Regular expressions are used to search and manipulate the text,based on the patterns. Most of the Linux commands and programming languages use regular expression.
Grep command is used to search for a specific string in a file. Please refer our earlier article for .
You can also use regular expressions with grep command when you want to search for a text containing a particular pattern. Regular expressions search for the patterns on each line of the file. It simplifies our search operation.This articles is part of a 2 article series.
This part 1 article covers grep examples for simple regular expressions. The future part 2 article will cover advanced regular expression examples in grep.
Let us take the file /var/log/messages file which will be used in our examples.
Example 1. Beginning of line ( ^ )
In grep command,caret Symbol ^ matches the expression at the start of a line. In the following example,it displays all the line which starts with the Nov 10. i.e All the messages logged on November 10.
$ grep "^Nov 10" messages.1 Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0),stratum 10 Nov 10 01:18:49 gs123 ntpd[2241]: synchronized to 15.1.13.13,stratum 3 Nov 10 13:21:26 gs123 ntpd[2241]: time reset +0.146664 s Nov 10 13:25:46 gs123 ntpd[2241]: synchronized to LOCAL(0),stratum 10 Nov 10 13:26:27 gs123 ntpd[2241]: synchronized to 15.1.13.13,stratum 3
The ^ matches the expression in the beginning of a line,only if it is the first character in a regular expression. ^N matches line beginning with N.
Example 2. End of the line ( $)
Character $ matches the expression at the end of a line. The following command will help you to get all the lines which ends with the word “terminating”.
$ grep "terminating.$" messages Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating. Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
From the above output you can come to know when all the kernel log has got terminated. Just like ^ matches the beginning of the line only if it is the first character,$ matches the end of the line only if it is the last character in a regular expression.
Example 3. Count of empty lines ( ^$ )
Using ^ and $ character you can find out the empty lines available in a file. “^$” specifies empty line.
$ grep -c "^$" messages anaconda.log messages:0 anaconda.log:3
The above commands displays the count of the empty lines available in the messages and anaconda.log files.
Example 4. Single Character (.)
The special meta-character “.” (dot) matches any character except the end of the line character. Let us take the input file which has the content as follows.
$ cat input 1. first line 2. hi hello 3. hi zello how are you 4. cello 5. aello 6. eello 7. last line
Now let us search for a word which has any single character followed by ello. i.e hello,cello etc.,
$ grep ".ello" input 2. hi hello 3. hi zello how are you 4. cello 5. aello 6. eello
In case if you want to search for a word which has only 4 character you can give grep -w “….” where single dot represents any single character.
Example 5. Zero or more occurrence (*)
The special character “*” matches zero or more occurrence of the previous character. For example,the pattern ’1*’ matches zero or more ’1′.
The following example searches for a pattern “kernel: *” i.e kernel: and zero or more occurrence of space character.
$ grep "kernel: *." * messages.4:Jul 12 17:01:02 cloneme kernel: ACPI: PCI interrupt for device 0000:00:11.0 disabled messages.4:Oct 28 06:29:49 cloneme kernel: ACPI: PM-Timer IO Port: 0x1008 messages.4:Oct 28 06:31:06 btovm871 kernel: sda: sda1 sda2 sda3 messages.4:Oct 28 06:31:06 btovm871 kernel: sd 0:0:0:0: Attached scsi disk sda . .
In the above example it matches for kernel and colon symbol followed by any number of spaces/no space and “.” matches any single character.
Example 6. One or more occurrence (\+)
The special character “\+” matches one or more occurrence of the previous character. ” \+” matches at least one or more space character.
If there is no space then it will not match. The character “+” comes under extended regular expression. So you have to escape when you want to use it with the grep command.
$ cat input hi hello hi hello how are you hihello$ grep "hi +hello" input
hi hello
hi hello how are you
In the above example,the grep pattern matches for the pattern ‘hi’,followed by one or more space character,followed by “hello”.
If there is no space between hi and hello it wont match that. However,* character matches zero or more occurrence.
“hihello” will be matched by * as shown below.
$ grep "hi *hello" input hi hello hi hello how are you hihello $
Example 7. Zero or one occurrence (\?)
The special character “?” matches zero or one occurrence of the previous character. “0?” matches single zero or nothing.
$ grep "hi \?hello" input hi hello hihello
“hi \?hello” matches hi and hello with single space (hi hello) and no space (hihello).
The line which has more than one space between hi and hello did not get matched in the above command.
Example 8.Escaping the special character (\)
If you want to search for special characters (for example: *,dot) in the content you have to escape the special character in the regular expression.
$ grep "127\.0\.0\.1" /var/log/messages.4 Oct 28 06:31:10 btovm871 ntpd[2241]: Listening on interface lo,127.0.0.1#123 Enabled
Example 9. Character Class ([0-9])
The character class is nothing but list of characters mentioned with in the square bracket which is used to match only one out of several characters.
$ grep -B 1 "[0123456789]\+ times" /var/log/messages.4 Oct 28 06:38:35 btovm871 init: open(/dev/pts/0): No such file or directory Oct 28 06:38:35 btovm871 last message repeated 2 times Oct 28 06:38:38 btovm871 pcscd: winscard.c:304:SCardConnect() Reader E-Gate 0 0 Not Found Oct 28 06:38:38 btovm871 last message repeated 3 times
Repeated messages will be logged in messages logfile as “last message repeated n times”. The above example searches for the line which has any number (0to9) followed by the word “times”. If it matches it displays the line before the matched line and matched line also.
With in the square bracket,using hyphen you can specify the range of characters. Like [0123456789] can be represented by [0-9]. Alphabets range also can be specified such as [a-z],[A-Z] etc. So the above command can also be written as
$ grep -B 1 "[0-9]\+ times" /var/log/messages.4
Example 10. Exception in the character class
If you want to search for all the characters except those in the square bracket,then use ^ (Caret) symbol as the first character after open square bracket. The following example searches for a line which does not start with the vowel letter from dictionary word file in linux.
$ grep -i "^[^aeiou]" /usr/share/dict/linux.words 1080 10-point 10th 11-point 12-point 16-point 18-point 1st 2
First caret symbol in regular expression represents beginning of the line. However,caret symbol inside the square bracket represents “except” — i.e match except everything in the square bracket.
http://www.thegeekstuff.com/2011/01/regular-expressions-in-grep-command/
| 说明 |
|---|
 根据官网 入门 express
根据官网 入门 express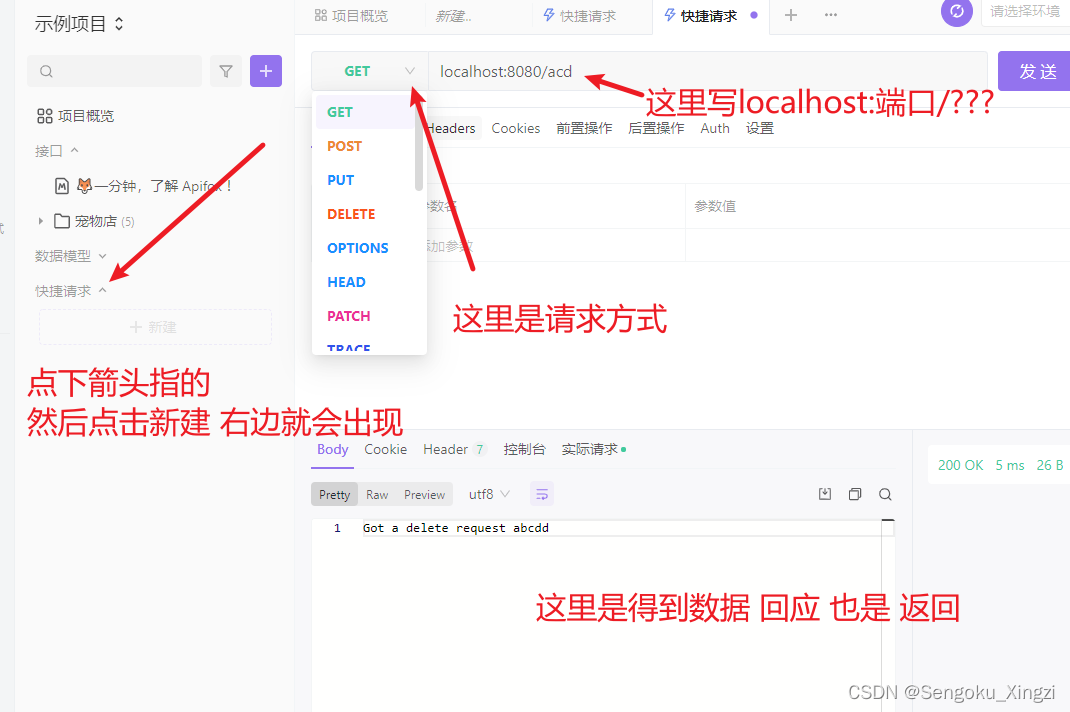 java叫接口control什么的app.get.post等等都是请求方式我们可...
java叫接口control什么的app.get.post等等都是请求方式我们可... 为了前端丢进去的时候可以直接判断中间件就是经过了这个就会...
为了前端丢进去的时候可以直接判断中间件就是经过了这个就会...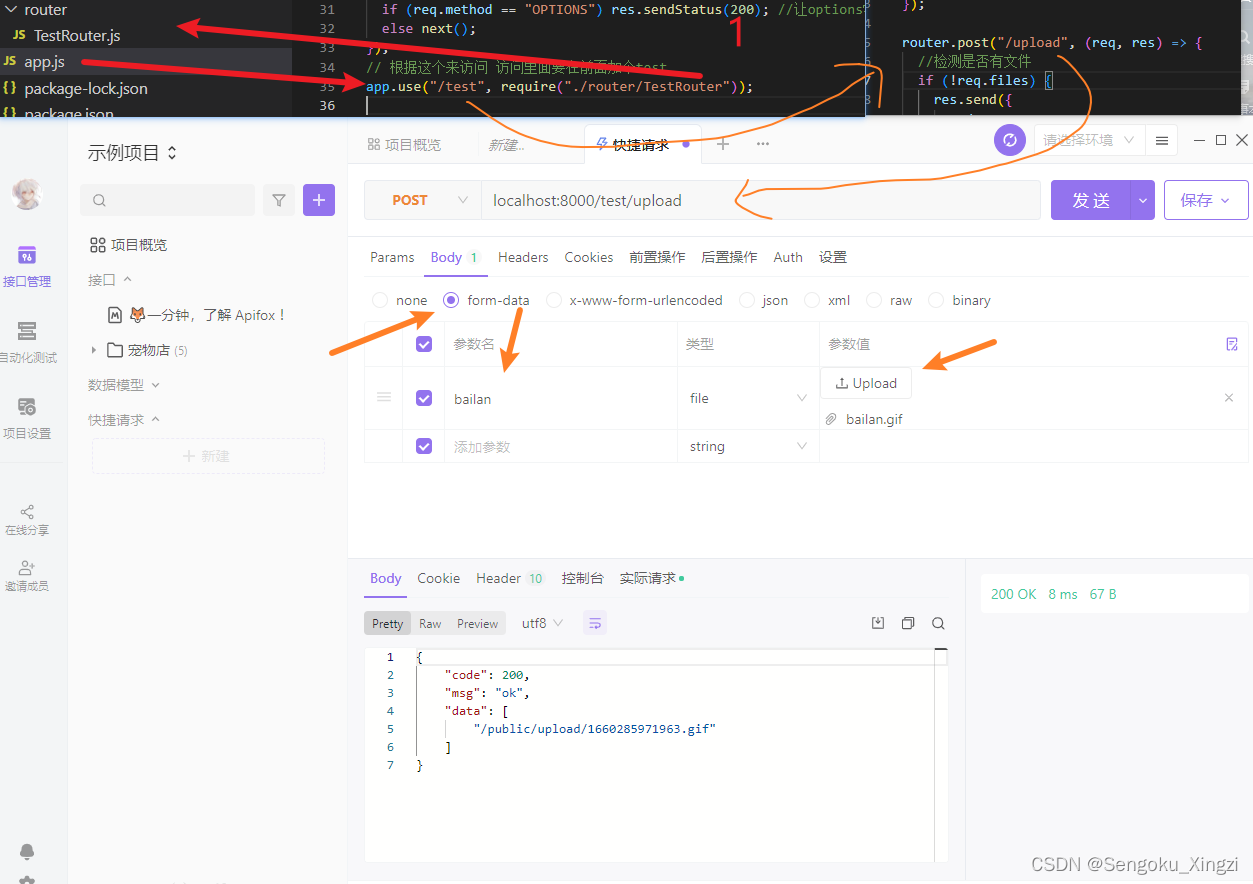 Express 文件的上传和下载
Express 文件的上传和下载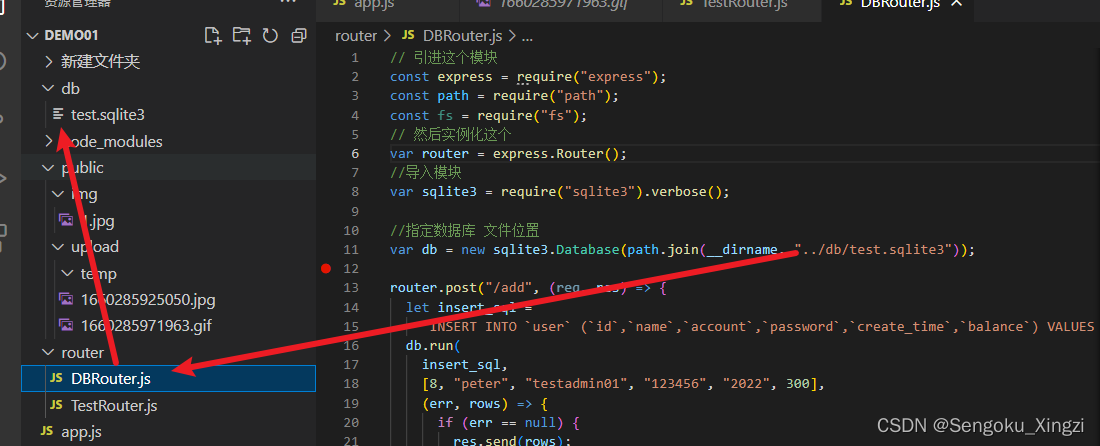 运行命令下载app.js 增加中间件。
运行命令下载app.js 增加中间件。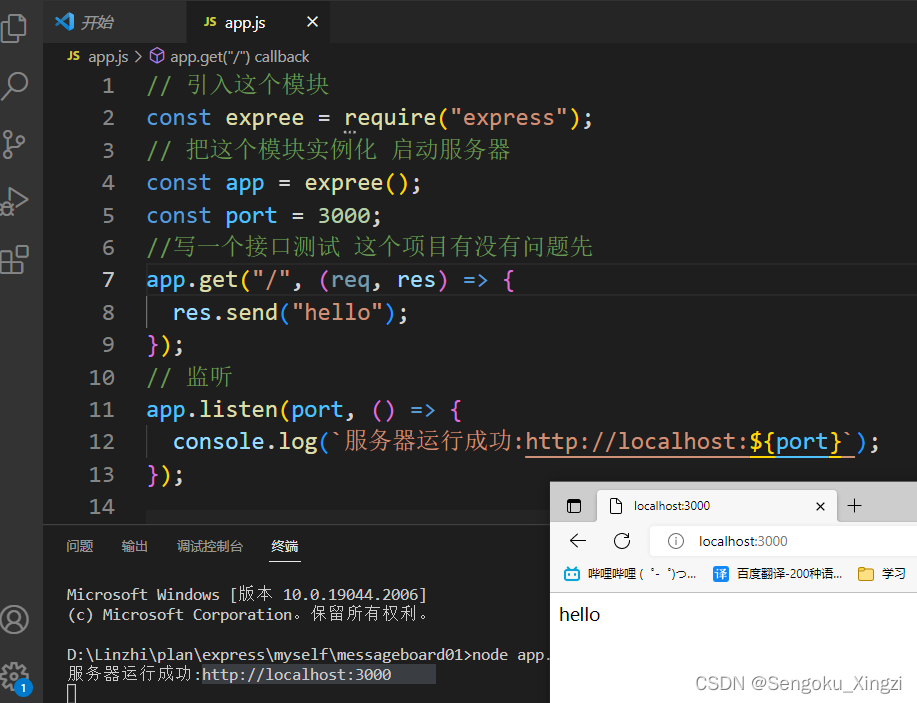 基本模板来的 后面用后就有什么加什么都行。
基本模板来的 后面用后就有什么加什么都行。