问题描述
Section 3.3.2描述了一个简单的基准,它演示了缓存对顺序读取的影响。该基准测试包括遵循一个(顺序排列的)循环链表,并测量每个节点花费的平均时间。节点结构如下:
struct l {
struct l *n;
long int pad[NPAD];
};
大小为N的工作集包含N/sizeof(l)个节点。有了足够的填充,每个指针将存储在不同的缓存行中,因此我们需要一个大小至少为64 * N/sizeof(l)的缓存来跟踪该周期,而无需进行昂贵的内存访问。
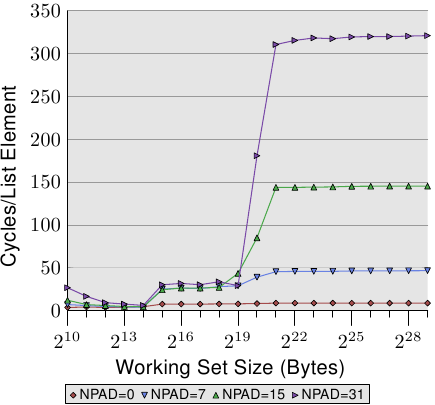
这是令我感到困惑的部分:假设64 * N/sizeof(l)恰好是最大缓存的大小。例如,如果我们通过更改填充将sizeof(l)减半,则N还需要小2倍,以便我们将所有内容都保留在缓存中。因此,以不同的步伐,我们应该以不同的工作集大小耗尽缓存。但是文字中的Figure 3.11(我没有足够的代表来嵌入图像)似乎与此矛盾-三种NPAD尺寸的访问时间突然跳到N=2^19。
{kind=link}
我想念什么?
起初我以为填充也可能会被缓存-但这不是对this question的答案所解释的那样。
解决方法
通过足够的填充,每个指针都存储在不同的缓存行中,因此我们需要一个大小至少为
64 * N/sizeof(l)的缓存来跟踪该周期,而无需进行昂贵的内存访问。
否,如果缓存行为64字节,并且sizeof(struct l)至少为64,则每个节点都位于不同的缓存行中。但这不是3.3.2节的重点。
假设
64 * N/sizeof(l)恰好是最大缓存的大小。例如,如果我们通过更改填充将sizeof(l)减半,那么如果我们希望所有内容都适合缓存,则N也需要小2倍。
缓存的大小将是固定的字节数,而不是诸如64 * N/sizeof(l)之类的计算。在本小节的部分中,Drepper使用1 MiB(2 20 字节)L2高速缓存。此外,Drepper在将“工作集大小”(显然是总数组大小,尽管在某些试验中并非所有数组都可以访问)描述为2 N 个字节的情况下使用N,因此“工作集”如果2 N 个字节小于或等于缓存大小,则适合缓存。如果数组大小为2 N 个字节,则元素数必须为2 N / sizeof(struct l)。
在图3.11中,您看到的是:
- 只要数组的总大小小于2 19 个字节,它的所有内容都适合L2缓存,并且访问是“快速的”。
- 在2 19 和2 20 字节处,整个数组本身将适合高速缓存,但是系统中还有其他东西也需要高速缓存,因此我们看到中间效果,在此不再详细讨论。
- 除了2 20 个字节以外,当数组元素都被连续访问时,它们不能保留在缓存中(即使使用较大的填充,实际访问的字节总数远小于缓存大小,即高速缓存关联性使得它们溢出其指定的高速缓存集,实际上与溢出所有高速缓存相同。
- 对于零填充,预取效果很好:硬件观察到连续读取内存,并预取缓存行。观察到,填充为零时,一个缓存行中可以容纳多个元素,因此每个缓存行的每次预取都可以提供几个元素,因此每个元素的时间很短。
- 对于较小的填充(大概每条缓存行只有一个元素),预取以相同的方式操作:硬件观察到内存正在连续读取,并预取缓存行。但是,每条缓存行只有一个数组元素,因此即使每条缓存行的时间相同,每个元素的时间也会更长。
- 对于中等填充和较大填充,预取操作不起作用或效果不佳。
我对Drepper的某些说法表示怀疑。例如,关于15和31 long int的填充之间的差异(显然将元素大小从128字节更改为256字节),他写道:
元素大小妨碍预取工作的原因是硬件预取的限制:它不能跨越页面边界。
但是,页面大小为4096字节(从其他地方提到的60个页面为245,760字节),元素间距为128到256字节,读取将分别仅遇到32和16个元素的页面边界。每个元素从大约145个周期跳到大约320个周期,因为每个元素还有一个额外的1/32页面转换(每16个元素1个减每32个元素1个=每个元素1/32)意味着1/32•C = 320− 145,其中C是页面转换所花费的周期数。那么C =(320-145)•32 = 5,600。如果没有更多针对性的测试或支持文档,我将不会相信这么大的数字。
Drepper还用括号斜体写:
是的,这有点不一致,因为在其他测试中,我们在元素大小中计算了结构的未使用部分,并且可以定义NPAD,以便每个元素填充一页。在这种情况下,工作集的大小将非常不同。不过,这并不是该测试的重点,而且由于预取仍然无效,因此差异不大。
这与他先前对工作集的描述不符,他说工作集2 N 个字节包含2 N / sizeof(struct l)个元素。后者显示他的“工作集”是整个数组,即使仅访问每个元素的一部分也是如此。前者说,工作集将根据每个元素的访问量而有所不同。
总的来说,我认为Drepper在描述和原因方面有些松懈。特别是在没有示例代码的情况下,很难遵循某些测试描述或复制它们。假定的各种大小的数组元素建模实际上是跳过内存访问仅访问部分的建模-如果那些是程序正在使用的实际数组元素,它将加载整个元素,并且预取将很好地使用每个字节。一旦理解了这种令人困惑的描述,这不会使Drepper的测量无效,但这是一种误导性描述。同样,在不同地方对“工作集”的差异描述也令人困惑。
因此,我的建议是花一点儿心思,不要期望它成为缓存和内存性能的完整而清晰的规范。