#1、导入第三方库
import requests
import json
from bs4 import BeautifulSoup
import re
import time
import os
import pandas as pd
import random
#2、获取网页内容
def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
}
try:
r = requests.get(url,headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
#3、解析网页内容
def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
soup = BeautifulSoup(html,"html.parser")
tbodys = soup.find_all('tbody')
data = []
for i in range(1,len(tbodys)):
comment = tbodys[i]
ci = comment.cite.a['href']
tmp = comment.find(onclick="atarget(this)")
title = tmp.string
uid = re.findall(r"(\d+)",ci)[0]
tid = re.findall(r"(\d+)",tmp['href'])[0]
co = {
'tid':tid,
'title':title,
'uid':uid
}
data.append(co)
return pd.DataFrame(data)
#4、存储爬取信息
def save_file(data_df):
# columns = ['帖子id','标题','用户id']
#if os.path.exists('discuz社区.txt'):
#存在则追加,不写入表头
# excel能够正确识别用gb2312、gbk、gb18030或utf_8_sig编码的中文,utf-8可能出现乱码
data_df.to_csv('/root/discuz_result.txt', mode='a',encoding='utf_8_sig',header = False,index=False) #,columns=columns,
#不存在,则直接写入,带表头
#else:
# 加上参数mode='a'也可以
#data_df.to_csv('discuz社区.txt',encoding='utf_8_sig', index=False)#columns=columns
print("保存成功!")
#5、主函数
if __name__ == '__main__':
for i in range(1,20):
url = 'https://www.discuz.net/forum-developer-{}.html'.format(i)
html = fetchURL(url)
data = parserHtml(html)
#将一页爬取的数据存储到MongoDB
save_file(data)
time.sleep(random.randint(1,3))
print("数据保存成功!")
#6、将数据存入数据库
create database hive_db;
create table crawl_discuz(tid int,title string,uid int)row format delimited fields terminated by ',';
load data local inpath '/root/discuz_result.txt' into table crawl_discuz;
 **本资源可免费获取,请至尾部读阅!**Discuz素材资源交易论...
**本资源可免费获取,请至尾部读阅!**Discuz素材资源交易论... 分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风...
分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风...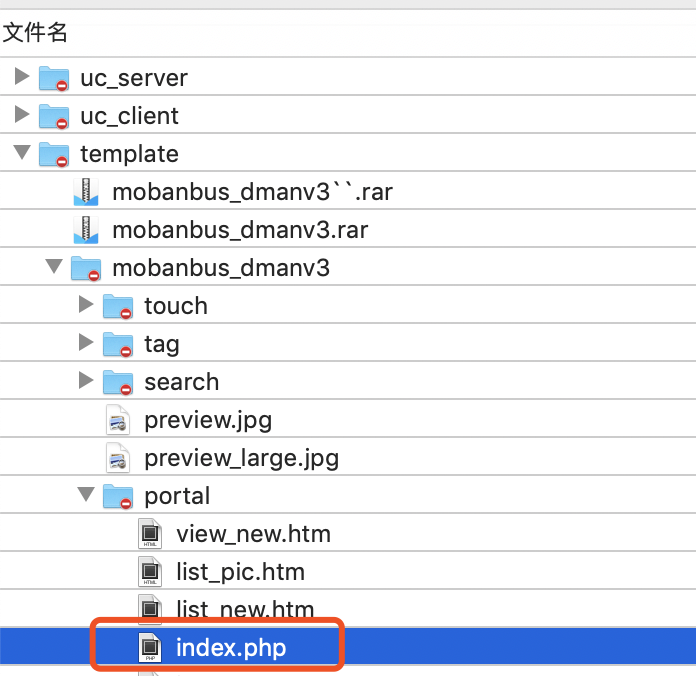 1.找到图片路径拼装文件首先打开根目录下的template目录找到...
1.找到图片路径拼装文件首先打开根目录下的template目录找到...