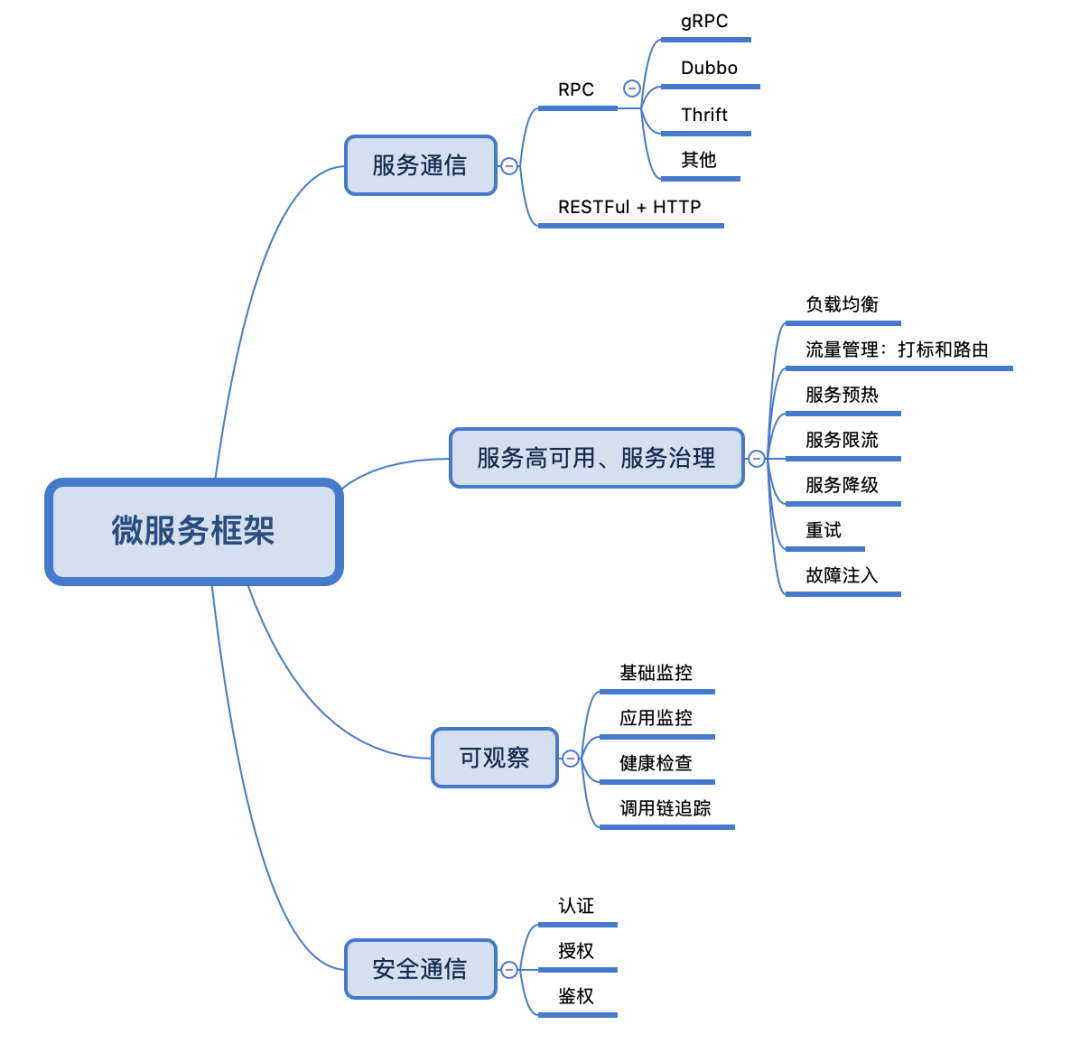
dubbo常见的两种注册中心
dubbo目前支持了zookeeper、redis、consul、etcd3、eureka等注册中心,我这里主要讲下常见的两种注册中心redis,zookeeper
Redis注册中心
使用redis作为注册中心,主要使用到了其map数据结构和发布/订阅特性
-
调用过程
- 服务提供方启动时,向 Key:/dubbo/com.lezai.userService/providers 下,添加当前提供者的地址
- 并向 Channel:/dubbo/com.lezai.userService/providers 发送 register 事件
- 服务消费方启动时,从 Channel:/dubbo/com.lezai.userService/providers 订阅 register 和 unregister 事件
- 并向 Key:/dubbo/com.lezai.userService/providers 下,添加当前消费者的地址
- 服务消费方收到 register 和 unregister 事件后,从 Key:/dubbo/com.lezai.userService/providers 下获取提供者地址列表
- 服务监控中心启动时,从 Channel:/dubbo/* 订阅 register 和 unregister,以及 subscribe和unsubsribe事件
- 服务监控中心收到 register 和 unregister 事件后,从 Key:/dubbo/com.foo.BarService/providers下获取提供者地址列表
- 服务监控中心收到 subscribe 和 unsubsribe 事件后,从 Key:/dubbo/com.lezai.userService/consumers 下获取消费者地址列表
-
当服务提供者突然宕机,状态能立即变更么?
dubboe在注册中心、消费者和提供者之间建立了心跳机制,每隔30秒更新一次有效期
zookeeper注册中心
相对于redis做注册中心,zookeeper就更加灵活了,通过使用zookeeper的watch机制、临时节点特性、树结构能完成所有功能,我们先看下,dubbo在zookeeper中创建的节点分布图:

-
服务提供者(provider)
在初始化启动时,会在zookeeper中的dubbo节点下的服务节点下(com.lezau.UserServie)的providers节点下创建一个子节点并且写入自己的URL地址,路径(目录)为/dubbo/com.lezau.UserServie/providers/,该路径(目录)下的子节点均为服务提供者。此时这些节点均为临时节点,因为临时节点的生命周期和客户端会话相关,所以一旦服务提供者所在的机器出现故障导致无法提供服务时,该临时节点就会从zookeeper中删除。 -
服务消费者(consumer)
初始化启动时,会订阅/dubbo/com.lezau.UserServie/providers/路径(目录)下的提供者的URL地址,并在/dubbo/com.lezau.UserServie/consumers/路径(目录)下创建临时子节点并且写入自己的URL地址,该路径(目录)下的子节点均为服务消费者。 -
注册中心
由于服务提供者、消费者、注册中心之间是长连接,注册中心能感知服务提供者宕机,会通知消费者。因为监控中心是dubbo服务治理体系中重要的一部分,它需要知道服务提供者和消费者的所有情况变化情况,所以它在启动时会在路径(目录)为/dubbo/com.lezau.UserServie/的服务节点上(com.lezau.UserServie)注册一个watcher来监听子节点的变化,即订阅/dubbo/com.lezau.UserServie/路径(目录)下的所有提供者和消费者URL地址,因此它也能感知到服务提供者的宕机。 -
特性
dubbo中的zookeeper还有个特性就是zookeeper的节点结构设计,它以服务名和类型,也就是dubbo/com.lezau.UserServie/类型 作为节点路径(目录),符合dubbo的订阅和通知的需求,保证了以服务为粒度的变更通知,通知范围易于控制,所以即使服务提供者和消费者频繁变,对zookeeper的性能也不会造成多大的影响。
调用模块支持的负载均衡算法
dubbo支持的均衡算法有随机、轮询、最少活跃调用度、一致性hash,这里主要讲下其中两种算随机和一致性hash,这也是面试过程中必问的两大算法:
随机
定义:按权重设置随机概率,dubbo默认使用这种算法
实现思想:
如果一组服务提供者的权重分别为1,10,6,那么我如何能保证第二台机器命中概率最大呢?

何为一致性hash?
- 一致性hash解决了什么问题?
- 数据聚集(使数据分散开来)
- 对机器的扩容或宕机提供了较好的处理机制,防止全部重新进行hash
- 一致性hash算法的原理

- 首先设定2^31 个节点
- 然后对所有机器的标识进行hash然后对2^31 进行取模,得到每个机器在这2^31 个节点的位置
- 用户发起请求,会根据请求的标识进行hash,同样对2^31 个节点数进行取模,然后得到一个位置
- 再从这个位置顺时针进行查找,将找到的第一个机器节点作为命中点,将会使用该机器进行处理
- 如上图,请求将会交给NodeA处理

- 如果这个时候新增了机器或者机器宕机了,将只会影响到一部分的数据,如上图,请求将会交给NodeB处理。只会影响D和A节点的请求
总结:以上方法解决了由于机器宕机或新加入机器产生的全局hash的问题
这时你也许会产生这样的疑问,如果我的机器很少,但是2^31 的节点又那么多,会不会导致好多数据都会落在同一个节点上呢,这也就是数据倾斜的问题,面试必问的,我们看下作者是如何解决这个问题的:
- 如何解决数据倾斜的问题:
调用模块支持的容错策略
- 失败自动切换:调用失败后基于retries=“2”属性重试其它服务器,默认容错策略
- 快速失败:快速失败,只发起一次调用,失败立即报错。
- 忽略失败:失败后忽略,不抛出异常给客户端。
- 失败重试:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作
- 并行调用:只要一个成功即返回,并行调用指定数量机器,可通过forks="2"来设置最大并行数。
- 广播调用:广播调用所有提供者,逐个调用,任意一台报错则报错
dubbo如何防止服务链接被盗用?
消费者每次调用服务端的时候都会从zookeeper中拿到目标服务的地址链接:dubbo://xxx
然后直接去调用目标服务,如果被非法用户拿到这个地址那么不就可以直接调用了么,那么如何避免链接被盗用呢?
dubbo中提供了token机制,用来保护链接被盗用:

dubbo的泛化提供与引用知道使用来干嘛的么?
有很多同学在面试过程中被问到什么是泛化,很多同学第一感觉以为是在问泛型吧!
- 泛化提供
泛化提供试用在服务提供方的,是指不通过接口的方式直接将服务暴露出去。通常用于Mock框架或服务降级框架实现。代码中可以使用GenericService注入 - 泛化引用
通常用在消费端, 是指不通过常规接口的方式去引用服务,通常用于测试框架,消费端不用去依赖服务端提供的接口,自己直接使用全类名进行调用
//弱类型接口名
reference.setInterface("com.tuling.teach.service.DemoService");
//声明为泛化接口
reference.setGeneric(true);
如何实现dubbo调用链追踪?
在dubbo提供了隐式参数来实现调用链追踪的需求,该参数式可以从消费端传递到服务端的,存在于整个调用链中,设置和获取方法如下:
RpcContext.getContext().setAttachment("index","1");
//隐式传参,后面的远程
Stringindex=RpcContext.getContext().getAttachment("index");
因为在dubbo调用过程中,dubbo会维护一个rpc本地线程map来存储这些参数,
但是如果你不是直接调用目标服务,而是中间多了一个服务,然后由这个服务去调用目标服务,这个时候目标服务是拿不到这个参数,例如:
A 设置了一个参数,然后调用C,然后C再去调用B,这样B是拿不到这个参数的,C能拿到。
dubbo调用过程的链路

微信搜一搜【乐哉开讲】关注帅气的我,回复【干货领取】,将会有大量面试资料和架构师必看书籍等你挑选,包括java基础、java并发、微服务、中间件等更多资料等你来取哦。