.jetty.webapp.WebAppContext.doStart(WebAppContext.java:499)
at org.mortbay.component.AbstractLifeCycle.start(AbstractLifeCycle.java:50)
at org.mortbay.jetty.handler.HandlerCollection.doStart(HandlerCollection.java:152)
at org.mortbay.jetty.handler.ContextHandlerCollection.doStart(ContextHandlerCollection.java:156)
at org.mortbay.component.AbstractLifeCycle.start(AbstractLifeCycle.java:50)
at org.mortbay.jetty.handler.HandlerWrapper.doStart(HandlerWrapper.java:130)
at org.mortbay.jetty.Server.doStart(Server.java:224)
at org.mortbay.component.AbstractLifeCycle.start(AbstractLifeCycle.java:50)
at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:952)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:408)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:397)
at org.apache.hadoop.yarn.server.nodemanager.webapp.WebServer.serviceStart(WebServer.java:101)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:845)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:912)
# 进入如下目录查看hadoop-lzo-0.4.20.jar
cd /usr/local/software/hadoop-2.9.2/share/hadoop/common
[root@slave1 common]# ll
总用量 6572
-rw-r--r--. 1 501 dialout 3906902 11月 14 2018 hadoop-common-2.9.2.jar
-rw-r--r--. 1 501 dialout 2619447 11月 14 2018 hadoop-common-2.9.2-tests.jar
-rw-r--r--. 1 root root 0 12月 25 20:44 hadoop-lzo-0.4.20.jar
-rw-r--r--. 1 501 dialout 188721 11月 13 2018 hadoop-nfs-2.9.2.jar
drwxr-xr-x. 2 501 dialout 4096 11月 13 2018 jdiff
drwxr-xr-x. 2 501 dialout 4096 11月 13 2018 lib
drwxr-xr-x. 2 501 dialout 89 11月 14 2018 sources
drwxr-xr-x. 2 501 dialout 27 11月 13 2018 templates
# 进入如下目录查看hadoop-lzo-0.4.20.jar,也是为0
cd /usr/local/software/hive-2.3.9/lib
# 将hadoop-lzo-0.4.20.jar重新上传到这2个目录
查看详情
cp hadoop-lzo-0.4.20.jar ${HIVE_HOME}/lib
hive> add jar /usr/local/software/hive-2.3.9/lib/hive-hcatalog-core-2.3.9.jar;
Added [/usr/local/software/hive-2.3.9/lib/hive-hcatalog-core-2.3.9.jar] to class path
Added resources: [/usr/local/software/hive-2.3.9/lib/hive-hcatalog-core-2.3.9.jar]
# core-site.xml删除有关lzo的相关配置
<!--
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
-->
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
# mapred-site.xml配置文件改为false,都走集群模式
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>false</value>
</property>
- 错误2
hive> insert into huanhuan values(1,'haoge');
Query ID = root_20231225231022_87127669-cba4-44ce-b2ce-82e41ad90edc
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create spark client.)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create spark client.
- 解决方案
# 查看日志
cat /tmp/root/hive.log
# 日志详情
Possible reasons include network issues, errors in remote driver or the cluster has no available resources, etc.
Please check YARN or Spark driver's logs for further information.
java.util.concurrent.ExecutionException: java.util.concurrent.TimeoutException: Timed out waiting for client connection.
at io.netty.util.concurrent.AbstractFuture.get(AbstractFuture.java:41) ~[netty-all-4.0.52.Final.jar:4.0.52.Final]
at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:109) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:80) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:101) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:97) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:73) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:62) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:126) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:103) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2183) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1839) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1526) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227) ~[hive-exec-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233) ~[hive-cli-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184) ~[hive-cli-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403) ~[hive-cli-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821) ~[hive-cli-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759) ~[hive-cli-2.3.9.jar:2.3.9]
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686) ~[hive-cli-2.3.9.jar:2.3.9]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_181]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_181]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_181]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_181]
at org.apache.hadoop.util.RunJar.run(RunJar.java:244) ~[hadoop-common-2.9.2.jar:?]
at org.apache.hadoop.util.RunJar.main(RunJar.java:158) ~[hadoop-common-2.9.2.jar:?]
# 针对上面的问题配置spark-defaults.conf中的spark.executor.memory和spark.driver.memory后仍然报错
# 浏览器访问hadoop-yarn
http://192.168.128.103:8088/cluster
# 查看具体错误

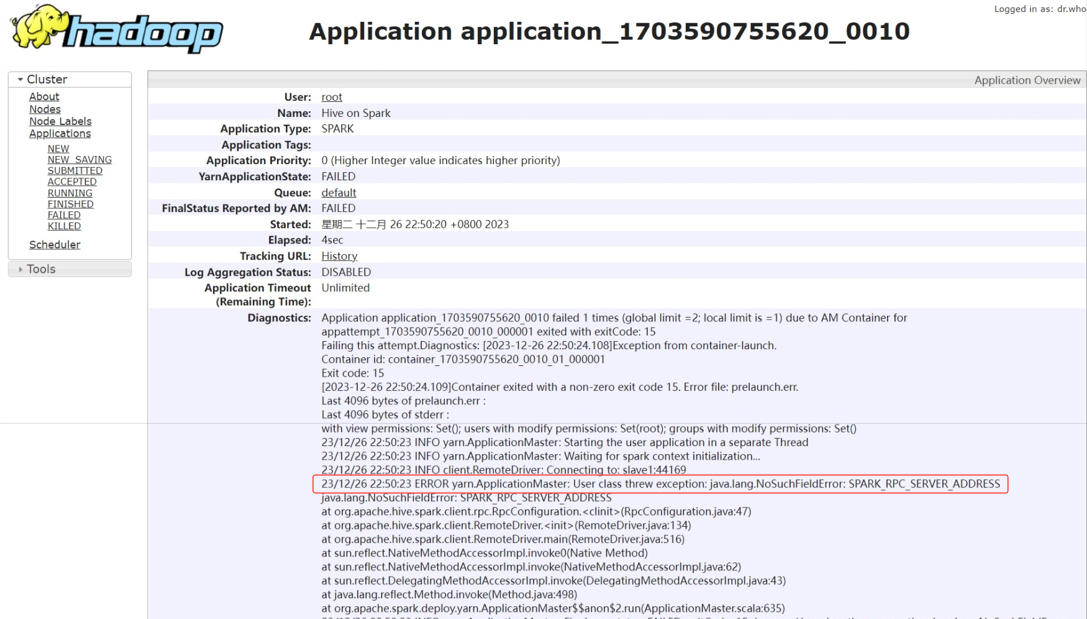
[root@slave1 jars]# pwd
/usr/local/software/spark-2.2.0/jars
[root@slave1 jars]# ll hive*
-rw-r--r--. 1 500 500 138464 7月 1 2017 hive-beeline-1.2.1.spark2.jar
-rw-r--r--. 1 500 500 40817 7月 1 2017 hive-cli-1.2.1.spark2.jar
-rw-r--r--. 1 500 500 11498852 7月 1 2017 hive-exec-1.2.1.spark2.jar
-rw-r--r--. 1 500 500 100680 7月 1 2017 hive-jdbc-1.2.1.spark2.jar
-rw-r--r--. 1 500 500 5505200 7月 1 2017 hive-metastore-1.2.1.spark2.jar
[root@slave1 jars]# ll spark-hive*
-rw-r--r--. 1 500 500 1225322 7月 1 2017 spark-hive_2.11-2.2.0.jar
-rw-r--r--. 1 500 500 1802350 7月 1 2017 spark-hive-thriftserver_2.11-2.2.0.jar
# 删除这几个jar
[root@slave1 jars]# rm -rf hive-beeline-1.2.1.spark2.jar
[root@slave1 jars]# rm -rf hive-cli-1.2.1.spark2.jar
[root@slave1 jars]# rm -rf hive-exec-1.2.1.spark2.jar
[root@slave1 jars]# rm -rf hive-jdbc-1.2.1.spark2.jar
[root@slave1 jars]# rm -rf hive-metastore-1.2.1.spark2.jar
[root@slave1 jars]# rm -rf spark-hive_2.11-2.2.0.jar
[root@slave1 jars]# rm -rf spark-hive-thriftserver_2.11-2.2.0.jar
# 删除hdfs中复制的,重新复制到hdfs
hdfs dfs -rm -r /spark/hive-jars
hdfs dfs -mkdir /spark/hive-jars
hadoop fs -put /usr/local/software/spark-2.2.0/jars/* /spark/hive-jars
hdfs dfs -ls -R /spark/hive-jars/
查看详情
vim /usr/local/software/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>20480</value>
</property>
cd cd /usr/local/software/spark-2.2.0/conf/
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
cp spark-defaults.conf /usr/local/software/hive-2.3.9/conf/
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://slave1:9000/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
hadoop fs -mkdir /spark-history
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>12288</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>12288</value>
</property>
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://slave1:9000/spark-history
spark.executor.memory 2g # 堆内内存,扩大到2g
spark.driver.memory 1g # 运行内存
# hive-site.xml
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>100000ms</value>
</property>
<property>
<name>spark.home</name>
<value>/user/local/spark/spark</value>
</property>
- 报错3
hive (edu)> insert into huanhuan values(1,'haoge');
Query ID = root_20231226234648_2eace6ed-643a-49a3-b06c-5e42ad220821
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 9679cc1e-3e35-4e4f-865b-e2df9f3b9bab
Job failed with java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec not found
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. java.io.IOException: java.util.concurrent.ExecutionException: java.io.IOException: Cannot create an instance of InputFormat class org.apache.hadoop.mapred.TextInputFormat as specified in mapredWork!
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:519)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:194)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:252)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:250)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:250)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1.apply(AsyncRDDActions.scala:127)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1.apply(AsyncRDDActions.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.AsyncRDDActions.foreachAsync(AsyncRDDActions.scala:125)
at org.apache.spark.api.java.JavaRDDLike$class.foreachAsync(JavaRDDLike.scala:732)
at org.apache.spark.api.java.AbstractJavaRDDLike.foreachAsync(JavaRDDLike.scala:45)
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient$JobStatusJob.call(RemoteHiveSparkClient.java:351)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:358)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:323)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
- 解决方案
# 将hadoop-lzo-0.4.20.jar移动到spark/jars
cp hadoop-lzo-0.4.20.jar /usr/local/software/spark-2.2.0/jars/
# 将hadoop-lzo-0.4.20.jar移动到hdfs的/spark/hive-jars目录下
- 报错4
hive> show databases;
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
- 解决方案
mysql:mysql -uroot -p (123456)
use hive;
select * from version;
update VERSION set SCHEMA_VERSION='2.3.0' where VER_ID=1;
- 报错5
[root@slave1 ~]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/software/hive-2.3.9/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/software/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/software/hive-2.3.9/lib/hive-common-2.3.9.jar!/hive-log4j2.properties Async: true
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/root/c0c31a72-0b80-48d5-9982-7aedd000b873. Name node is in safe mode.
The reported blocks 340 needs additional 11 blocks to reach the threshold 0.9990 of total blocks 352.
The number of live datanodes 2 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached. NamenodeHostName:slave1
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.newSafemodeException(FSNamesystem.java:1412)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1400)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2989)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1096)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:503)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:871)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:817)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1893)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2606)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:610)
at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:553)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:750)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:244)
at org.apache.hadoop.util.RunJar.main(RunJar.java:158)
- 解决方案
# 关闭安全模式
hdfs dfsadmin -safemode leave
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
 依赖报错 idea导入项目后依赖报错,解决方案:https://blog....
依赖报错 idea导入项目后依赖报错,解决方案:https://blog....
 错误1:gradle项目控制台输出为乱码 # 解决方案:https://bl...
错误1:gradle项目控制台输出为乱码 # 解决方案:https://bl...