问题描述
我需要将大小为4GB的数据集文件分解为小块。作为优化时间消耗的一部分,我想最大化并行处理。目前,我可以观察到cpu和GPU的内核正在被利用。请参见图像here中的附件输出。
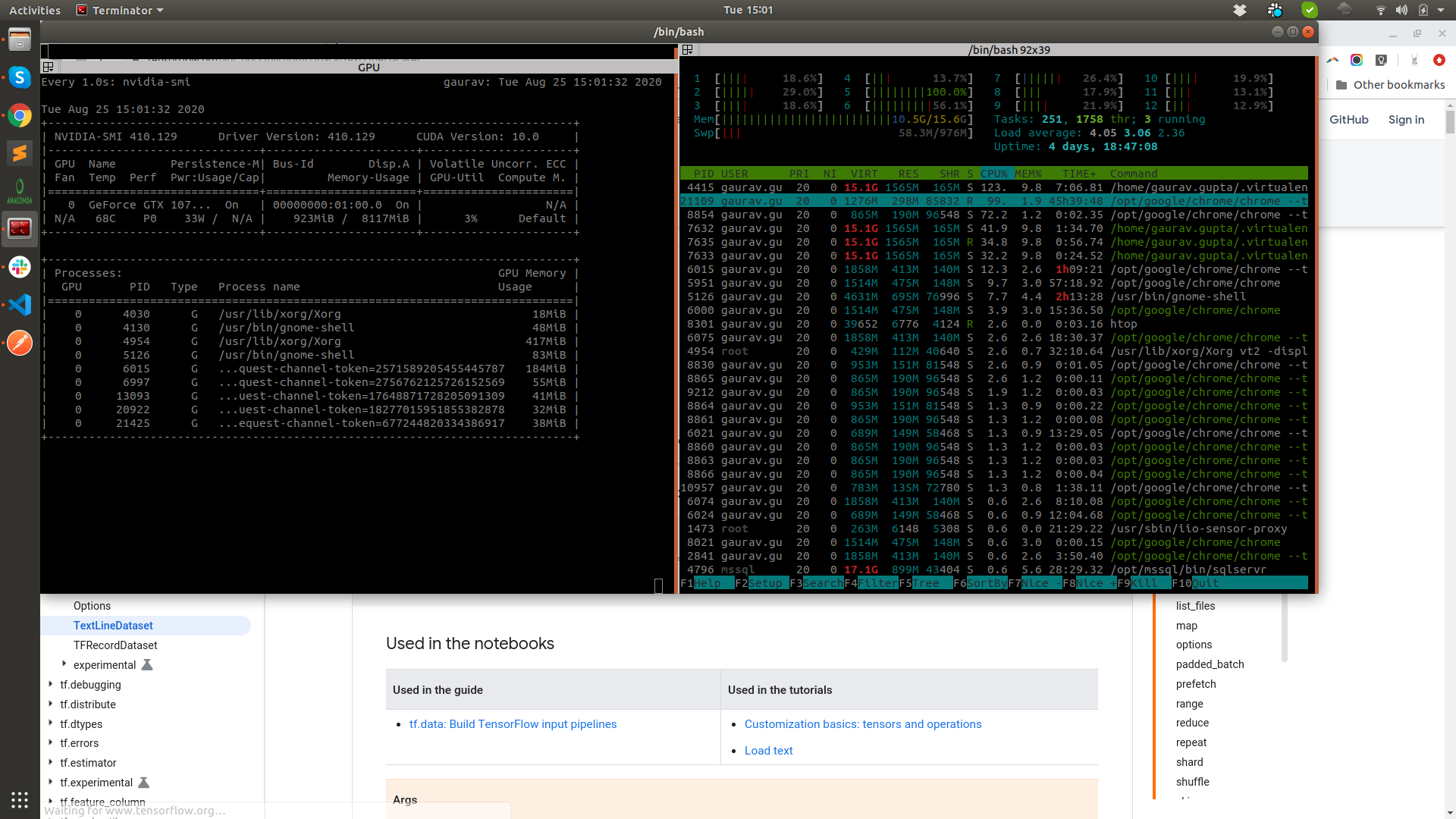{kind=link}
我的代码段如下所示
lmer记录展示执行流程的日志
library(lme4)
dat <- data.frame(id = sample(c("a","b","c"),100,replace=TRUE),y = rnorm(100),x = rnorm(100),w = rnorm(100),z = rnorm(100))
# this errors
for (i in c("x","w","z")) {
lmer(y ~ i + (1 | id),data=dat)
}
# this works
models <- list()
for (i in c("x","z")) {
f <- formula(paste("y~(1|id)+",i))
models[[i]] <- lmer(f,data=dat)
}
我尝试过def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value,type(tf.constant(0))):
value = value.numpy() # BytesList won't unpack a string from an EagerTensor.
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def serialize_row(text,rating):
# Create a dictionary mapping the feature name to the tf.Example-compatible data type.
feature = {
'text': _bytes_feature(text),'rating': _float_feature(rating),}
# Create a Features message using tf.train.Example.
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto.SerializetoString()
def transform(example):
str_example = example.decode("utf-8")
json_example = json.loads(str_example)
overall = json_example.get('overall',-99)
text = json_example.get('reviewText','')
if type(text) is str:
text = bytes(text,'utf-8')
tf_serialized_string = serialize_row(text,overall)
return tf_serialized_string
line_dataset = tf.data.TextLineDataset(filenames=[file_path])
line_dataset = line_dataset.map(lambda row: tf.numpy_function(transform,[row],tf.string))
line_dataset = line_dataset.shuffle(2)
line_dataset = line_dataset.batch(NUM_OF_RECORDS_PER_BATCH_FILE)
'''
Perform batchwise transformation of the population.
'''
start = time.time()
for idx,line in line_dataset.enumerate():
FILE_NAMES = 'test{0}.tfrecord'.format(idx)
end = time.time()
time_taken = end - start
tf.print('Processing for file - {0}'.format(FILE_NAMES))
DIRECTORY_URL = '/home/gaurav.gupta/projects/practice/'
filepath = os.path.join(DIRECTORY_URL,'data-set','electronics',FILE_NAMES)
batch_ds = tf.data.Dataset.from_tensor_slices(line)
writer = tf.data.experimental.TFRecordWriter(filepath)
writer.write(batch_ds)
tf.print('Processing for file - {0} took {1}'.format(FILE_NAMES,time_taken))
tf.print('Done')
参数,但看不出太大的区别。我相信在读取多个文件而不是单个大文件时会很方便。
我正在寻求您的建议,以并行执行此任务以减少时间消耗。
解决方法
我会尝试这样的事情(我喜欢使用joblib,因为它很容易放入现有代码中,您可能会与许多其他框架做类似的事情,此外,joblib不使用GPU也不使用它不使用任何JITting):
from joblib import Parallel,delayed
from tqdm import tqdm
...
def process_file(idx,line):
FILE_NAMES = 'test{0}.tfrecord'.format(idx)
end = time.time()
time_taken = end - start
tf.print('Processing for file - {0}'.format(FILE_NAMES))
DIRECTORY_URL = '/home/gaurav.gupta/projects/practice/'
filepath = os.path.join(DIRECTORY_URL,'data-set','electronics',FILE_NAMES)
batch_ds = tf.data.Dataset.from_tensor_slices(line)
writer = tf.data.experimental.TFRecordWriter(filepath)
writer.write(batch_ds)
#tf.print('Processing for file - {0} took {1}'.format(FILE_NAMES,time_taken))
return FILE_NAMES,time_taken
times = Parallel(n_jobs=12,prefer="processes")(delayed(process_file)(idx,line) for idx,line in tqdm(line_dataset.enumerate(),total=len(line_dataset)))
print('Done.')
这是未经测试的代码,我也不确定它将如何与tf代码一起使用,但是我会尝试一下。
tqdm完全没有必要,它只是我喜欢使用的东西,因为它提供了很好的进度条。